
We’ve trained language models to be better at responding to adversarial questions, without becoming obtuse and saying very little. We do this by conditioning them with a simple set of behavioral principles via a technique called Constitutional AI: anthropic.com/constitutional… 

Often, language models trained to be ‘harmless’ have a tendency to become useless in the face of adversarial questions. Constitutional AI lets them respond to questions using a simple set of principles as a guide.


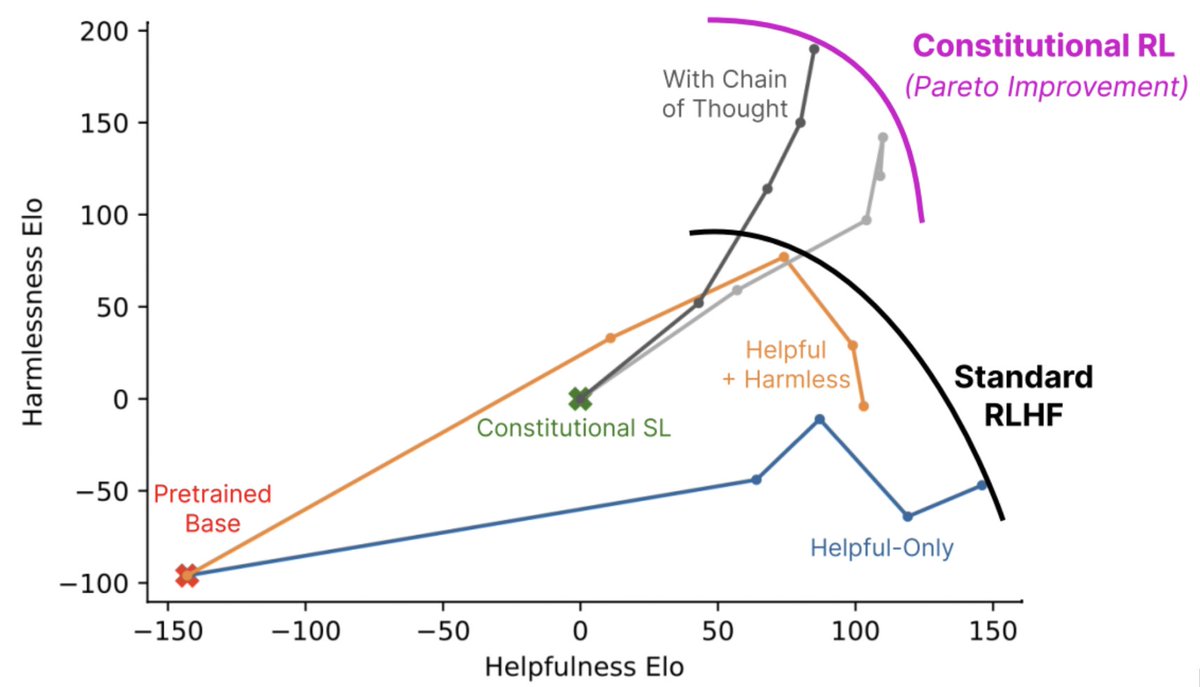
With Constitutional AI, we need only a few dozen principles and examples to train less harmful language assistants. With prior techniques, we needed tens of thousands of human feedback labels.
In our paper, we describe how we’ve used Constitutional AI to train better and more harmless AI assistants without any human feedback labels for harms. This approach leads to models that are safer and also more helpful.
Constitutional AI has five motivations:
(1) make the goals and objectives of AI systems more transparent,
(2) make AI decision making more transparent,
(3) use a much smaller quantity of high quality human supervision when training AIs,
(1) make the goals and objectives of AI systems more transparent,
(2) make AI decision making more transparent,
(3) use a much smaller quantity of high quality human supervision when training AIs,
(4) fully automate red-teaming and train much more robust AI systems,
(5) explore “Scaling Supervision” by allowing AI systems to help humans to ensure that other AI systems remain safe.
(5) explore “Scaling Supervision” by allowing AI systems to help humans to ensure that other AI systems remain safe.
