Expected Threat (xT) is one of the most important (but least well-understood) statistics in football. ⚽️⚽️
It was used by Liverpool (they call it Goals Added) to do some of their best scouting. 📈
And now, YOU can learn all about it...🧵
It was used by Liverpool (they call it Goals Added) to do some of their best scouting. 📈
And now, YOU can learn all about it...🧵
The basic idea of xT is to assign a value to a position on the pitch or an action based on the probability it will lead to a goal. 

It was proposed (ten years ago) by @srudd_ok who had the idea of using Markov chains to measure how much different parts of the pitch are worth.

This was a mathematically elegant solution and in this video I explain how xT (or probability of a goal) can be calculated step by step.
The name Expected Threat (xT) came form @karun1710, who also described how it works in this amazing interactive blog post. karun.in/blog/expected-…
Lots of different names --- EPV, OBV, G+, VAEP etc. --- have been given to the xT approach.
I distinguish between position-based xT (where place on the pitch is assigned value) and action-based xT (where passes, dribbles etc. are assigned value).
soccermatics.readthedocs.io/en/latest/less…
I distinguish between position-based xT (where place on the pitch is assigned value) and action-based xT (where passes, dribbles etc. are assigned value).
soccermatics.readthedocs.io/en/latest/less…
I start by explaining the position-based version of xT. By measuring transitions between different parts of the pitch and the probability of scoring from them, we can iteratively value different places on the pitch.
Then I turn to action-based xT, which better captures the dynamic nature of football.
We can assign value, not just to position, but also how we move between positions.
We can assign value, not just to position, but also how we move between positions.

The action-based version of xT has not been presented in so much detail before, although it is better for professional applications.
I try to put this right in this video...
I try to put this right in this video...
And @aleksander_and has done a wonderful step-by-step implementation here. soccermatics.readthedocs.io/en/latest/gall…
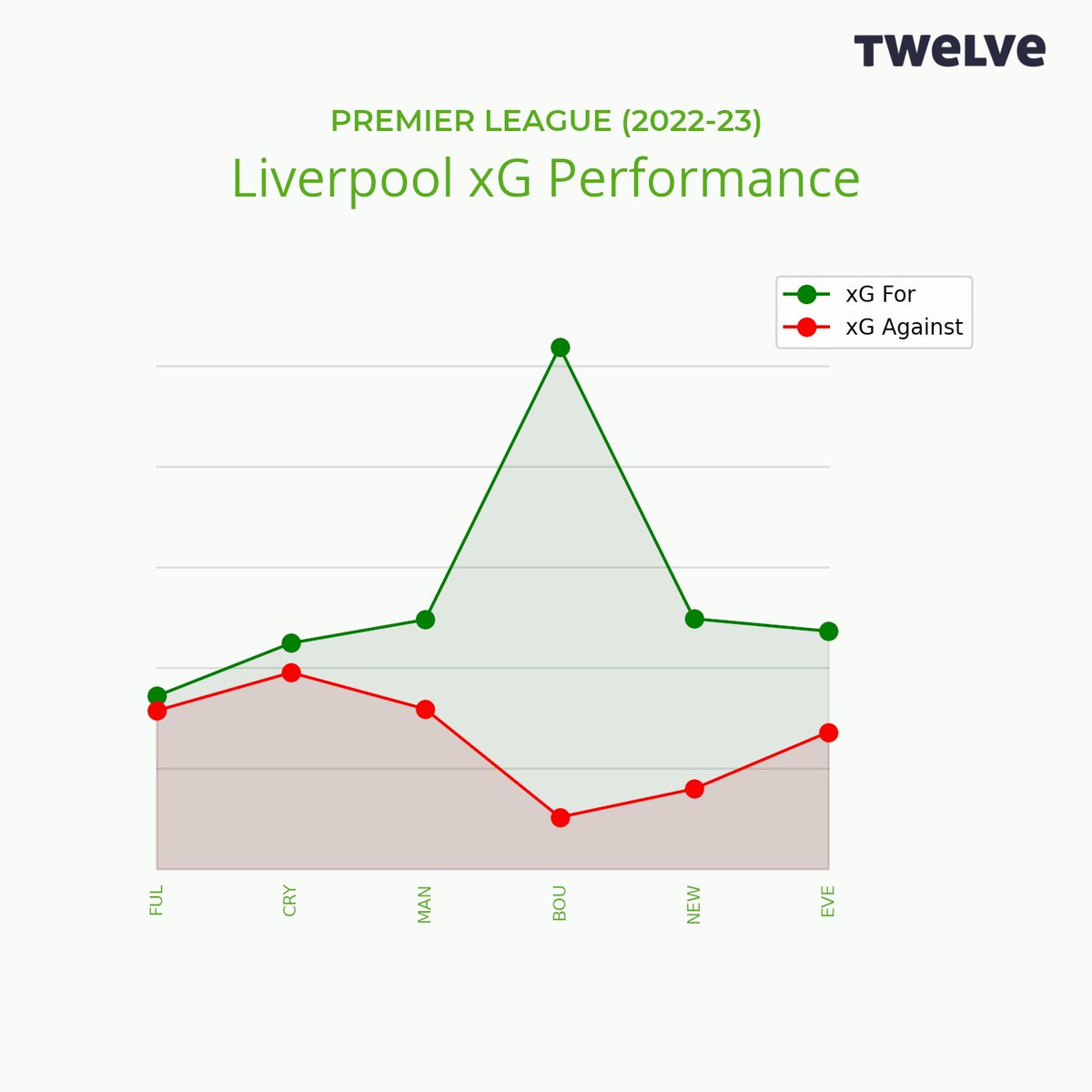
And I use the @twelve_football implementation of action-based xT to give application examples in this video.
I hope learning about xT is as much fun as it has been to write and make videos about.
And that you can make your own version🤗🤗
Enjoy!
And that you can make your own version🤗🤗
Enjoy!
• • •
Missing some Tweet in this thread? You can try to
force a refresh