
Announcing our new mechanistic interpretability paper!
We use causal interventions to reverse-engineer a 26-head circuit in GPT-2 small (inspired by @ch402’s circuits work)
The largest end-to-end explanation of a natural LM behavior, our circuit is localized + interpretable
🧵
We use causal interventions to reverse-engineer a 26-head circuit in GPT-2 small (inspired by @ch402’s circuits work)
The largest end-to-end explanation of a natural LM behavior, our circuit is localized + interpretable
🧵
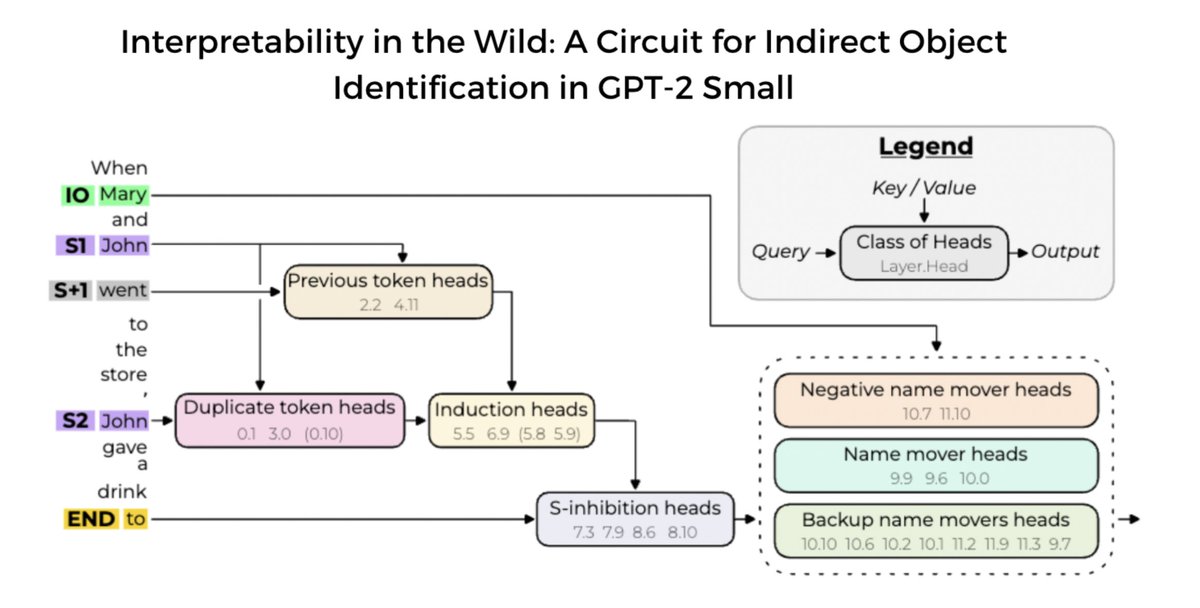
We study indirect object identification (IOI) i.e. “When Mary and John went to the store, John gave a drink to” should be answered with “Mary”, not “John”
IOI is a crisp task and a common NLP pattern “in the wild”, hopefully giving rise to interpretable + interesting structures!
IOI is a crisp task and a common NLP pattern “in the wild”, hopefully giving rise to interpretable + interesting structures!

IOI can be decomposed into a 3-step human-understandable algorithm.
1. Identify all previous names in the sentence
2. Remove all names that are duplicates
3. Output the remaining name
We find components that map to this algorithm
1. Identify all previous names in the sentence
2. Remove all names that are duplicates
3. Output the remaining name
We find components that map to this algorithm
We deviate from @ch402’s framing of circuits by thinking of models as computational graphs, and circuits as subgraphs: nodes are components (MLPs and heads) and edges are when two components compose.