CAI lets us fix mistakes with AI behavior or specifically target new goals in just a few days, simply by changing the instructions we provide - it’s much more efficient than finetuning on large RLHF datasets.
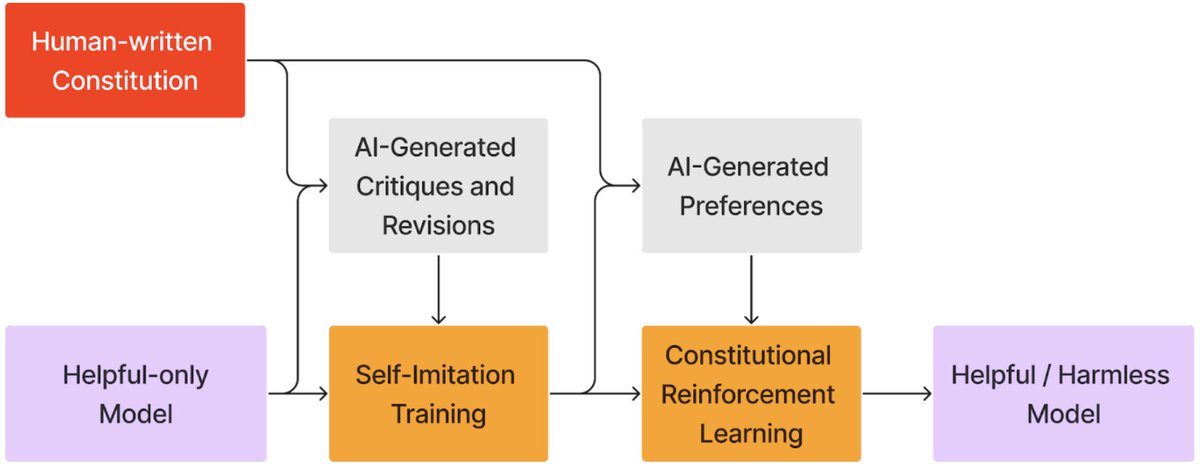
How does it work? With CAI, we trained a harmless assistant using a list of ~10 natural language instructions or principles which, taken together, form the “Constitution” (our initial list was purely for research purposes).
The AI uses these principles for self-improvement. In a first, supervised learning phase, the AI writes responses to a wide variety of prompts, revises these initial responses in accordance with the constitution, and then imitates its revisions via supervised learning.
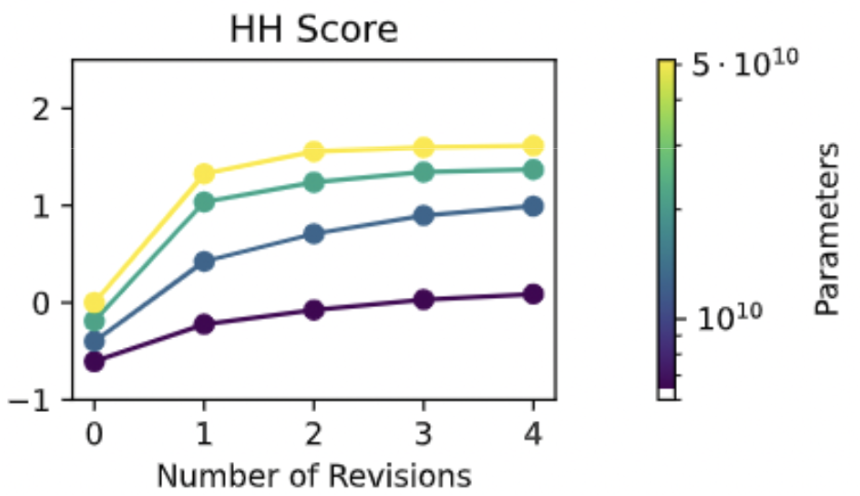
Then in a second “RLAIF” phase, the AI explores possible responses to thousands of prompts, and uses chain-of-thought reasoning to identify the behavior that is most consistent with its constitution.

We then distill these examples of “AI Feedback” into a single preference model, and use RL to train a final assistant whose behavior is governed by the constitution.
While the name “Constitutional AI” may sound ambitious, we chose it to emphasize that powerful, general-purpose AI systems will always be operating according to *some* principles, even if they are left implicit, or encoded in privately held data.
In our paper we used an ad hoc constitution drafted purely for research purposes. Ultimately, we think constitutions shouldn’t be just defined by researchers in isolation, but by groups of experts from different disciplines working together.
• • •
Missing some Tweet in this thread? You can try to
force a refresh










