
Il y a 4 jours, une équipe de 5 personnes dont 3 ont décidé de rester anonymes ont présenté une vidéo intitulée "Des stats, du graphique et du DRAMA!" se présentant comme 'un travail d'enquête sur le collectif Zet-Ethique et Metacritique et ses échanges avec la sphère ZET".
La vidéo mettant en notre réputation en jeu, il nous semble important de l'étudier et de fournir nos propres interprétations des données présentées, chacun pourra ensuite se faire un avis éclairé via la confrontation des interprétations. Cependant, cela prendra un certain temps.
Or, comme on connait les dynamiques des réseaux sociaux : les démentis sont généralement plus lents et plus entravés pour faire leur chemin que les affirmations, et ce notamment s'ils arrivent longtemps après.
Nous allons donc fournir ici les critiques qui nous semble déjà pertinentes au bout de 4 jours de gros travail de vérifications manuelles, en attendant d'avoir un peu plus de recul pour faire une analyse plus approfondies des données et de la vidéo.
Ce sera aussi l'occasion de relativiser certaines critiques émises contre la vidéo qui apparaissent elles-mêmes comme peu pertinentes.
Nous allons découper les retours critiques en fonction des parties de la vidéo à savoir Intro + analyses de données + ajouter une partie à propos des réactions sur les réseaux.
Nous allons citer des tweets issus de plusieurs threads critiques, il est inutile de lire chacun de ces threads sauf si on signale de le faire, normalement la lecture du présent thread devrait donner une image globale des critiques.
1- Introduction.
1a. Dans la vidéo MP (MizPauline) contextualise d'emblée ce qui la motive : "Acermendax accuse le collectif de harcèlement, ce que le collectif nie bien entendu".
1a. Dans la vidéo MP (MizPauline) contextualise d'emblée ce qui la motive : "Acermendax accuse le collectif de harcèlement, ce que le collectif nie bien entendu".
Ce qu'il faut retenir c'est que les deux groupes sont juges et parties, et donc qu'il va falloir confronter les arguments pour se faire une idée plus juste du problème.
Car il y a 2 possibilités quant au fait que nous nous défendions. La 1ière serait effectivement que "bien entendu", nous n'admettrions jamais nos erreurs. La 2e, ce serait que la vidéo entraine réellement une image biaisée de nos comportements.
https://twitter.com/VioletGael/status/1573629078753746949?s=20&t=KABT2uR_P1DtSd1SRaqmOw
Cela ne pourra être tranché qu'en regardant les arguments, qui donc, vont suivre. C'est notre droit le plus entier de défendre notre réputation et de faire valoir un droit de réponse, ce qui n'est pas incompatible avec le fait d'envisager de se planter sur des trucs *aussi*.
Pour ceux qui douteraient que cela nous arrive, nous vous renvoyons au fait qu'il nous est arrivé de faire des threads de critique interne et *précis*, tout simplement, qui ont d'ailleurs eu un impact interne très fort.
https://twitter.com/VioletGael/status/1374121865267011591?s=20&t=rLLlwH20N6IwVkVSB3Qd3g
1b. Ensuite MP présente le contexte : une scission entre "les vulgarisateurs sceptiques mainstream" et "un groupe de personnes visant à réformer le scepticisme". Elle précise son propre positionnement non neutre (partie prenante des "zets mainstreams").
1c. Elle enchaine sur la définition du harcèlement. Elle rappelle une partie de la définition du code pénal et insiste sur le fait que c'est le caractère répétitif qui caractérise le harcèlement indépendamment, dit-elle, de la légitimité des critiques.
legifrance.gouv.fr/codes/article_…
legifrance.gouv.fr/codes/article_…
Une critique importante qui est faite de la définition choisie, c'est de ne pas rappeler que les jugements se basent aussi sur des jurisprudences, et que l'audience, le caractère public d'une personnalité, le statut des critiques dont certains bénéficient de protection...
fonctionnelle (journalistes, enseignants chercheurs), entre autres, modulent en fait la caractérisation. Justement pour permettre les critiques légitimes de personnalités publiques.
https://twitter.com/pierre_jacquel2/status/1573688799741104128?s=20&t=fcaso5TGXMFdITwTnD_dHg
https://twitter.com/factoseptik/status/1573667174518067201
2- Analyse des articles de blog
2a- MP annonce qu'elle a lu tous les articles du site zet-ethique.fr, et avait commencé à récolter les données manuellement. Puis lorsqu'elle a voulu faire des comparaisons avec les blogs de La Menace Théoriste (tenu par Acermendax) et..
