Entender os fundamentos de Git é necessário para quem não quer se deixar dominar pela ferramenta.
Nesta 🧵 vou tentar explicar as estruturas fundamentais do Git e como estas se relacionam com os comandos que usamos no dia-dia.
Nesta 🧵 vou tentar explicar as estruturas fundamentais do Git e como estas se relacionam com os comandos que usamos no dia-dia.

Os principais componentes do Git são:
.git/objects
.git/refs
HEAD
.git/objects
.git/refs
HEAD

Começamos pelo Object database, que é basicamente onde o Git armazena todos os seus objetos.

Mas que tipo de database é este? SQL? NoSQL?
Vamos primeiro persistir um objeto utilizando o comando `git hash-object`, que:
* permite input do STDIN ou arquivo normal
* retorna uma hash SHA-1
* persiste com a opção `-w`
Vamos primeiro persistir um objeto utilizando o comando `git hash-object`, que:
* permite input do STDIN ou arquivo normal
* retorna uma hash SHA-1
* persiste com a opção `-w`

Podemos reparar que Git persistiu nosso objeto em .git/objects como era esperado, utilizando a hash que foi devolvida como "chave" de acesso

Se temos a hash, conseguimos resgatar o valor original do objeto?
Sim, com o comando `git cat-file`.
Temos no Git, então, um database baseado em chave-valor, com suas chaves em formato SHA-1.
Sim, com o comando `git cat-file`.
Temos no Git, então, um database baseado em chave-valor, com suas chaves em formato SHA-1.

O comando `cat-file` permite passar a opção `-t` que devolve o tipo do objeto, que neste caso, é um blob.

Uma vez com os blobs persistidos, como podemos agrupá-los, adicionar metadados e criar snapshots?
Precisamos promover estes blobs para um uma área de "Stage", com o comando `git update-index`
Precisamos promover estes blobs para um uma área de "Stage", com o comando `git update-index`


Podemos adicionar quantos blobs quisermos ao índice utilizando o `update-index`.
Mas como agrupá-los para que sejam promovidos? O Git permite criar uma "árvore" com esses blobs, através do comando `write-tree`.
Note que novos objetos foram criados, que tipos são esses objetos?
Mas como agrupá-los para que sejam promovidos? O Git permite criar uma "árvore" com esses blobs, através do comando `write-tree`.
Note que novos objetos foram criados, que tipos são esses objetos?


Estes objetos são do tipo "tree", que servem para agrupar diferentes blobs e inclusive outras trees quando utilizada a opção `prefix`


E se quisermos adicionar metadados a partir das trees, como por exemplo o autor do trabalho, a data e uma mensagem descritiva?
Sim, estamos falando do comando `git commit-tree`, que promove uma tree de modo a que esta possa ter metadados.
Sim, estamos falando do comando `git commit-tree`, que promove uma tree de modo a que esta possa ter metadados.


Commits também são objetos, e portanto, possuem uma chave SHA-1 para representar cada commit.


É possível também criar commits com referência a outros commits (parents).
Repare que o objeto commit tem referência para a tree e para o parent (outro commit criado a partir dele).
Repare que o objeto commit tem referência para a tree e para o parent (outro commit criado a partir dele).


Como percorrer toda a "rede" de commits a partir do último commit, indo pelos parents, trees até chegar nos blobs?
O comando `git log <sha1>` faz exatamente isso, percorrendo todo o grafo e trazendo tudo de acordo com a linha do tempo.
O comando `git log <sha1>` faz exatamente isso, percorrendo todo o grafo e trazendo tudo de acordo com a linha do tempo.

Git é baseado em grafos.
Manipular objetos no Git é como manipular ponteiros em grafos.
Blobs representam arquivos. Trees representam conjuntos de blobs e outras trees. Commits representam metadados com referência a trees e outros commits.
Manipular objetos no Git é como manipular ponteiros em grafos.
Blobs representam arquivos. Trees representam conjuntos de blobs e outras trees. Commits representam metadados com referência a trees e outros commits.

