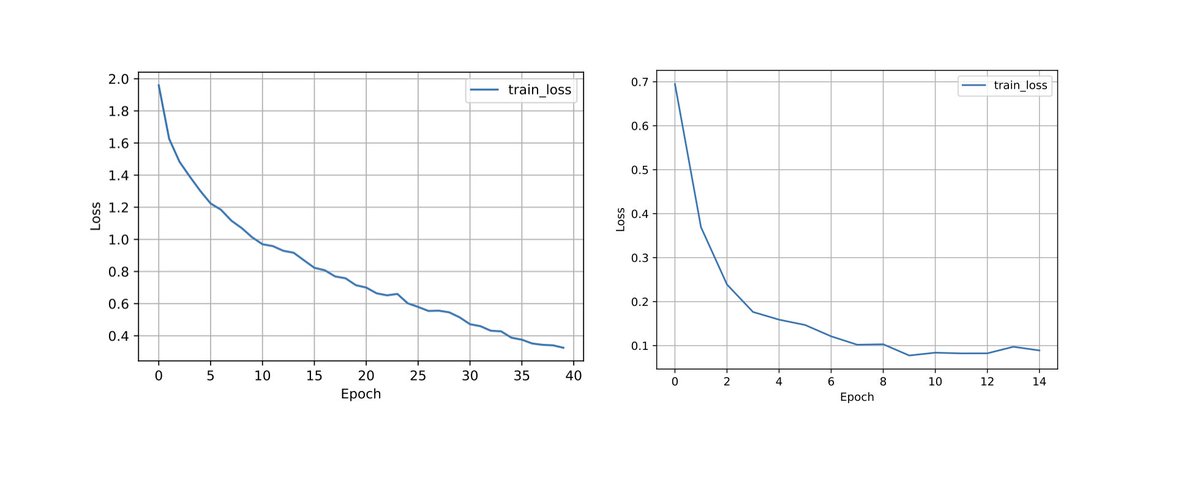
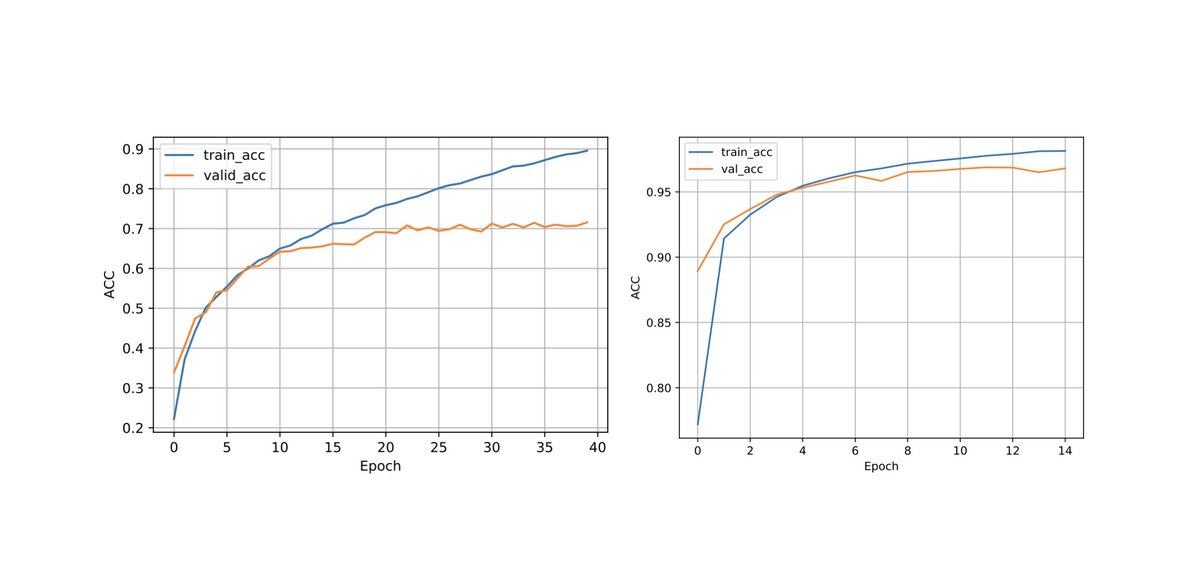
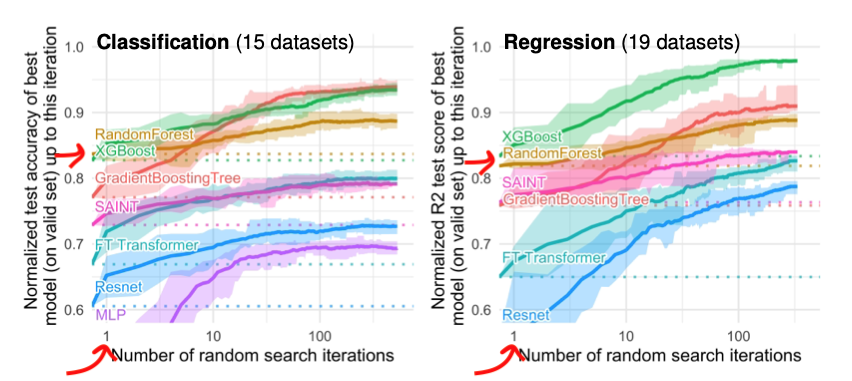
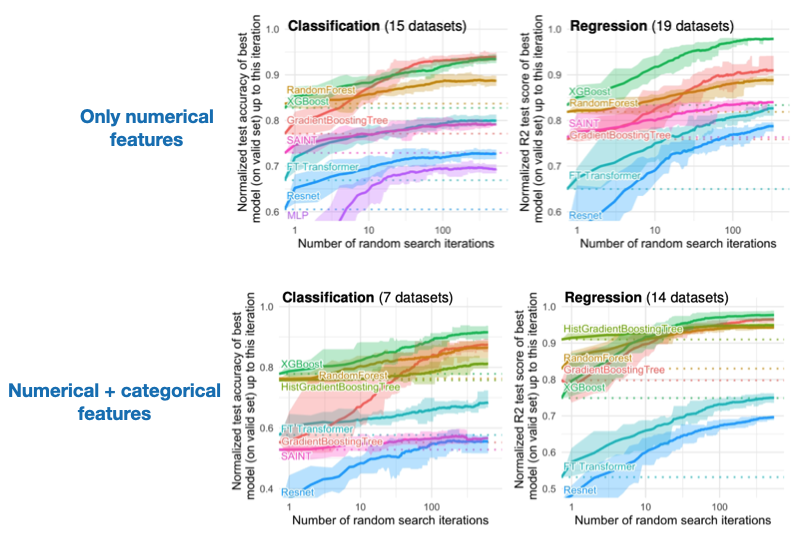
Some techniques for optimizing inference speeds (without changing the model architecture):
(1) Parallelization
(2) Vectorization
(3) Loop tiling
(4) Operator fusion
(5) Quantization
Anything missing?
[1/6]
(1) Parallelization
(2) Vectorization
(3) Loop tiling
(4) Operator fusion
(5) Quantization
Anything missing?
[1/6]
[2/6] (1) Parallelization (in an inference context) essentially means splitting the batches you want to predict on into chunks; the chunks are then processed in parallel. PyTorch has a nice tutorial on that here: pytorch.org/tutorials/inte… 

