#OCPSummit22 kicking off. First keynote by Intel
"We have an amazing track record of improving energy efficiency" - @intel Zane Bell
Umm...
He's talking about datacenters, but Moore's law slide here is a bit funny given the history.
The bit on server resilience is very important.
"We have an amazing track record of improving energy efficiency" - @intel Zane Bell
Umm...
He's talking about datacenters, but Moore's law slide here is a bit funny given the history.
The bit on server resilience is very important.



Intel is releasing a spec for immersion cooling, and will offer warranty too
"Air is running out of steam. It's time to embrace immersion cooling" - @intel Zane Bell
"More energy in immersion cooling than ever, the time is now"
#OCPSummit22
"Air is running out of steam. It's time to embrace immersion cooling" - @intel Zane Bell
"More energy in immersion cooling than ever, the time is now"
#OCPSummit22



Up next at #OCPSummit22 is @Meta
They do 90M AI inference per second for Instagram!
Their models are massive but compute is not as high for DLRMs due to continuous and categorical features stored in embedding tables.
@OpenComputePrj
They do 90M AI inference per second for Instagram!
Their models are massive but compute is not as high for DLRMs due to continuous and categorical features stored in embedding tables.
@OpenComputePrj

@Meta are announcing Grand Teton which is their new AI server.
Looks like it has 8x A100 PCIe not SMX?
Not sure what CPU.
#OCPsummit22
Looks like it has 8x A100 PCIe not SMX?
Not sure what CPU.
#OCPsummit22



New open rack v3 at @OpenComputePrj
48V
Up to 20kW
Flexible in what type of servers it supports.
Can support 300% transients!
#OCPSummit22
48V
Up to 20kW
Flexible in what type of servers it supports.
Can support 300% transients!
#OCPSummit22



@Meta also talking about the issues in model training.
The interconnects aren't scaling and that leads to as much as 57% of time spent waiting for networking in model training
Discussed this in the article linked
#OCPSummit22
semianalysis.com/p/meta-discuss…
The interconnects aren't scaling and that leads to as much as 57% of time spent waiting for networking in model training
Discussed this in the article linked
#OCPSummit22
semianalysis.com/p/meta-discuss…


@Meta is re-presenting these slides, but networking is taking most the bandwidth and accelerators will need 1TB/S of accelerator to accelerator IO with a purpose built non-blocking fabric.
Discussed in linked article.
semianalysis.com/p/meta-discuss…
#OCPSummit22 @OpenComputePrj
Discussed in linked article.
semianalysis.com/p/meta-discuss…
#OCPSummit22 @OpenComputePrj


Datacenters used 1% to 1.5% of worldwide power in 2020.
By 2030, datacenters will consume 3% to 13% of worldwide power generation!
#OCPSummit22 @OpenComputePrj
By 2030, datacenters will consume 3% to 13% of worldwide power generation!
#OCPSummit22 @OpenComputePrj

"More compute with less power" - @jwittich is the goal for @AmpereComputing
They project in 2025, Ampere servers using @Arm ISA will require less than half the power + area as "legacy" x86 based servers.
Rack density, scalability, utilization rates, noisy neighbors
#OCPSummit22
They project in 2025, Ampere servers using @Arm ISA will require less than half the power + area as "legacy" x86 based servers.
Rack density, scalability, utilization rates, noisy neighbors
#OCPSummit22


Some harder figures and claims from @AmpereComputing @jwittich
Power efficiency in NGINX, 3.8x vs Icelake
Much more consistent performance, nearly no noisy neighbors
Scales near linearly in perf
Standard 12.8kW rack, more than double the cores and 2x the performance
#OCPSummit22
Power efficiency in NGINX, 3.8x vs Icelake
Much more consistent performance, nearly no noisy neighbors
Scales near linearly in perf
Standard 12.8kW rack, more than double the cores and 2x the performance
#OCPSummit22


@AmpereComputing is now announcing their next generation Siyrn based platforms.
They support 2U, 2P, using DDR5 2DPC and PCIe 5.0, based on the Siyrn architecture which we detailed exclusively at SemiAnalysis!
@jwittich @OpenComputePrj #OCPSummit22
They support 2U, 2P, using DDR5 2DPC and PCIe 5.0, based on the Siyrn architecture which we detailed exclusively at SemiAnalysis!
@jwittich @OpenComputePrj #OCPSummit22