Executar toda hora `git log <sha1>` não é eficiente pois temos de decorar as hashes.
Mas Git traz uma facilidade para isto, que são referências para commits, que ficam em .git/refs.
Através do comando `update-ref`, criamos referências que são basicamente commits "com nomes".
Mas Git traz uma facilidade para isto, que são referências para commits, que ficam em .git/refs.
Através do comando `update-ref`, criamos referências que são basicamente commits "com nomes".


Soa familiar? Estamos falando de branches.


Mas o quê acontece se não passar argumento (sha-1) para o comando `git log`?
Como o Git sabe que a minha branch atual é a "main"?
Como o Git sabe que a minha branch atual é a "main"?

Acertou, é aqui que entra o tal do HEAD.
Com o comando `git symbolic-ref` podemos mudar o ponteiro do HEAD, que é uma referência simbólica para a branch atual de trabalho.
O HEAD pode ser qualquer branch ou até mesmo um SHA-1 (no modo detached)
Com o comando `git symbolic-ref` podemos mudar o ponteiro do HEAD, que é uma referência simbólica para a branch atual de trabalho.
O HEAD pode ser qualquer branch ou até mesmo um SHA-1 (no modo detached)



Trocar o HEAD é uma simples chamada ao `symbolic-ref`.
Neste exemplo, fico intercalando entre a branch "main" e branch "fix".
Neste exemplo, fico intercalando entre a branch "main" e branch "fix".

Agora que sabemos que tudo em Git é manipulação de ponteiros, vamos associar este conhecimento com os comandos do dia-dia.
Começando pelo `git add`, que basicamente é a junção do `hash-object` com `update-index`.
Começando pelo `git add`, que basicamente é a junção do `hash-object` com `update-index`.

O `git commit` é basicamente o `write-tree` (uma vez que há objetos no index) seguido do `commit-tree`, que adiciona informações como autor, date e message.



Já o `git checkout` é literalmente o `symbolic-ref`, que muda o ponteiro (branch) do HEAD.
Com algumas opções adicionais que trazem mais versatilidade.
Com algumas opções adicionais que trazem mais versatilidade.


O comando `git reset` permite mudar o ponteiro da branch, tal como o `update-ref`.
Sem a opção `--hard`, todos os arquivos que divergem ficam em stage a espera de novo commit.
Sem a opção `--hard`, todos os arquivos que divergem ficam em stage a espera de novo commit.



E o merge?
Bem, é super tranquilo entender. Supondo que temos uma branch main e outra "fix", onde fix está 1 commit à frente.
O merge basicamente faz move a branch main para o mesmo commit da branch fix (fast-forward).
Bem, é super tranquilo entender. Supondo que temos uma branch main e outra "fix", onde fix está 1 commit à frente.
O merge basicamente faz move a branch main para o mesmo commit da branch fix (fast-forward).


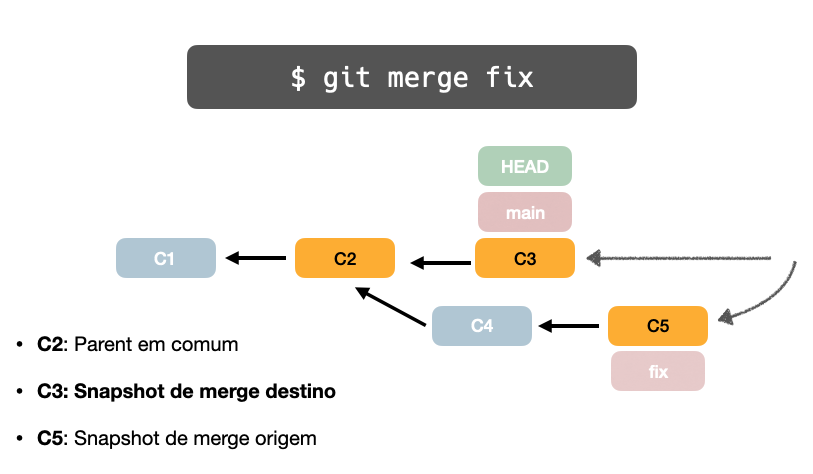
E quando a main tem algum commit à frente da branch fix? Neste caso, não é possível fazer fast-forward.