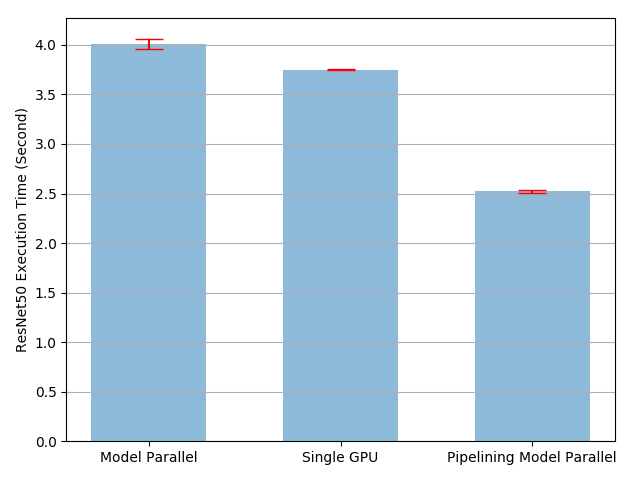
[3/6] (2) Vectorization is a classic that probably doesn't need much explanation. In a nutshell this involves replacing costly for-loops with ops that apply the same operations to multiple elements. You probably already do that automatically if you are using linalg/a DL framework

[4/6] (3) Loop tiling. I actually only just learned about this recently (thx to #MLSystemsBook). Something that is still slightly above my head 🤯: essentially, you change the data accessing order in a loop to leverage the hardware's memory layout & cache en.wikipedia.org/wiki/Loop_nest…

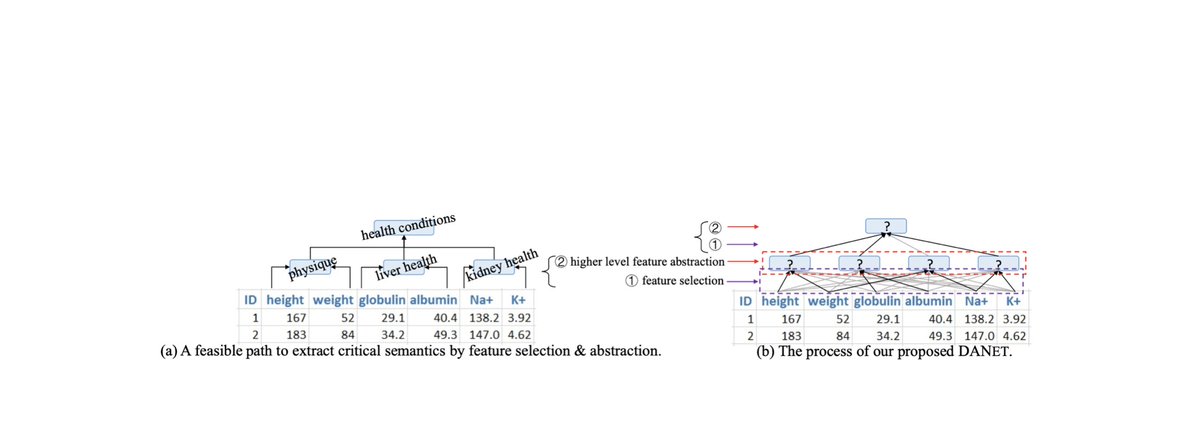
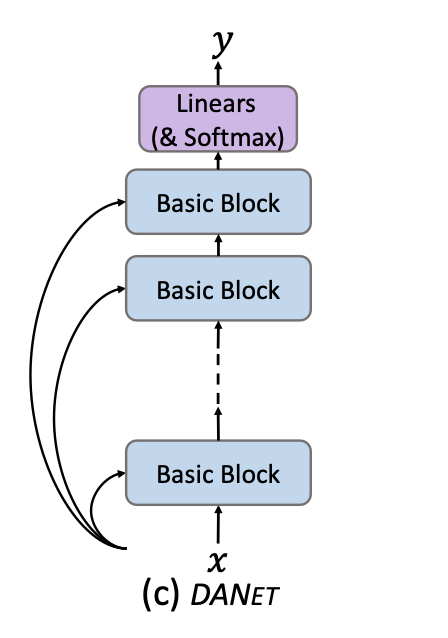
