
Excited to share our #NeurIPS2022 @NVIDIAAI work GET3D, a generative model that directly produces explicit textured 3D meshes with complex topology, rich geometric details, and high fidelity textures. #3D
Project page: nv-tlabs.github.io/GET3D/
Project page: nv-tlabs.github.io/GET3D/
Our method builds on the success in differentiable surface modeling (nv-tlabs.github.io/DMTet/), differentiable rendering (nvlabs.github.io/nvdiffrec/ ) and 2D GANs, allowing it to learn 3D from 2D image collections. 
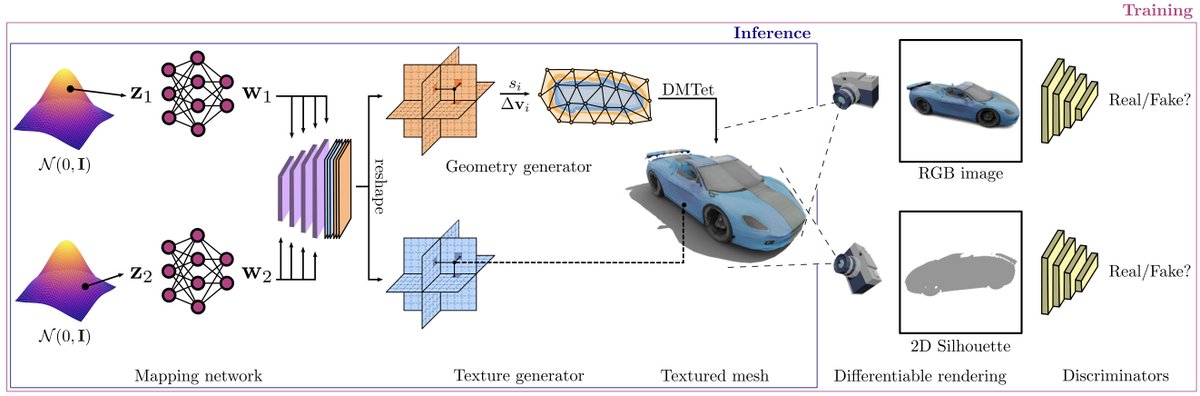
GET3D can populate a crowd of objects with diversity in geometry and texture, including: 1 Lights & wheels for the cars; 2 Mirrors & tires for the motorbike, 3 Mouth, ears & horns for the animals; 4 Wheels on the legs of the chairs; 5 Shoes & cloths for humans, etc
GET3D is able to disentangle geometry and texture, enabling better control for 3D generation. Each row shows shapes generated with the same geometry code and different texture codes, while each column shows shapes generated with the same texture code and different geometry codes
GET3D is able to generate a smooth transition between different shapes across all categories. In each figure, we perform a random walk in the latent space and generate corresponding 3D shapes. This opens up a possibility to generate diverse high-quality 3D meshes with textures.
GET3D also supports generating materials. When combined with DIBR++ (nv-tlabs.github.io/DIBRPlus/) for differentiable rendering, GET3D is able to generate materials and produce meaningful view-dependent lighting effects in a completely unsupervised manner.
We can even use text to control the 3D generation! Following StyleGAN-NADA we can take the user-provided text and finetune our 3D generator using CLIP embedding. GET3D generates a large number of meaningful shapes from text prompts.
When locally perturbing the latent codes, GET3D is able to generate similar-looking shapes with local differences, allowing the users to pick the object they prefer.
This is a joint work w/ @TianchangS @zianwang97 @ChenWenzheng @kangxue_yin @lidaiqing @orlitany @ZGojcic @FidlerSanja Huge thanks to all the co-authors and @nvidia @NVIDIAAI !!!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