Mas o Git é bem inteligente e trata desta forma:
* Tira snapshot do parent em comum com ambas as branches
* Tira snapshot do commit da branch de destino
* Tira snapshot do commit da branch de origem
E, por fim, cria um commit adicional de "merge". Sim, é o "three-way" merge.
* Tira snapshot do parent em comum com ambas as branches
* Tira snapshot do commit da branch de destino
* Tira snapshot do commit da branch de origem
E, por fim, cria um commit adicional de "merge". Sim, é o "three-way" merge.


Onde entra o cherry-pick? Com cherry-pick de um commit da branch main, o Git:
* move o ponteiro da branch fix
* aplica o commit da branch main como último commit na branch fix
* move o ponteiro da branch fix
* aplica o commit da branch main como último commit na branch fix



E quando queremos aplicar as mudanças por cima de outra branch?
Entra o rebase.
Neste cenário, com rebase a partir da branch fix, basicamente:
* muda o ponteiro p/ o HEAD da main
* faz cherry-pick dos commits q sobraram
* por último muda ponteiro para o último do cherry-pick
Entra o rebase.
Neste cenário, com rebase a partir da branch fix, basicamente:
* muda o ponteiro p/ o HEAD da main
* faz cherry-pick dos commits q sobraram
* por último muda ponteiro para o último do cherry-pick




E as branches remote?
Também são referências.
O comando `git fetch` faz download da branch do server e sincroniza com uma branch "upstream" relacionada à tracking branch (local).
Também são referências.
O comando `git fetch` faz download da branch do server e sincroniza com uma branch "upstream" relacionada à tracking branch (local).



Por serem branches, é possível fazer merge a partir das branches upstream com as locais.
Geralmente, por estarem sempre "atrás", merges com branches upstream são feitos no modo fast-forward.
O comando `git pull` facilita a vida, fazendo fetch + merge para nós.
Geralmente, por estarem sempre "atrás", merges com branches upstream são feitos no modo fast-forward.
O comando `git pull` facilita a vida, fazendo fetch + merge para nós.



"Okay, fiz meu trabalho e agora quero mandar de volta para o server. Como atualizo a branch upstream?"
Não precisa, o comando `git push`, além de atualizar o server, também sincroniza a branch tracking local com a upstream.
Não precisa, o comando `git push`, além de atualizar o server, também sincroniza a branch tracking local com a upstream.


Assim como branches, tags também são referências com "nome".
Mas são imutáveis, ou seja, para mudar a referência de uma tag é preciso apagá-la e criar outra com mesmo nome.
Mas são imutáveis, ou seja, para mudar a referência de uma tag é preciso apagá-la e criar outra com mesmo nome.


Como o @coproduto destacou, nesta thread foram apresentados os comandos "plumbing", que foram os building blocks do Git, e como se relacionam com os comandos "porcelain", usados no dia-dia.
https://twitter.com/coproduto/status/1599260052783001600?s=20&t=sEGQ1uFh4Ky55Cik6YDcIA
@coproduto E pra quem tiver interesse, o próprio guia oficial do Git é bem completo, se ler os primeiros capítulos já cobre muita coisa boa para dominar mais o Git.
Com destaque ao capítulo 10 que fala dos "internals" que eu trouxe à thread.
git-scm.com/book/en/v2/Get…
Com destaque ao capítulo 10 que fala dos "internals" que eu trouxe à thread.
git-scm.com/book/en/v2/Get…
• • •
Missing some Tweet in this thread? You can try to
force a refresh