Here is where we exclusively detailed the architecture for @AmpereComputing next generation Siyrn architecture.
semianalysis.com/p/is-ampere-co…
semianalysis.com/p/is-ampere-co…
Next up is @Broadcom talking about Ethernet, the leader in Ethernet switches.
~600M Ethernet ports are shipped annually.
4x as many Ethernet ports as people board each year.
#OCPSummit22 @OpenComputePrj
~600M Ethernet ports are shipped annually.
4x as many Ethernet ports as people board each year.
#OCPSummit22 @OpenComputePrj
"Basically give every newborn 4 ethernet ports when they are born and say happy birthday! Try that with Infiniband, so expensive it would exceed world GDP"
This was funniest thing I've heard in a keynote ever
Broadcom savage on stage about @nvidia @NVIDIANetworkng
#OCPSummit22
This was funniest thing I've heard in a keynote ever
Broadcom savage on stage about @nvidia @NVIDIANetworkng
#OCPSummit22
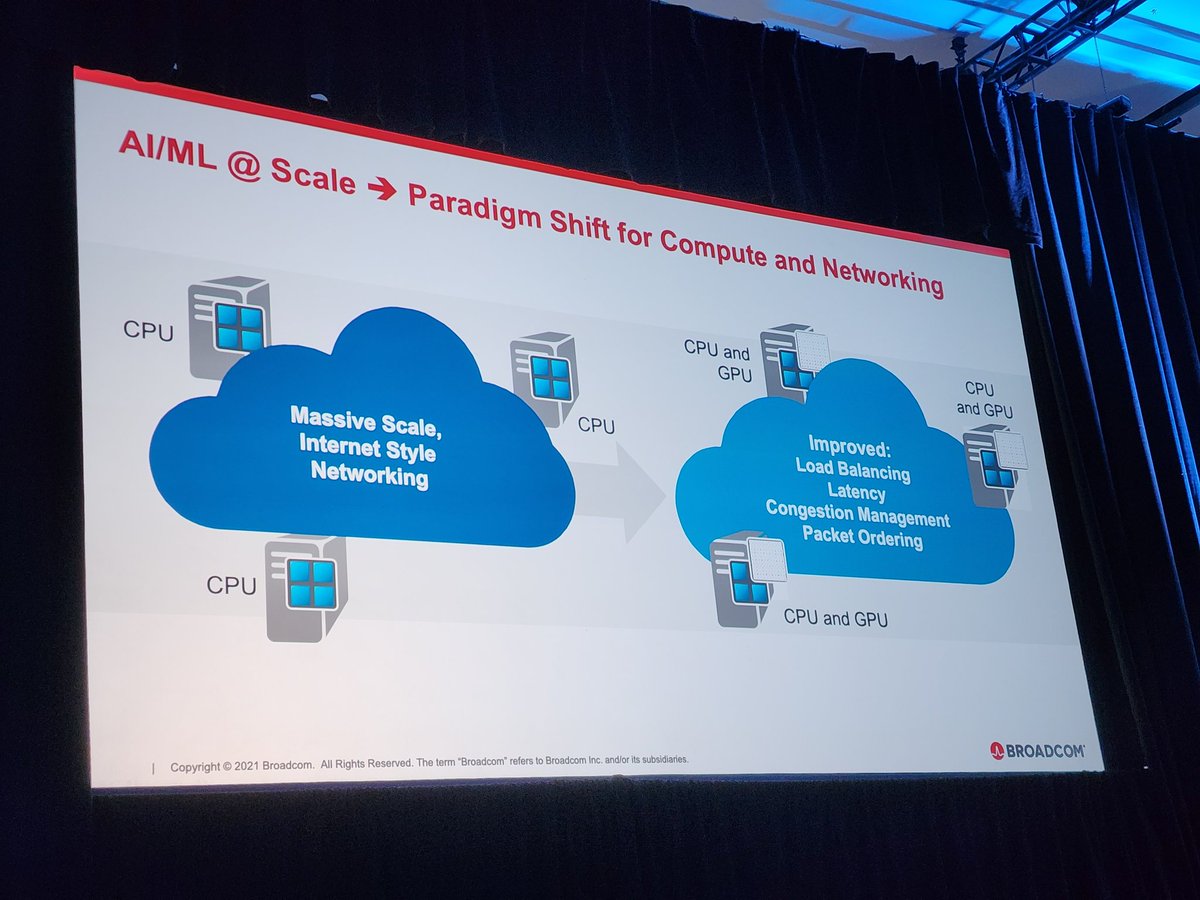
Infiniband used to be far lower latency, but less flexible.
Broadcom is talking up their advancements with HPC Ethernet bringing the latency gap to 0.
The data they presented is from Los Alamos National Lab @LosAlamosNatLab
#OCPSummit22
Broadcom is talking up their advancements with HPC Ethernet bringing the latency gap to 0.
The data they presented is from Los Alamos National Lab @LosAlamosNatLab
#OCPSummit22