2a- MP annonce qu'elle a lu tous les articles du site zet-ethique.fr, et avait commencé à récolter les données manuellement. Puis lorsqu'elle a voulu faire des comparaisons avec les blogs de La Menace Théoriste (tenu par Acermendax) et..
L'économiste sceptique, les données des TROIS blogs ont été re-collectées de manière automatisée et ont servi à corriger les données manuelles.
Rien d'autre n'étant précisé sur la manière dont la réconciliation des données est effectué, il semble plausible de penser que ce sont les données automatisées qui vont servir aux analyses.
C'est la première grosse inquiétude méthodologique pour nous : nous citons parfois les créateurs de contenu de la sphère ZET de manière neutre ou même positive. Comment la distinction à t'elle été faite lors de la collecte des données? 

2b- MP enchaine sur l'évolution des publications par années sur notre blog. Une chose qui n'est pas connue de MP et donc n'a pas pu être précisée, c'est que les premiers articles du blog sont importés de certains de nos anciens blogs. Le blog date en fait de 2019.
Mais du coup, le blog à toujours visé à "concentrer" nos critiques du milieu sceptique. Certaines critiques ne nomment pas de vulgarisateur, certaines le font, mais tout article publié depuis 2019 s'adresse à la communauté *pour réformer le milieu*.
zet-ethique.fr/2022/09/14/new…
zet-ethique.fr/2022/09/14/new…
Nous avons individuellement de nombreux autres supports pour nos travaux de réflexion critique qui ne sont pas "métacritiques". Une 2e question méthodologique porte donc sur le fait de mesurer notre "agressivité" par des pourcentages d'articles critiques du milieu... sur le blog.
Et ce d'autant plus que comme cela à été relevé dans plusieurs threads, les pourcentages conduisent à conclure que nous serions "plus agressifs" (ou plus "répétitifs" puisque c'est le mot choisi dans la définition)...
https://twitter.com/TibbohTranquil/status/1573730922385530885?s=20&t=cy6pxIC6oLtfzOc1jLdEnA
https://twitter.com/ChoisyRomain/status/1573623482663010305?s=20&t=GOxNWm0UjL9vgIbRQtytBA
que les deux autres blogs envers leur personnalité la plus critiquée, alors que regarder les effectifs conduit à conclure l'inverse au moins pour la comparaison ZEM-MT.
https://twitter.com/Bunker_D_/status/1574077464464203777?s=20&t=OGi58omRa0_LyjZ1V4e0kA
BunkerD insiste par ailleurs sur le fait que pour caractériser l'intensité de la répétition, il faudrait évaluer la manière dont elle se concentre ou non dans le temps, par année par exemple, puisque l'ancienneté du blog MT (2013) "dilue" ses pourcentages.
https://twitter.com/Bunker_D_/status/1574077469262495747?s=20&t=OGi58omRa0_LyjZ1V4e0kA
Et il insiste également sur la nécessité d'évaluer l'impact en termes d'audience et de popularité des articles.
https://twitter.com/Bunker_D_/status/1574077474304057345?s=20&t=OGi58omRa0_LyjZ1V4e0kA
Une critique qui a été faite est qu'une comparaison par un test statistique ne montre pas de différence significative. Vous pouvez la laisser de côté sachant que vu les critiques ci avant et le but d'un test (généraliser), le test est peu pertinent.
https://twitter.com/tnzn00/status/1573725727576543233?s=20&t=g_ghFFt5_KlBXUSHmYuZzw
2c- Dernier élément qui n'a pas été relevé dans les tweets : la mesure, même en "nombre" d'articles citant négativement biaise le sentiment de focalisation:
nous pouvons citer Mendax de manière critique au détour d'une phrase dans des articles de 2h de lecture qui ne parlent plus de lui ailleurs.
Tandis que Mendax qui parle d'Aberkane c'est ça (à raison, d'ailleurs, c'est important de rappeler cette imposture) : menace-theoriste.fr/idriss-aberkan…
Les seules fois où des articles se focalisent sur Mendax dans notre travail, c'est quand ils sont des réactions à des attaques de lui...
