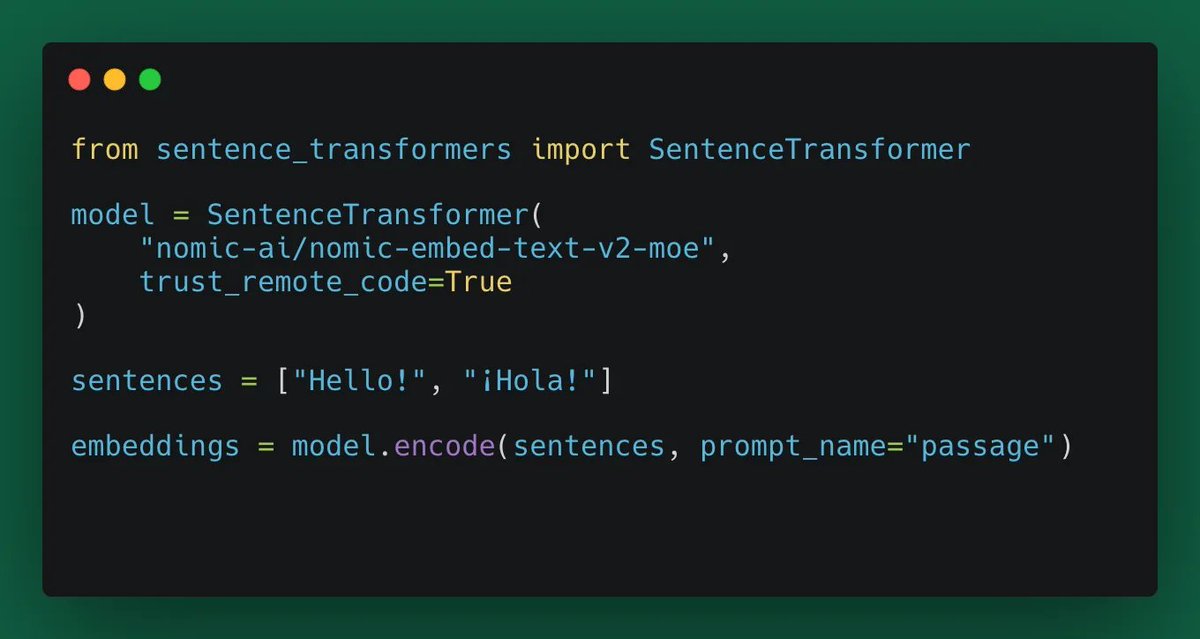
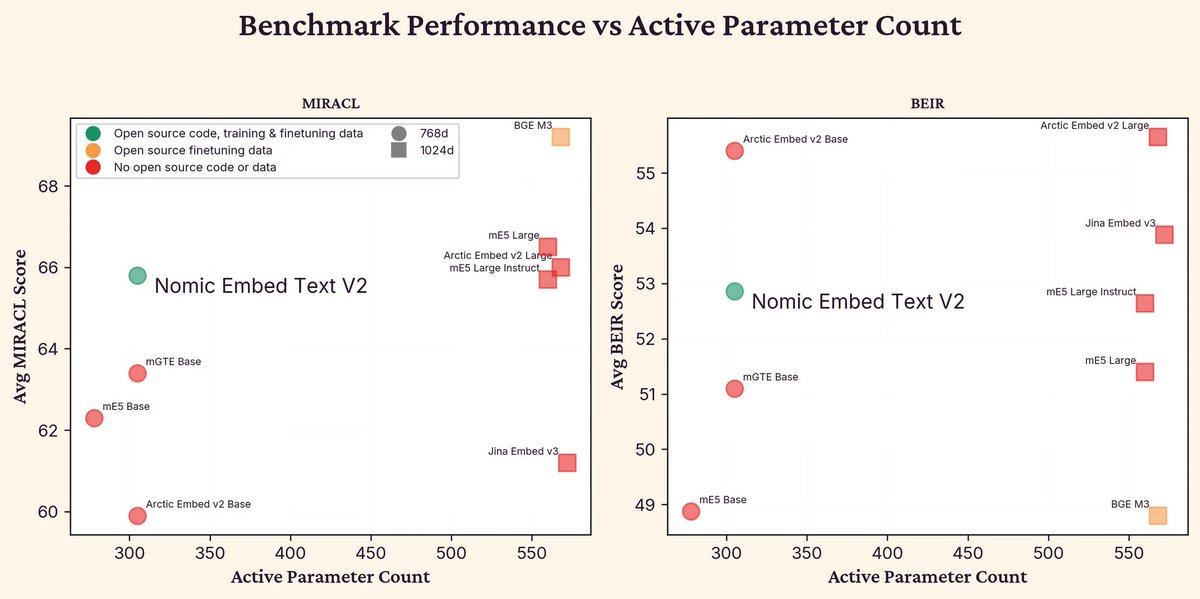
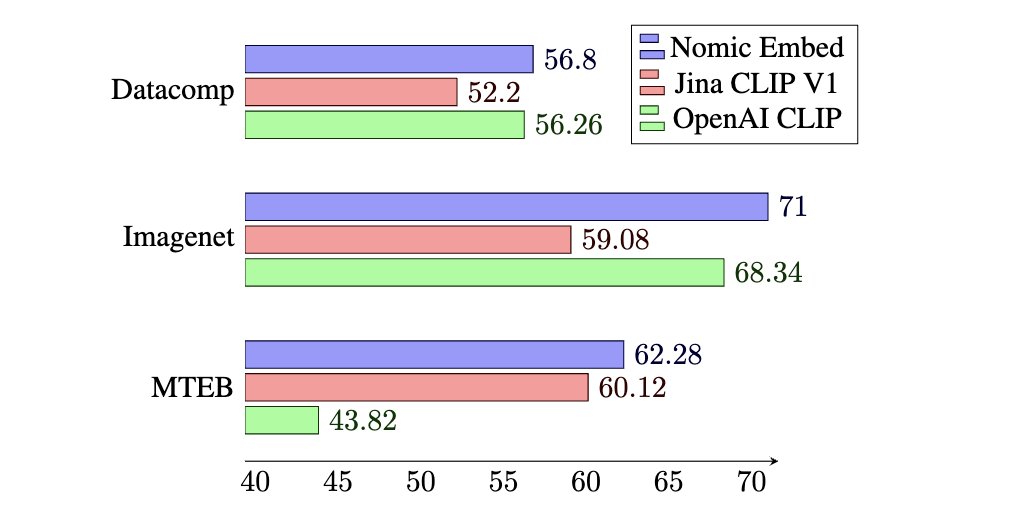
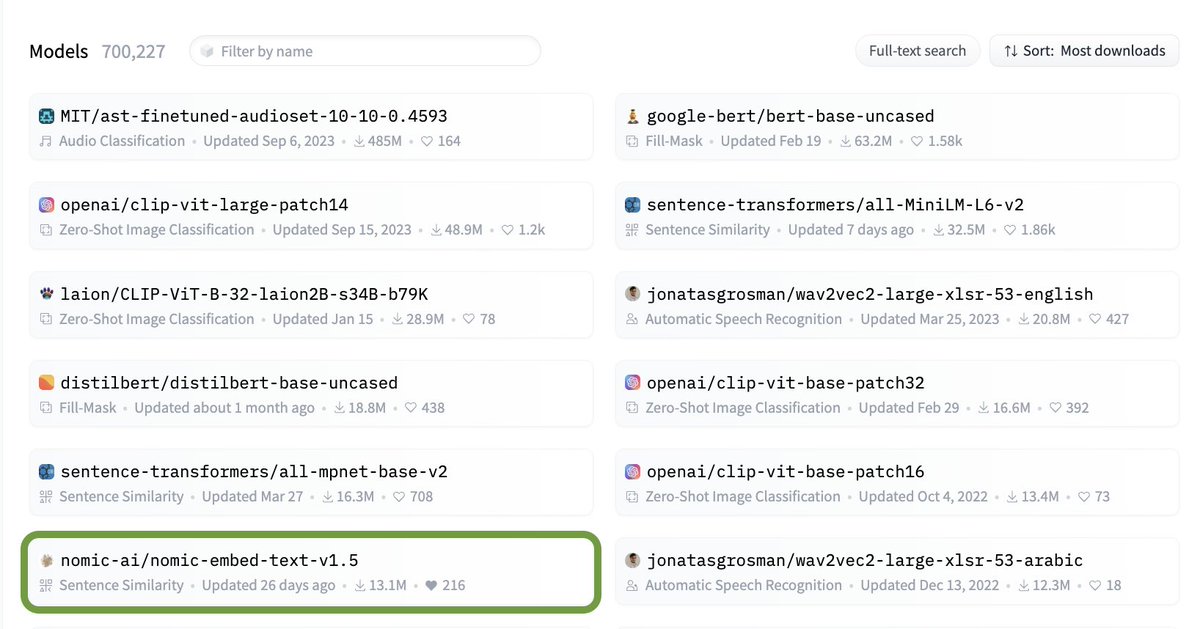
What are the latest research trends in AI?
Explore all NeurIPS submissions from 1987 to 2022 in Atlas.
atlas.nomic.ai/map/neurips
Explore all NeurIPS submissions from 1987 to 2022 in Atlas.
atlas.nomic.ai/map/neurips
Learn how it works and how to make it yourself👇
Each point is an accepted abstract at NeurIPS between 1987 and 2022.
Clusters of points represent research topics. For example, all papers about graph neural networks are here:
Each point is an accepted abstract at NeurIPS between 1987 and 2022.
Clusters of points represent research topics. For example, all papers about graph neural networks are here:
Atlas lets you interact with unstructured datasets over time. Filtering by submission year shows us how submissions to NeurIPS evolve:
80's and early 90's: Kernels, Speech Recognition and models of the brain.
90's-00's: RL, Clustering and Active Learning become popular.
80's and early 90's: Kernels, Speech Recognition and models of the brain.
90's-00's: RL, Clustering and Active Learning become popular.
2010's: Theory of DL, ConvNets, Causal Inference and Adversarial Attacks
2018-2022: Self supervised learning, Pruning, Bandit problems, 3D Deep learning
2018-2022: Self supervised learning, Pruning, Bandit problems, 3D Deep learning
Searching the map for `transformer` surfaces the prevalence of the architecture across research topics:
Language models, Vision, Speech, 3D modeling, RL, EEG, Pruning and compression.
Language models, Vision, Speech, 3D modeling, RL, EEG, Pruning and compression.

Bonus: A map of just 2022 accepted submissions:
atlas.nomic.ai/map/neurips_20…
atlas.nomic.ai/map/neurips_20…
@hen_str Would love to see this as the paper explorer for the NeurIPS 2023 Virtual Conference :)
Huge thanks to @Yuvaaa___ for facilitating the data collection and cleaning this past summer while interning at Nomic!
• • •
Missing some Tweet in this thread? You can try to
force a refresh