Now talking about transient over subscription, flow collisions, and incast overload.
Addressing these quenes and load balancing is critical to maintain low latency.
#OCPSummit22
Addressing these quenes and load balancing is critical to maintain low latency.
#OCPSummit22

Broadcom acquired a new company to help with these issues.
They will maintain Ethernet leadership
Incast can be solved by drop congestion notification aka packet trimming.
Transient congestion with packet spraying
In network telemetry can help buffer packets
#OCPSummit22
They will maintain Ethernet leadership
Incast can be solved by drop congestion notification aka packet trimming.
Transient congestion with packet spraying
In network telemetry can help buffer packets
#OCPSummit22



@Meta head of networks on stage talking about closer collaboration with @Broadcom
Mentioned lots of open software and copackaged optics.
Does this mean that @AristaNetworks software, a huge shipper of Broadcom silicon based in switch boxes to Meta, now going to be dropped?
$ANET
Mentioned lots of open software and copackaged optics.
Does this mean that @AristaNetworks software, a huge shipper of Broadcom silicon based in switch boxes to Meta, now going to be dropped?
$ANET

Caliptra being announced by @Google alongside @Microsoft @AMD @nvidia
No Intel included is noteworthy.
Trusted computing IP will be hardened in silicon at the chip level and package level.
This seems huge!
#OCPSummit22
No Intel included is noteworthy.
Trusted computing IP will be hardened in silicon at the chip level and package level.
This seems huge!
#OCPSummit22

Caliptra is going to be HUGE
For confidential compute so cloud tenants can trust their data and code is secure even from the cloud providor.
It's an open source root of trust.
Reusable silicon block designed into many chips and validates their trustworthiness.
Wow
#OCPSummit22
For confidential compute so cloud tenants can trust their data and code is secure even from the cloud providor.
It's an open source root of trust.
Reusable silicon block designed into many chips and validates their trustworthiness.
Wow
#OCPSummit22

Caliptra specifications, RTL, and firmware which is written in trust is open.
0.5 released.
It's part of @OpenComputePrj and the @linuxfoundation chips alliance.
Microsoft has a live demo here at the conference. AMD, Microsoft, Nvidia, and Google supporting it.
#OCPSummit22
0.5 released.
It's part of @OpenComputePrj and the @linuxfoundation chips alliance.
Microsoft has a live demo here at the conference. AMD, Microsoft, Nvidia, and Google supporting it.
#OCPSummit22


Microsoft and Nuvoton are releasing a new root of trust engine for BMCs too.
Integrated security system.
Determines what BMC can access on a debug requests.
TPM functionality.
Can ensure that BMCs are not modified!
#OCPSummit22
Integrated security system.
Determines what BMC can access on a debug requests.
TPM functionality.
Can ensure that BMCs are not modified!
#OCPSummit22

Project Kirkland announced.
Partnership with Microsoft, Google, Intel, Infineon.
Currently Infineon chip, but will be open sourced.
Trust for TPM and prevent physical bus and interconnect attacks.
#OCPSummit22
Partnership with Microsoft, Google, Intel, Infineon.
Currently Infineon chip, but will be open sourced.
Trust for TPM and prevent physical bus and interconnect attacks.
#OCPSummit22

• • •
Missing some Tweet in this thread? You can try to
force a refresh