Les seules fois où des articles se focalisent sur Mendax dans notre travail, c'est quand ils sont des réactions à des attaques de lui...
sur nous, dont nous nous sommes défendu-e-s (et encore, nous avons souvent choisi de "passer outre"). Comme la réponse qu'on à fait à son article sur les "sceptiques des sceptiques". Réponse qui le mentionne clairement négativement mais qui du coup est comptabilisé...
comme harcèlement alors qu'elle est une réaction de défense expliquant en quoi son attaque était fallacieuse !
Nous ignorons à propos si le sien sur les "sceptiques des sceptiques" était comptabilisé, puisqu'il a prétendu au départ ne pas s'attaquer à nous. On laissera chacun juger ce qui est plausible mais notez que nous vivons et interprétons cela, nous,
comme un choix de communication assez général de la part de la TEB envers nous : ne pas nous citer nommément, c'est maintenir la source de nos critiques dans l'ombre auprès de la plus large part de son audience.
C'est aussi nous empêcher de dire qu'il y a des épouvantails sur les thèses qu'on défend, puisqu'il suffit de dire que ce n'est pas les nôtres qui sont attaquées.
Mais beaucoup des critiques qui sont faites sur les "sceptiques des sceptiques" et autres appellations vagues du genre génèrent bel et bien un a priori négatif envers nous. Cela aura son importance dans la suite de l'analyse de la vidéo.
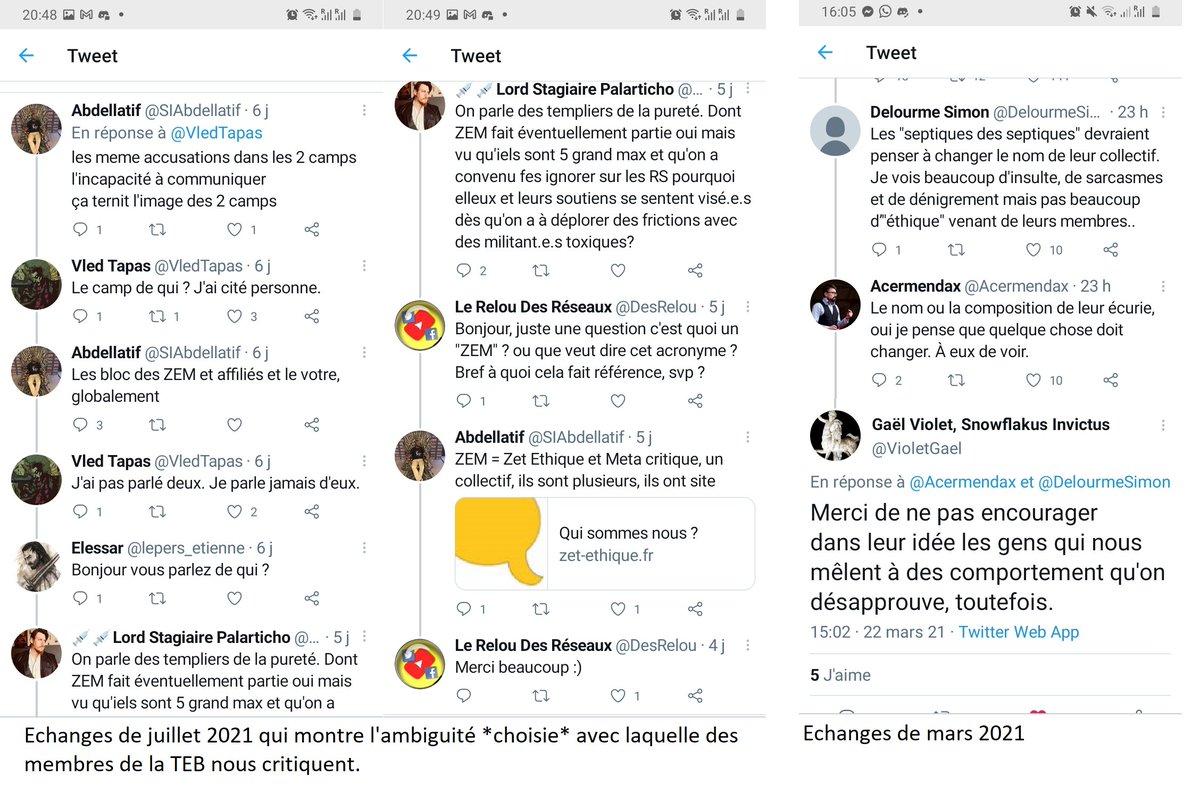
2d- Pour conclure sur la partie analyse des articles, la vidéo indique que les données des articles ne sont pas suffisantes. Mais comme on l'a vu, ces données ont quand même ancré une forte impression d'obsessionalité de notre part, qui va renforcer le biais d'ancrage.
