
WebGPT reproduced from advanced prompting only.
Dust-based web-search assistant demo answers questions by searching the web, summarizing content and compiling a final answer with references:
dust.tt/spolu/a/41770f…
Dust-based web-search assistant demo answers questions by searching the web, summarizing content and compiling a final answer with references:
dust.tt/spolu/a/41770f…

This app performs the following steps:
1/ search google, take first 3 results
2/ call to a @Replit to get content (headless browsing)
3/ 1st model call to clean-up and summarize each site
4/ 2nd model call (few-shot prompted) to generate final answer with references
1/ search google, take first 3 results
2/ call to a @Replit to get content (headless browsing)
3/ 1st model call to clean-up and summarize each site
4/ 2nd model call (few-shot prompted) to generate final answer with references
Step 1/ 2/ 3/ replace browsing / clicking / scrolling / selecting with a more direct API-based approach. Less shiny but more resilient.
Note that text-davinci-002 is really good at step 3/ out of the box without few-shot examples. Hypothesis: Instruct-series training set probably includes a lot of summarization tasks.
Step 4/ required few-shot prompting to teach the model how to aggregate content and generate references. Two examples were sufficient! Completely fails otherwise.
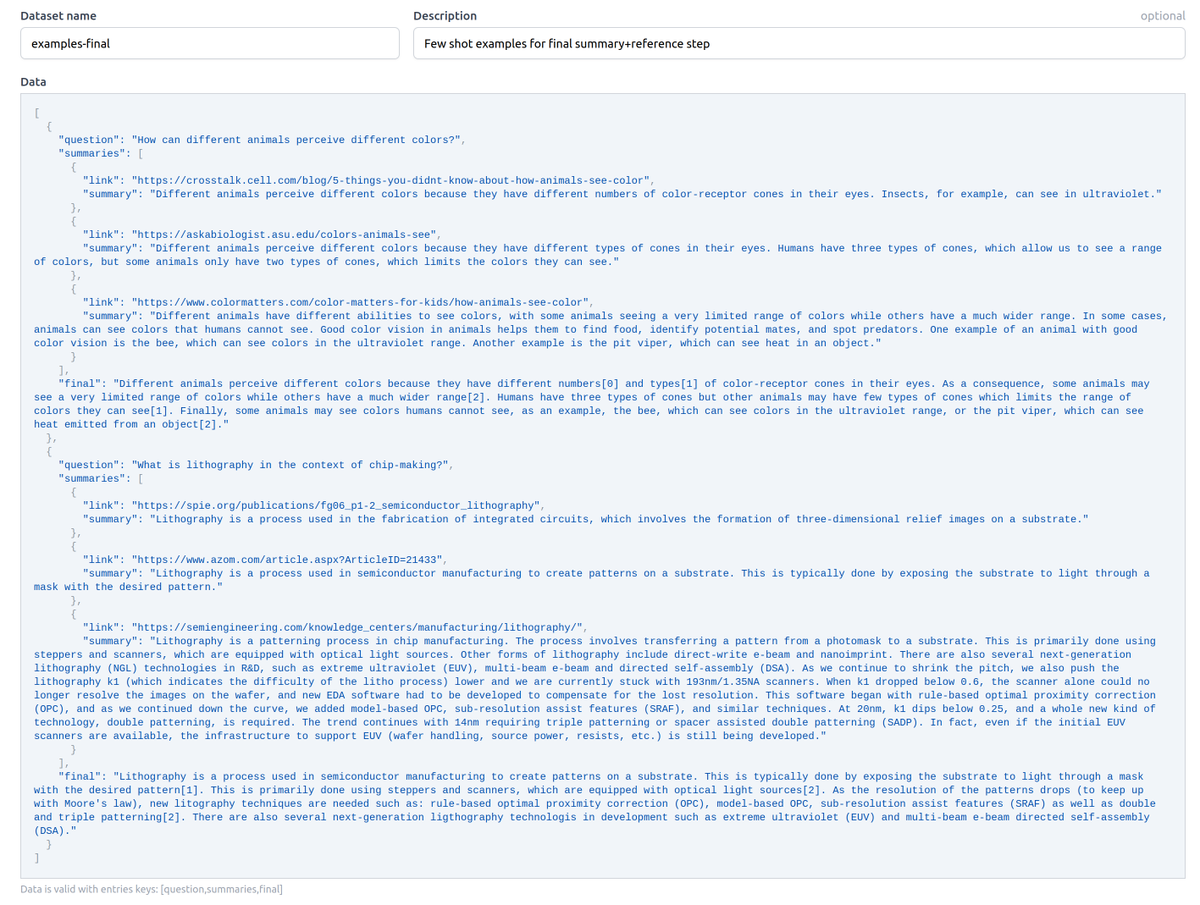
Original WebGPT used 6000 human demonstrations. This uses tools (@replit packaged headless browsing) + APIs (google) + 2 examples.
We hypothesize that data and symbolic structure can be traded for many use-cases. We'll eval this app against the same benchmarks to confirm this.
We hypothesize that data and symbolic structure can be traded for many use-cases. We'll eval this app against the same benchmarks to confirm this.

Study the app here: dust.tt/spolu/a/41770f…
Looking forward to see how this can be adapted to productive use-cases without the need for collecting human trajectories.
Looking forward to see how this can be adapted to productive use-cases without the need for collecting human trajectories.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



