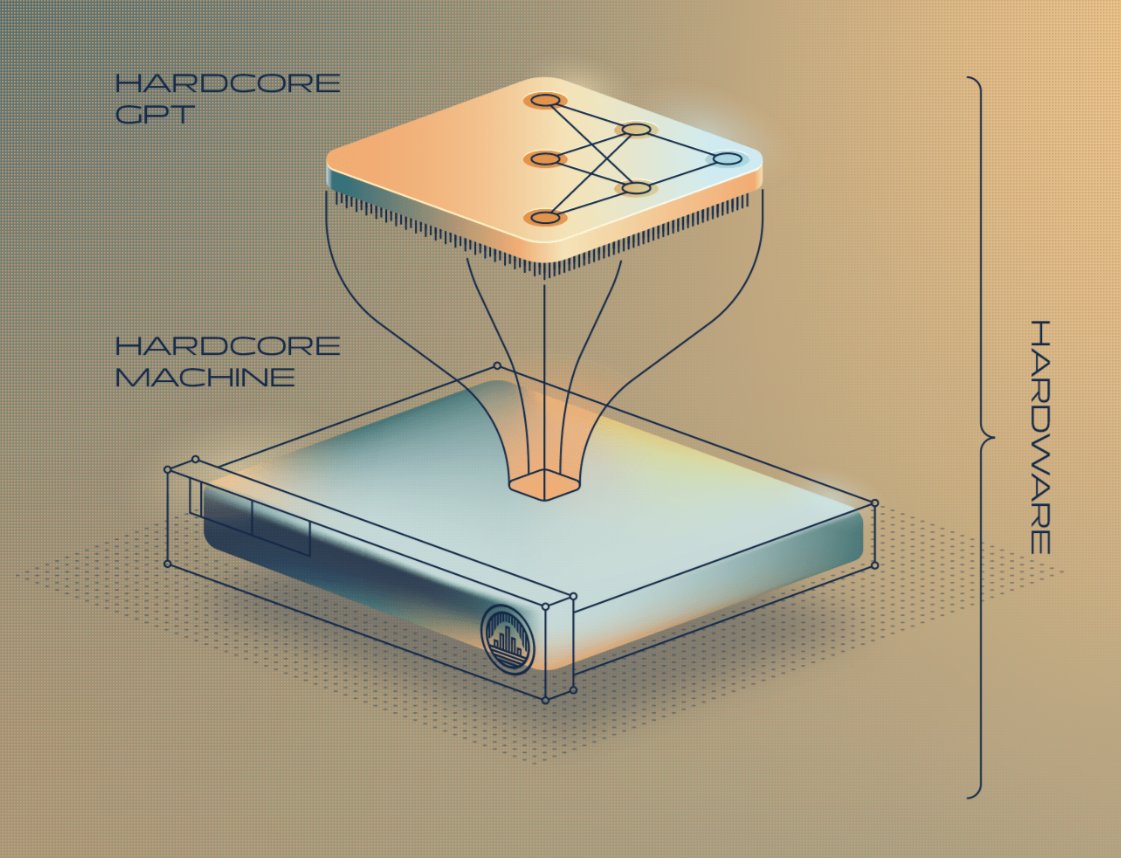
Breve hilo de lo que está por venir. ¿Veis esta imagen de aquí? Es el resultado de un modelo de difusión generando una imagen nueva de un astronauta montando a caballo. ¿Sorprendente? Bueno, ya no tanto. 2022 ha sido intenso.
Mirad ahora el siguiente tweet.
Mirad ahora el siguiente tweet.
Aquí va otra imagen generada con el mismo proceso anterior, peeeero, esta es más rara de interpretar.
¿Por qué? Bueno, porque no está pensada para ser vista sino escuchada.
Esta "imagen" es un espectrograma, una forma de representar el sonido. ¿Cuál ha sido su prompt?
¿Por qué? Bueno, porque no está pensada para ser vista sino escuchada.
Esta "imagen" es un espectrograma, una forma de representar el sonido. ¿Cuál ha sido su prompt?
El prompt es "funk bassline with a jazzy saxophone solo" y el resultado (al interpretar la información de dicho espectrograma) suena así 👇
Efectivamente, este proyecto se llama Riffusion y es llevar la teoría de Stable Diffusion (generación de imágenes con texto) a la generación de música.
Aquí tenéis un par de ejemplos más de su web 👇
Aquí tenéis un par de ejemplos más de su web 👇
Y al igual que cuando trabajamos con imágenes se puede hacer diferentes interpolaciones para pasar de un estilo a otro, con el audio también se puede.
Aquí podéis escuchar parte de la transición desde el tecleo de una persona a un jazz :)
Aquí podéis escuchar parte de la transición desde el tecleo de una persona a un jazz :)
Echadle un ojo a la web del proyecto que tiene información muy chula explicando su funcionamiento.
https://twitter.com/_akhaliq/status/1603411250389700611?s=20&t=EgurCD1OYKt_zPdlO6rDUg
• • •
Missing some Tweet in this thread? You can try to
force a refresh