3- Analyse Twitter.
3a. L'objectif annoncé des deux jeux de données collectés sur Twitter est de voir si on montre "le même intérêt" sur Twitter que dans nos articles.
3a. L'objectif annoncé des deux jeux de données collectés sur Twitter est de voir si on montre "le même intérêt" sur Twitter que dans nos articles.
3b. Pour cela, il s'agit de s'intéresser à l'activité des membres publiquement étiquetés comme membres de ZEM sur le compte collectif @zetethmeta. Cela nous semble être un choix raisonnable.
3c. Pour le choix des comptes "ZET", il est justifié par le fait d'être des comptes régulièrement critiqués sur le blog ZEM. Cependant la liste comprend les comptes de personnes qui n'ont jamais été critiquées voir même citées sur le blog.
Et ne contient pas le compte de par exemple Hygiene Mentale qui est cité sur le blog.
https://twitter.com/ChoisyRomain/status/1573623474907643904?s=20&t=WRl-IXC1HaVVg_u8Mj3TpA
Cela n'est pas très grave, on peut noter que c'est la liste des comptes face auxquels la polarisation est la plus vive. Et ce critère d'inclusion là ferait sens. Mais dans ce cas, il aurait été mieux d'inclure MadamCaptain, AstronoGeek, DDE, l'Economiste Sceptique, ou EBBH
...également. Et de le rendre explicite. Trois des noms du tableau étant derrière le personnage nous ne pouvons que supposer leur identité à partir des photos de profil présentées en amont de la vidéo.
3d. Le premier jeu de données consistait à récupérer environ 3000 tweets pour chaque compte sélectionné. Cela introduit comme expliqué un biais, puisque certains comptes tweetant beaucoup, cela fait remonter leur historique à plusieurs mois, versus plusieurs années pour d'autres
Une analyse de co-occurence à ensuite été faite sur ce jeu de données pour identifier les mots souvent associés entre eux dans les tweets. C'est une démarche intéressante pour regarder les thématiques d'intérêt d'un groupe de gens sur Twitter.

Quelque chose qui à été frappant dans la description orale est que MP décrit les données en indiquant que "comme les zets, les zem parlent de science" alors que les ZET parlent clairement moins de sciences en général que les ZEM d'après les graphes.
Si on reprend la question de l'obsession pour Mendax, une conclusion de ces graphes aurait également dû être que son apparition, bien qu'observable, est mineure comparé à tous les autres sujets abordés.
https://twitter.com/TibbohTranquil/status/1573733546908344321?s=20&t=cy6pxIC6oLtfzOc1jLdEnA
Soit : Mendax est clairement loin d'être une obsession des ZEM d'après le graphe, même s'il fait effectivement partit de sujets de discussion (en lien avec... harcèlement).
Mais cela n'est pas précisé dans la vidéo. A la place, MP enchaine sur l'analyse plus spécifique des noms propres. Dans cette analyse là Thomas Durand occupe une "bonne place". Devant Poutine, ce qui choque un peu MP.
Cependant, cela ne traduit pas le fait de "moins se préoccuper de sujet politiques". Seulement de moins se préoccuper de sujets politiques qui sont relatifs à des noms propres !
Nos préoccupations politiques se focalisent beaucoup sur l'analyse des idées, et cela se voit dans le graphe, mais n'est pas mentionné.
https://twitter.com/Bunker_D_/status/1574077496491909123?s=20&t=OGi58omRa0_LyjZ1V4e0kA
Par ailleurs, concernant les thématiques "d'actualité", il convient de dire que ce sont celles les plus affectées par les biais énoncés au début de la méthodologie (les comptes tweetant plus remontent moins loin dans le temps).
