
We suffered through curating and analysing thousands of benchmarks -- to better understand the (mis)measurement of AI! 📏🤖🔬
We cover all of #NLProc and #ComputerVision.
Now live at @NatureComms! nature.com/articles/s4146…
1/
We cover all of #NLProc and #ComputerVision.
Now live at @NatureComms! nature.com/articles/s4146…
1/

Benchmarks are crucial to measuring and steering AI progress.
Their number has become astounding.
Each has unique patterns of activity, improvement and eventual stagnation/saturation. Together they form the intricate story of global progress in AI. 🌐
2/
Their number has become astounding.
Each has unique patterns of activity, improvement and eventual stagnation/saturation. Together they form the intricate story of global progress in AI. 🌐
2/

We found a sizable portion of benchmarks have kind of reached saturation ("can't get better than this") or stagnation ("could get better, but we don't know how / nobody tries"). But still a lot of dynamic benchmarks as well!
3/
3/

How does activity and improvement develop over time and different domains? We mapped all benchmarks into an #RDF #KnowledgeGraph / ontology and devised a novel, highly condensed visualisation method.
Darker green means steeper progress. More chaotic than expected!
4/
Darker green means steeper progress. More chaotic than expected!
4/
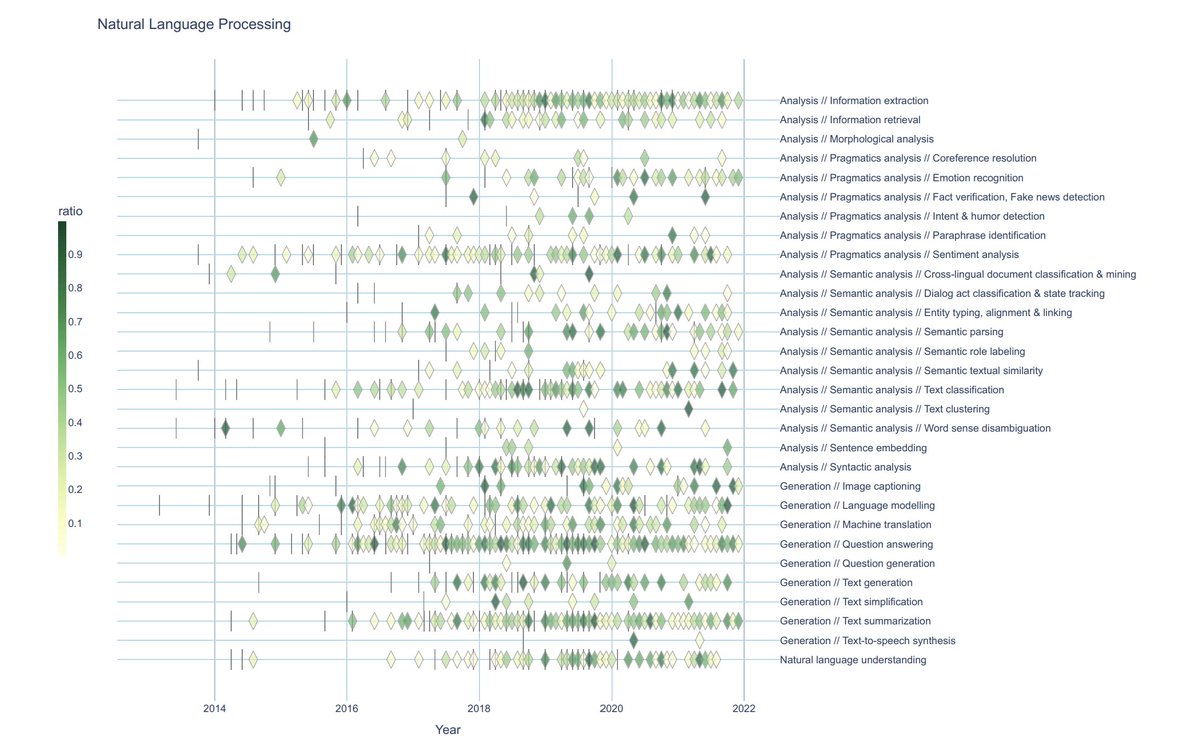
... And the lifecycle maps show the birth, life and death of benchmarks. 🌈☠️
5/
5/

Speaking of the life of a benchmark: It's hard. Most benchmark datasets are unpopular. 🥲
6/
6/

How to become more popular (as a benchmark dataset)? Traits correlated with popularity:
- versatile (cover more tasks, have more sub-benchmarks)
- have a dedicated leaderboard
- be created by people from top-institutions
7/
- versatile (cover more tasks, have more sub-benchmarks)
- have a dedicated leaderboard
- be created by people from top-institutions
7/

The biggest obstacle and limitation for our work is data availability.
This analysis was only possible by using data from the fabulous @paperswithcode. As a community, we should incentivize depositing results in paperswithcode more! Lots of potential added value.
8/
This analysis was only possible by using data from the fabulous @paperswithcode. As a community, we should incentivize depositing results in paperswithcode more! Lots of potential added value.
8/
• • •
Missing some Tweet in this thread? You can try to
force a refresh



