
📣 9 papers accepted at #emnlp2022 (7 main conference + 2 Findings)
🧵 with links to camera ready preprints 👇
🧵 with links to camera ready preprints 👇
1) “Does Corpus Quality Really Matter for Low-Resource Languages?”
We introduce a new corpus for Basque that has a higher quality according to annotators, but find that this improvement does not carry over to downstream NLU tasks.
arxiv.org/abs/2203.08111
We introduce a new corpus for Basque that has a higher quality according to annotators, but find that this improvement does not carry over to downstream NLU tasks.
arxiv.org/abs/2203.08111


2) “Efficient Large Scale Language Modeling with Mixtures of Experts”
We study how MoE LMs scale in comparison with dense LMs in a wide range of settings. MoEs are more efficient, but their advantage reduces at scale and varies greatly across tasks!
arxiv.org/abs/2112.10684
We study how MoE LMs scale in comparison with dense LMs in a wide range of settings. MoEs are more efficient, but their advantage reduces at scale and varies greatly across tasks!
arxiv.org/abs/2112.10684

3) “Don't Prompt, Search! Mining-based Zero-Shot Learning with Language Models”, led by @mozeskar
We propose a mining-based approach to zero-shot learning, outperforming prompting with comparable templates.
arxiv.org/abs/2210.14803
We propose a mining-based approach to zero-shot learning, outperforming prompting with comparable templates.
arxiv.org/abs/2210.14803

4) “Prompting ELECTRA: Few-Shot Learning with Discriminative Pre-Trained Models”, led by @xiamengzhou
We show that discriminative models like ELECTRA outperform generative models like BERT in few-shot prompting.
arxiv.org/abs/2205.15223
We show that discriminative models like ELECTRA outperform generative models like BERT in few-shot prompting.
arxiv.org/abs/2205.15223

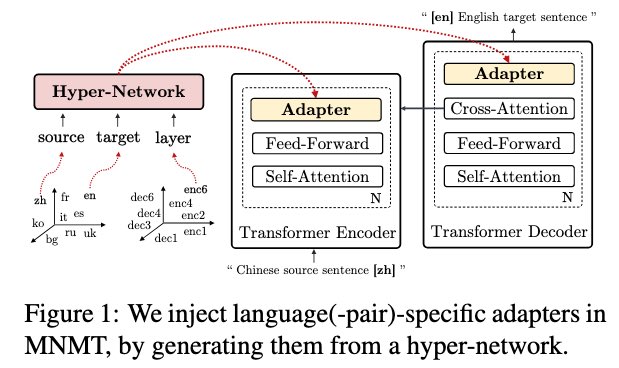
5) “Multilingual Machine Translation with Hyper-Adapters”, led by @cbaziotis
We address prior issues on scaling hyper-networks, and use them to generate language-specific adapters for multilingual MT, matching regular adapters with 12x less parameters!
arxiv.org/abs/2205.10835
We address prior issues on scaling hyper-networks, and use them to generate language-specific adapters for multilingual MT, matching regular adapters with 12x less parameters!
arxiv.org/abs/2205.10835
6) “Few-shot Learning with Multilingual Generative Language Models”, led by @VictoriaLinML & @xl_nlp
We introduce a family of multilingual autoregressive LMs and study them on cross-lingual few-shot learning and machine translation.
arxiv.org/abs/2112.10668
We introduce a family of multilingual autoregressive LMs and study them on cross-lingual few-shot learning and machine translation.
arxiv.org/abs/2112.10668

7) “Rethinking the Role of Demonstrations: What Makes In-Context Learning Work?”, led by @sewon__min
We show that few-shot prompting with random labels is almost as good as with true labels, providing a new perspective on how in-context learning works.
arxiv.org/abs/2202.12837
We show that few-shot prompting with random labels is almost as good as with true labels, providing a new perspective on how in-context learning works.
arxiv.org/abs/2202.12837

8) “On the Role of Bidirectionality in Language Model Pre-Training” (Findings)
We study the role of bidirectional attention and bidirectional context in LM pre-training through a new framework that generalizes prior approaches.
arxiv.org/abs/2205.11726
We study the role of bidirectional attention and bidirectional context in LM pre-training through a new framework that generalizes prior approaches.
arxiv.org/abs/2205.11726

9) “PoeLM: A Meter- and Rhyme-Controllable Language Model for Unsupervised Poetry Generation” (Findings), led by @aormazabalo
We propose an unsupervised approach to formal verse poetry generation based on control codes.
arxiv.org/abs/2205.12206
We propose an unsupervised approach to formal verse poetry generation based on control codes.
arxiv.org/abs/2205.12206

Thanks to all my awesome co-authors and see you all in Abu Dhabi!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