Our circuit consists of 7 types of heads, which compose 4 layers deep.
1. Duplicate token + induction/previous token heads identify previous names
2. S-Inhibition heads suppress attention paid to the duplicate name
3. Name mover heads copy the remaining name
1. Duplicate token + induction/previous token heads identify previous names
2. S-Inhibition heads suppress attention paid to the duplicate name
3. Name mover heads copy the remaining name

The perils of naive interpretability:
When ablating the main Name Mover heads, GPT-2 small can still do IOI…
This happens because Backup Name Mover heads take over!
Conclusion: Basic ablations can be misleading
When ablating the main Name Mover heads, GPT-2 small can still do IOI…
This happens because Backup Name Mover heads take over!
Conclusion: Basic ablations can be misleading
Other surprising discoveries:
- Some heads (negative name movers) write against the correct answer!
- Information is moved via irrelevant tokens because the model uses pre-existing induction heads!
- Some heads (negative name movers) write against the correct answer!
- Information is moved via irrelevant tokens because the model uses pre-existing induction heads!
We introduce a systematic causal intervention for circuit discovery: path patching.
We patch part of a model’s forward pass with activations from a different input, localizing important components.
By patching at the Q, K, or V of heads, we can intervene on specific paths
We patch part of a model’s forward pass with activations from a different input, localizing important components.
By patching at the Q, K, or V of heads, we can intervene on specific paths

Besides path patching, we also use knockouts, activation patching, attention pattern analysis, and projections to the embedding space (logit lens) to supplement our understanding.

Interp explanations can easily be misleading or non-rigorous.
To test the validity of our circuit, we formulate 3 quantitative criteria (faithfulness, completeness, and minimality) that we measure with knockouts.
To test the validity of our circuit, we formulate 3 quantitative criteria (faithfulness, completeness, and minimality) that we measure with knockouts.
These criteria aim to ensure our circuit contains all the nodes important for the task but none of the nodes irrelevant for the task.
Our circuit performs better than a naive circuit that computes IOI as well as the model, yet it still fails worse-case tests
Our circuit performs better than a naive circuit that computes IOI as well as the model, yet it still fails worse-case tests
There is still much we don’t understand! Our circuit does not include the MLPs and LayerNorms (though we have reason to believe that all MLPs are unimportant except for the first MLP). We also do not understand the attention patterns of the S-Inhibition Heads well.
In many ways, this work is like @ch402’s “curve detectors” in vision models, except we don't explain parameters and is only studied wrt a specific input distribution
Analyzing weights, studying training dynamics, or looking for universality would make good future work!
Analyzing weights, studying training dynamics, or looking for universality would make good future work!
Does this approach scale to larger models?
In initial analyses with GPT-2 medium, we find that GPT-2 medium also has a sparse set of heads that write names to the output. However, some of these heads attend to unexpected places suggesting more complex behavior than GPT-2 sm.
In initial analyses with GPT-2 medium, we find that GPT-2 medium also has a sparse set of heads that write names to the output. However, some of these heads attend to unexpected places suggesting more complex behavior than GPT-2 sm.
Some lessons learned:
-Causal interventions are very useful
-Picking the task (and representative distribution) to interpret is vital for success. We think algorithmic tasks (as opposed to heuristics) are easier for interp bc they impose clearer structure on model internals
-Causal interventions are very useful
-Picking the task (and representative distribution) to interpret is vital for success. We think algorithmic tasks (as opposed to heuristics) are easier for interp bc they impose clearer structure on model internals
We also show the value of how mechanistic interpretability work can build on itself!
We (unexpectedly) found induction heads in this circuit, despite them not being strictly necessary.
We hope our work helps future researchers reverse engineer more complex circuits!
We (unexpectedly) found induction heads in this circuit, despite them not being strictly necessary.
We hope our work helps future researchers reverse engineer more complex circuits!
It was wonderful working with @A_Variengien, @ArthurConmy, @bshlgrs and @JacobSteinhardt on this project!
Thanks to @NeelNanda5, @StephenLCasper, @DanHendrycks, @kayo_yin, @d_m_ziegler, @norabelrose, @justanotherlaw and others for insightful feedback.
Thanks to @NeelNanda5, @StephenLCasper, @DanHendrycks, @kayo_yin, @d_m_ziegler, @norabelrose, @justanotherlaw and others for insightful feedback.
To learn more, check out our paper for the research and our Alignment Forum post for some takeaways/lessons:
arxiv.org/abs/2211.00593
alignmentforum.org/posts/3ecs6duL…
arxiv.org/abs/2211.00593
alignmentforum.org/posts/3ecs6duL…
• • •
Missing some Tweet in this thread? You can try to
force a refresh



