Machine learning predictive uncertainty estimates are often unreliable—data shift makes things worse!
How can you audit the uncertainty of an ML prediction, even with biased data?
A 🧵 w/ @DrewPrinster on the JAWS approach in #NeurIPS2022 paper w/ fab @anqi_liu33 @DrewPrinster
How can you audit the uncertainty of an ML prediction, even with biased data?
A 🧵 w/ @DrewPrinster on the JAWS approach in #NeurIPS2022 paper w/ fab @anqi_liu33 @DrewPrinster
https://twitter.com/DrewPrinster/status/1597620373209878530
Why generate uncertainty intervals and enable real time audits?
Build user trust arxiv.org/pdf/1805.11783… proceedings.mlr.press/v89/schulam19a…
In decision support apps, reduce false alerts pubmed.ncbi.nlm.nih.gov/28841550/
Enable safety assessment inhttps://www.nejm.org/doi/full/10.1056/NEJMc2104626
Build user trust arxiv.org/pdf/1805.11783… proceedings.mlr.press/v89/schulam19a…
In decision support apps, reduce false alerts pubmed.ncbi.nlm.nih.gov/28841550/
Enable safety assessment inhttps://www.nejm.org/doi/full/10.1056/NEJMc2104626
Background: #conformalprediction is becoming popular for predictive interval generation with a coverage guarantee
Coverage: Predictive interval contains true label with high probability (i.e., predictive confidence intervals are valid)
Assumption: Exchangeable (or, IID) data
Coverage: Predictive interval contains true label with high probability (i.e., predictive confidence intervals are valid)
Assumption: Exchangeable (or, IID) data
Prior work addresses some limitations of standard conformal methods:
Jackknife+: Beneficial compromise of conformal methods’ statistical or computational inefficiencies (Barber et al., 2021)
Weighted conformal: Extends conformal to covariate shift (Tibshirani et al., 2019)
Jackknife+: Beneficial compromise of conformal methods’ statistical or computational inefficiencies (Barber et al., 2021)
Weighted conformal: Extends conformal to covariate shift (Tibshirani et al., 2019)
However:
- Weighted conformal does not extend jackknife+ to covariate shift
- Jackknife+ is computationally demanding (requires N retrained models)
- Predictive intervals aren’t often actionable—estimates of error probability can be more useful!
JAWS addresses these challenges:
- Weighted conformal does not extend jackknife+ to covariate shift
- Jackknife+ is computationally demanding (requires N retrained models)
- Predictive intervals aren’t often actionable—estimates of error probability can be more useful!
JAWS addresses these challenges:
(Contribution 1) JAW: JAckknife+ with likelihood ratio Weights → extends jackknife+ coverage guarantee to covariate shift 

(Contribution 2) JAWA: Sequence of computationally efficient approximations of JAW with higher-order influence functions → asymptotic coverage guarantee under covariate shift

(Contribution 3) Error assessment: General approach to repurposing predictive interval generating methods to error assessment, based on user’s error criterion of interest (for instance, the user wants the chance of false negative or missed diagnosis to be < 5%)

(Contribution 4) Experiments: Demonstrate superior empirical performance of JAWS over conformal and jackknife+ baselines on a variety of biased, real-world datasets
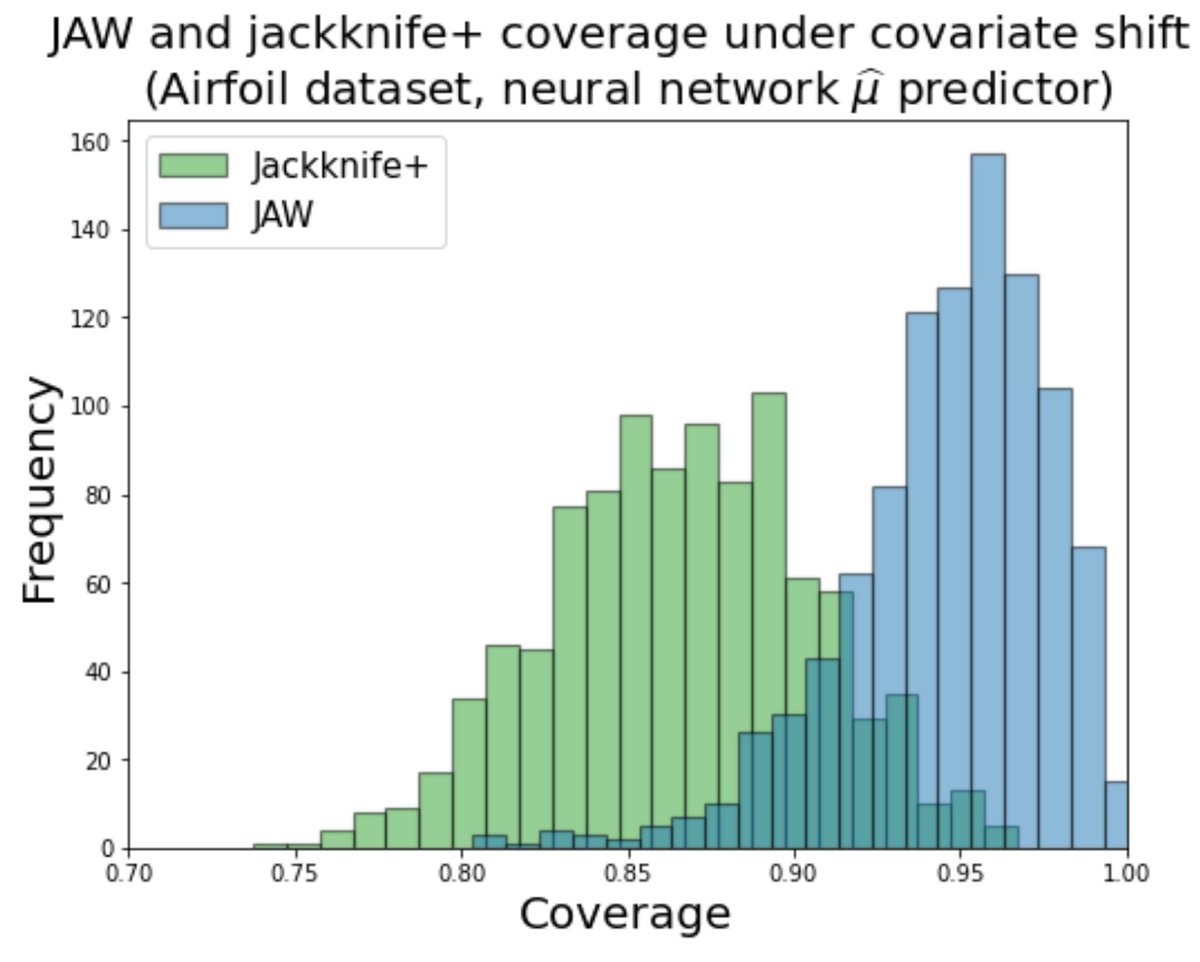
Here, JAW maintains coverage at target level (90%) under covariate shift while jackknife+ does not👇🏽
Thoughts?
Here, JAW maintains coverage at target level (90%) under covariate shift while jackknife+ does not👇🏽
Thoughts?
• • •
Missing some Tweet in this thread? You can try to
force a refresh