Une personne dont les tweets remontent à seulement 2022 tweetera moins sur des sujets anciens car les "moments" auxquels ces sujets étaient "chauds" sera déjà passé.

Le biais dans les périodes couvertes peut cependant n'expliquer qu'en partie le fait que la crise sanitaire apparaisse aussi peu dans nos tweets. Il convient de préciser que les comptes qui en parlent le plus dans ZEM sont les comptes qui s'intéressent à l'antivalidisme...
(Gaël Violet et CNQT), dont les tweets ne remontent qu'à quelques mois. Mais ce n'est pas la seule explication : même nous avons préféré faire le gros de notre communication sur la crise sanitaire en dehors de Twitter, jugeant que ce n'était pas l'espace approprié pour le faire.
En ce qui concerne l'Ukraine, c'est un sujet sur lequel bcp d'entre nous n'avons pas suffisamment de compétence pour donner des informations pertinentes. En revanche @Patchwork_vid à fait une vidéo sur La stratégie complotiste de Poutine : .
Il convient de rappeler que les RT ne sont pas comptabilisés, seulement nos propres tweets, ce qui introduit également un biais car nous avons souvent fait le choix de partager le contenu de personnes plus qualifiées que nous-mêmes.
Mais oui, nous clairement nous tweetons moins sur l'Ukraine que les comptes Zets. C'est probablement le résultat présenté le plus solide de toute la vidéo, reconnaissons le.
Enfin, concernant les gros mots, ils ne sont rattachées qu'à un seul compte ayant utilisé ces mots ensemble 6 fois sur sa période. Et comme noté par BunkerD:
https://twitter.com/Bunker_D_/status/1574077499549556737?s=20&t=OGi58omRa0_LyjZ1V4e0kA
3e. Avec le même jeu de données, donc toujours limité par périodes (ce qui peut générer des biais lié aux "shitstorms" qui ont des temporalités par fenêtres- e.g. mai-juin 22), sont ensuite analysés les "tags" : le nombre de fois où une personne est "taguée" dans un tweet.
Dans la méthodologie, il est indiqué que les tag de début et fin de tweet ont été supprimés, et seulement ceux de corps de tweet conservés. Cependant, on ne retombe pas du tout sur les nombres de tags des tableaux si on ne compte pas les tags...
qui sont mis automatiquement par Twitter lorsqu'on répond à un tweet dans lequel une personne était déjà tagué. Il y a donc une clarification nécessaire à faire sur la méthodologie à ce niveau.
MP précise que la pertinence du nombre de tags est liée aux notifications : beaucoup de notifications de la part de comptes hostiles peut générer un stress important. Cependant, elle omet un "détail" très important à cet égard : nous sommes désormais tous bloqués par les ZETs.
Il y aurait beaucoup de choses à dire sur ces données. On se focalisera sur les plus importantes.
Comme le signale Vinteuil (voit ce thread), ...
Comme le signale Vinteuil (voit ce thread), ...
https://twitter.com/Vinteuil_LTP/status/1574415128187080707?s=20&t=wwfwNmUlfJENx-lLKxCcJg
il suffit d'avoir eu 3-4 longues conversations où les personnes étaient taguées en amont par autrui pour que le nombre de tags associés à nos comptes explose.
Il convient de noter également qu'il y a une asymétrie dans la manière dont se font les tags entre les deux groupes. Comme signalé en amont, il ya un choix actif de "ne pas nous nommer" (ou taguer).
https://twitter.com/Bunker_D_/status/1574077504800931840?s=20&t=OGi58omRa0_LyjZ1V4e0kA
MAIS ça n'empêche pas de nous "attaquer", de manière moins directe. La manière dont nous sommes "attaqués" par Mendax (ou Penseur Sauvage) n'implique jamais de nous taguer. C'est systématiquement : captures d'écran --> leur fanbase sur nos dos.
https://twitter.com/Bunker_D_/status/1574077507514830848?s=20&t=OGi58omRa0_LyjZ1V4e0kA
Dans ces cas là, ce qui se passe, c'est que lorsqu'on est "affichés", on s'en va se défendre sous les comptes qui ne nous ont pas bloqués... et l'auteur des captures est déjà tagué par... lui même en amont.