[5/6] (4) Operator fusion: here, if you have multiple loops, you try to merge those into one. (A classic example is calculating the mean and standard deviation in one pass).
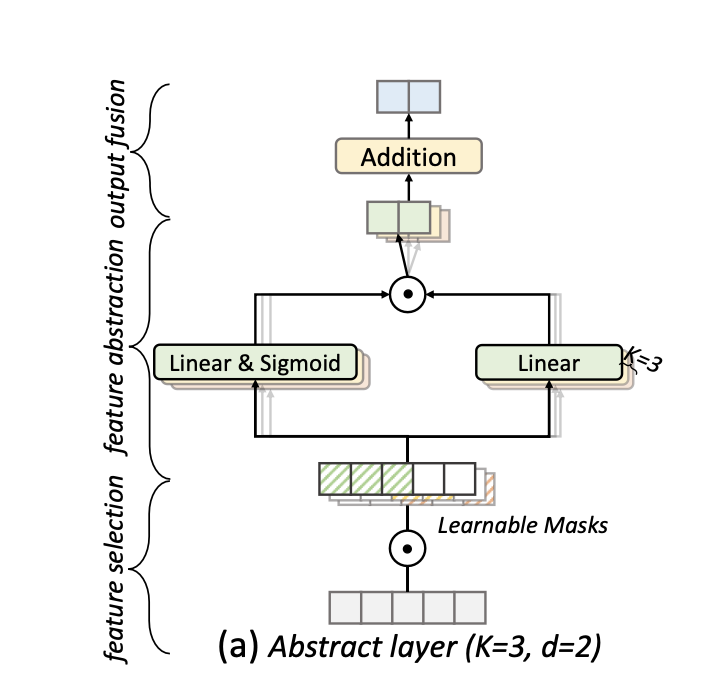
There was another nice example in the DANets paper I recently posted about (arxiv.org/abs/2112.02962):
There was another nice example in the DANets paper I recently posted about (arxiv.org/abs/2112.02962):

[6/6] (5) Quantization essentially reduces the precision (and typically casts floats->ints) to speed up computation & lowering memory requirements (while maintaining accuracy). Borderline-included it as it can reduce the accuracy of your model. Tutorial: pytorch.org/tutorials/reci…
• • •
Missing some Tweet in this thread? You can try to
force a refresh