Il délègue les réponses à ses fans. C'est ce qui explique que par exemple "CNQT est mentionnée 4 fois moins que AcerMendax" : les gros comptes répondent peu dans ces conversations-là, et nous si, pour se défendre. C'est une dynamique récurrente.
Certains membres de ZEM ont cependant déjà eu la démarche d'alpaguer Mendax pour faire des threads s'adressant à lui. Exemple :
https://twitter.com/DrSornette/status/1355965954665164802
Et du coup effectivement un thread de dizaines de tweets, ça fait dizaine de tags. Mais attention pas dizaine de notifs, Twitter regroupe les notifs dans ces cas-là.
On notera que quand DrSornette a écrit ce thread, elle était déjà bloquée par Mendax... Qui n'a donc pas pu recevoir de notifications. L'échange qui a suivi résulte d'un déblocage temporaire par Mendax, qui a fini par bloquer définitivement DrSornette à la fin de l'échange.
Contrairement à l'impression fausse qui est donnée par cette analyse nous ne "poursuivons" pas les ZETs en les taguant tout le temps et partout. Et ce même avant nos blocages, d'ailleurs.
Globalement, attention car avec cette répétition de l'idée de harcèlement, il y a quand même une idée selon laquelle ZEM "poursuit agressivement" les zets, alors que ça ne correspond pas du tout aux dynamiques réelles.
Les (3-4) personnes qui ont été dans ZEM qui auraient à un moment refusé les standards d'échange définis en interne pour limiter les risques de participer à du harcèlement se sont finalement alignés sur les standards ou ont pris leur propre chemin hors du collectif.
En résumé concernant ces données il y a : des biais possibles liés aux temporalités des shitstorms et au décalage des périodes couvertes par les comptes, le fait que répondre, et longuement, gonfle le nombre de tags, ...
le fait qu'être bloqué fait que tag n'équivaut pas à notif. Ces données-là ne sont informatives de pas grand-chose de pertinent concernant le harcèlement dans ce contexte spécifique ayant les dynamiques qu'on a décrites, au moins.
4- Analyse des sentiments (avec les tags)
4a. Un 2ième jeu de données à été collecté sur Twitter, pendant 1 mois du 18 juillet au 18 août. Tous les tweets de Twitter contenant les mots clefs listés ci après ont été récoltés.
4a. Un 2ième jeu de données à été collecté sur Twitter, pendant 1 mois du 18 juillet au 18 août. Tous les tweets de Twitter contenant les mots clefs listés ci après ont été récoltés.

Cette analyse doit permettre d'analyser les interactions entre nébuleuses ZEM et ZET. Nous avons eu plus de détails sur la méthodo via Flef qui signale avoir participé à cette partie de l'analyse. Merci pour ses éclaircissements.
https://twitter.com/FlefGraph/status/1573359012619628544?s=20&t=xzAgq-XxPsyylaEa_i28FA
Pour répondre à une critique portée contre la vidéo, il est précisé par Flef que la période à été collectée de manière prospective, et non pas rétrospective. Il n'était pas possible de savoir à l'avance ce qui allait se passer pendant le mois de collecte.
https://twitter.com/TibbohTranquil/status/1573735449486675968?s=20&t=r31D0wqkfEldIJnjEeo9vw
Cependant, nous tenons à signaler que PenseurSauvage à publié une série de 4 vidéos revenant sur la shitstorm du REC de manière totalement calomnieuse à notre égard à partir du 17 juillet, ce qui permettait de s'attendre à beaucoup de réactions de notre part sur cette période.

Beaucoup d'entre nous avons choisi de ne pas réagir quitte à nous laisser calomnier, par nécessité psychologique après la shitstorm déjà violente liée aux RECs. On a presque envie de dire "heureusement pour nous"...
L'objectif des données était donc de faire deux analyses de sentiment, une décrivant les sentiments négatifs en lien avec les 6 identifiants relatifs à Acermendax, et une autre décrivant les sentiments négatifs en lien avec 5 identifiants lié à ZEM
4b. La première critique évidente de ce jeu de donnée porte sur les choix des identifiants : péjoratifs d'un coté, neutres de l'autre (alors que les ZEM sont aussi affublés de mots négatifs). Voir le thread :
https://twitter.com/VioletGael/status/1573632126578221063?s=20&t=bENA968atYQ56KtbKe3MMw
Mais encore absence de "ZEM" alors que c'est l'identifiant le plus courant pour nous. Etc, voir :
https://twitter.com/tnzn00/status/1573616493962600449
https://twitter.com/pierre_jacquel2/status/1573688971015561216?s=20&t=Fj616oy6_1xSxyM-5Eb54Q
Flef le justifie ainsi (voir les 3 tweets) :
https://twitter.com/FlefGraph/status/1573834226272800775?s=20&t=xzAgq-XxPsyylaEa_i28FA
C'est une réponse partielle : s'il est "un peu" rassurant de savoir que le sobriquet "Merdax" ne rajoute "que" une dizaine de tweets sur des milliers, nous n'avons aucune possibilité de savoir quelle quantité de tweets il y aurait en plus avec ZEM ou des sobriquets liés à ZEM.
Par ailleurs, le nombre de tweets récoltés avec "Acermendax" et "Mendax" sont très peu probablement aussi petits que "une dizaine", donc le nombre de tweets liés à ces pseudos aurait été plus informatifs que le nombre de tweets récoltés avec "Merdax" pour se défendre d'un biais.
Comme on l'a déjà souligné, il y a une asymétrie qui ne peut être négligée dans la construction d'une telle méthodologie : les attaques envers les membres de ZEM par la nebuleuse ZET sont volontairement floues.

Au final, il y a presque eu une information à tirer de ça: le petit nombre de tweets récupérés via les sobriquets comparé au total indique que les sobriquets péjoratifs ne sont pas le moyen le plus courant de parler de Mendax dans la nébuleuse qui entoure ZEM...
4c. Concernant la pertinence de l'utilisation des algo d'analyse de sentiments sur ces données, nous avons une personne compétence en interne pour faire une critique technique étayée mais cela prendra un peu de temps.
En attendant, voici quelques critiques qui ont été faites par des personnes diverses. Il semble que la question principale porte sur le fait d'utiliser une base de détection des sentiments qui n'est pas étalonnée pour ce type de jeu de données.
https://twitter.com/mushi_e_/status/1573685372827181059
Egalement ici.
https://twitter.com/ChoisyRomain/status/1573623494570541056?s=20&t=WRl-IXC1HaVVg_u8Mj3TpA
Cela pose d'autant plus problème car il y a toute une littérature sur Bert (Bender et al. dl.acm.org/doi/10.1145/34… paragraphe 4.3) qui montre que tout ce qui touche aux groupes exclus (en particulier le handicap) est associé à des sentiments négatifs.
Des sujets que nous couvrons de façon récurrentes sont associées à du négatif, et c'est lié aux datas de training : en gros comme beaucoup de gens sont insultants envers les minorités le vocabulaire des minorités est associé à du négatif.
4d. Une question importante est comment le bot @Fallacytron se retrouve t'il dans le jeu de données alors qu'il ne mentionne jamais de nom ou tag par lui-même à part une fois après la vidéo pour présenter des excuses? (reprise du contrôle manuel)
https://twitter.com/TibbohTranquil/status/1573736346627211273?s=20&t=r31D0wqkfEldIJnjEeo9vw
De fait on voit clairement les ovales d'interaction 2 à 2 qui indiquent que chaque tag de réponse est en fait compté comme une mention supplémentaire.
https://twitter.com/TibbohTranquil/status/1573737257667903490?s=20&t=r31D0wqkfEldIJnjEeo9vw
Cela signifie que si un sous fil part dans un sujet totalement différent (dispute, etc) sous un fil où l'un des tags listés est récupéré, tous les tweets de ce sous fil sont comptés comme négativité envers le compte tagué même si la discussion n'a plus rien à voir.
La conséquence, c'est que seulement 1 ou 2 conversations prennent un espace considérable dans les données, alors qu'elles ne sont évidemment qu'épisodiques et ne disent pas forcément grand chose de la négativité envers la personne taguée.
https://twitter.com/Bunker_D_/status/1574077799517851649?s=20&t=5748HeTBlLjctlg-WTM_xQ
A ce propos lire ce thread de Vinteuil:
https://twitter.com/Vinteuil_LTP/status/1574415128187080707
4e. Enfin même si on ne prenait pas en compte ces limites méthodos, Flef qui à contribué à la collecte rappelle lui-même que les données ne correspondent pas à du harcèlement, car le + gros des interactions relatif aux critiques des mots et tags clefs est interne aux nébuleuses.

Ses tweets peuvent être retrouvés là :
https://twitter.com/FlefGraph/status/1573694797579255809?s=20&t=d-ONb87zAUReW-lecUy1uQ
https://twitter.com/FlefGraph/status/1573735536203816963?s=20&t=uA6yPjVmgwR2scuZgzMiPg
4f. Un petit intermède de méditation, face à ces "données" et à l'univers.

5 - Les réactions à la vidéo
De nombreux commentaires ont souligné la "bienveillance" de la vidéo, mais pour notre part nous tenons tout de même à signaler le biais d'ancrage mis en place dans les toutes premières phrases :
De nombreux commentaires ont souligné la "bienveillance" de la vidéo, mais pour notre part nous tenons tout de même à signaler le biais d'ancrage mis en place dans les toutes premières phrases :
la vidéo annonce bel et bien "démontrer" le harcèlement dont nous ferions preuve.
https://twitter.com/pierre_jacquel2/status/1573688797190975488?s=20&t=fcaso5TGXMFdITwTnD_dHg
Nous ne nous joignons pas aux critiques faites à cette vidéo selon lesquelles produire des sciences serait une production réservée aux institutions et aux docteurs / diplomés.
Mais nous rappelons qu'adopter une démarche dont les prétentions sont scientifiques doit s'accompagner d'un minimum de rigueur, tout de même. Ce qui compte c'est l'adéquation de la méthodologie pour répondre aux questions posées.
La présente analyse est aussi l'occasion de rappeler qu'une bonne analyse quantitative ne peut se passer, en amont, d'une bonne analyse qualitative du sujet abordé. On le voit très bien ici !
Nous terminerons sur le fait que certains twittos profitent de l'occasion pour porter des propos totalement calomnieux à notre égard. Ayant une faible audience nous ne leur donneront pas d'avantage d'importance qu'ils n'en méritent, ...
mais notez bien qu'il ne faut pas croire tout ce qu'on lit sur internet... par ex une personne nous accuse de l'avoir mis au RSA et de l'avoir fait quitter twitter alors que nous ignorions totalement son existence jusqu'à 6 mois *après* son retour sur twitter.
Nous avons tous les éléments matériels pour le prouver. Ce n'est pas le seul à faire cela. Nous rappelons donc que, comme le harcèlement, la diffamation et la calomnie sont également inscrites dans le code pénal.
6 -Concluons
Bien que la vidéo ait semblé 'objective et bienveillante", les données présentées et leur interprétation sont tellement biaisés que même nos soutiens direct surestiment ce qu'elle dit de nous.
Bien que la vidéo ait semblé 'objective et bienveillante", les données présentées et leur interprétation sont tellement biaisés que même nos soutiens direct surestiment ce qu'elle dit de nous.
https://twitter.com/jeremy_royaux/status/1573601116750848002?s=20&t=m_Zu7OKQHlJQ3IFhPzEz0Q
Même nous (!) avons au début surestimé ce qu'elle disait de nous!
Au final, après décorticage, qu'est ce que cette vidéo aura montré? Certainement pas de preuve d'un harcèlement. L'absence de preuve n'étant pas la preuve d'absence, ...
Au final, après décorticage, qu'est ce que cette vidéo aura montré? Certainement pas de preuve d'un harcèlement. L'absence de preuve n'étant pas la preuve d'absence, ...
ça ne nous empêchera pas de surveiller nos comportements et de réfléchir à nos pratiques. Comme nous l'avons toujours fait, publiquement d'ailleurs, et sur des cas précis pas juste pour dire "ça nous arrive de faire des erreurs".
Nous invitons "l'autre coté du ring" à faire de même, et à donner des éléments plus visibles indiquant qu'ils le font, car pour le moment, on ne les voit pas beaucoup le faire.
Nous vous laissons avec un billet de @Jayne, bonne lecture.
https://twitter.com/Shaushkaa/status/1574629076840562688?s=20&t=rLLlwH20N6IwVkVSB3Qd3g
• • •
Missing some Tweet in this thread? You can try to
force a refresh



