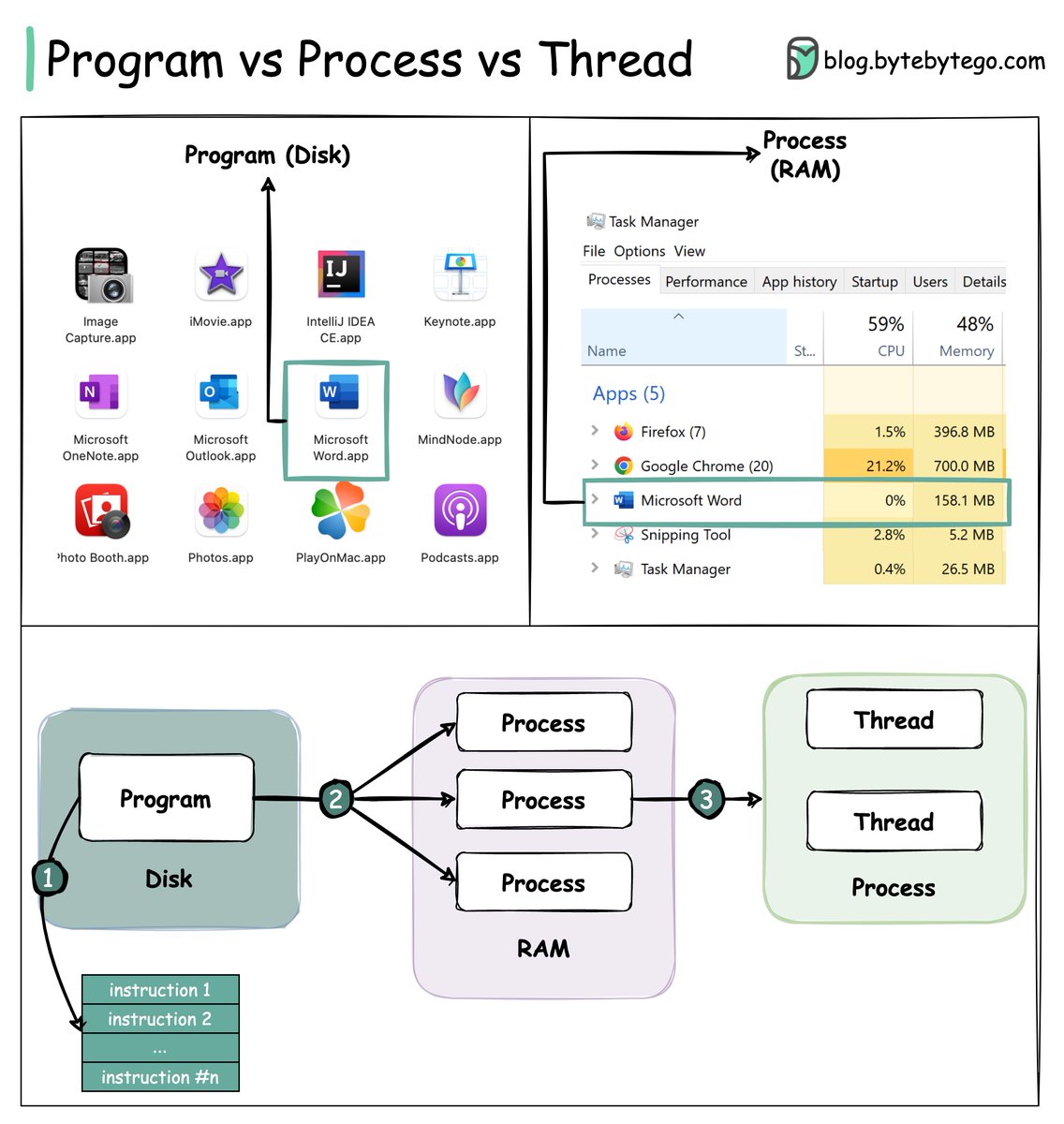
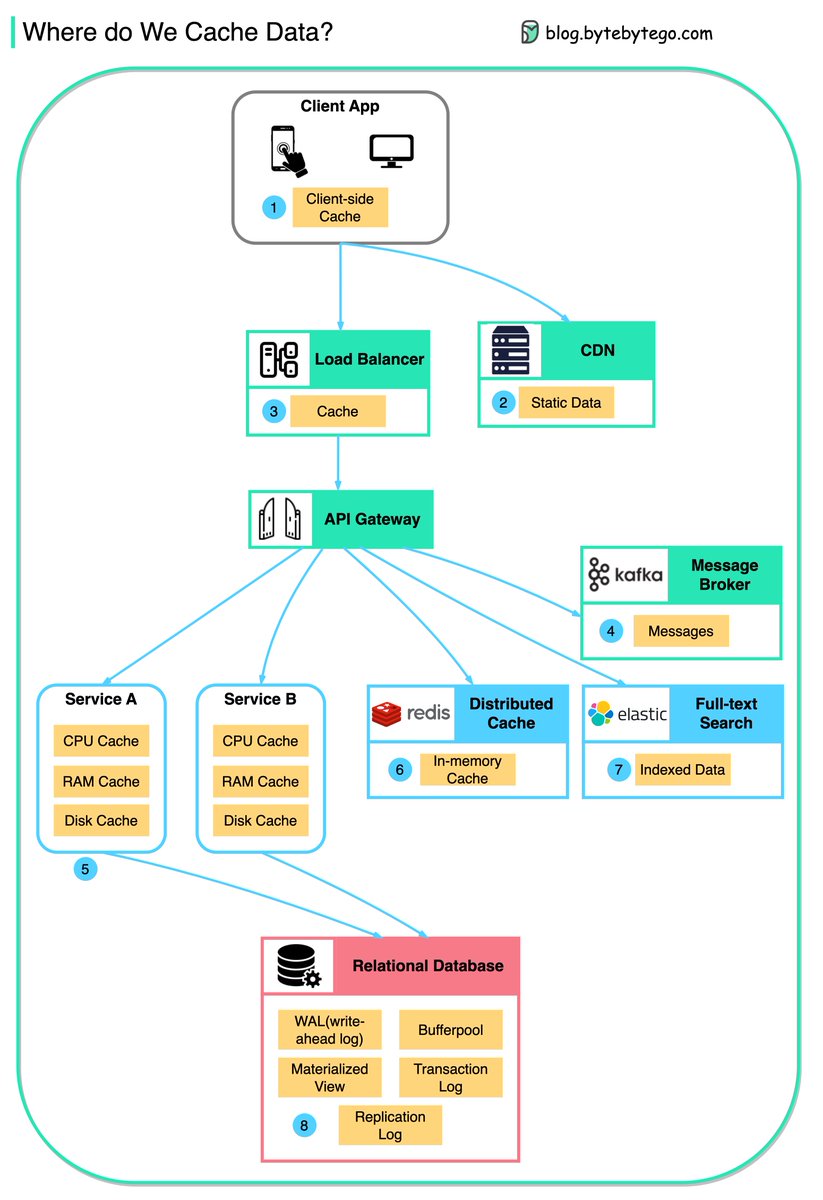
/1 Data is cached everywhere, from the front end to the back end!
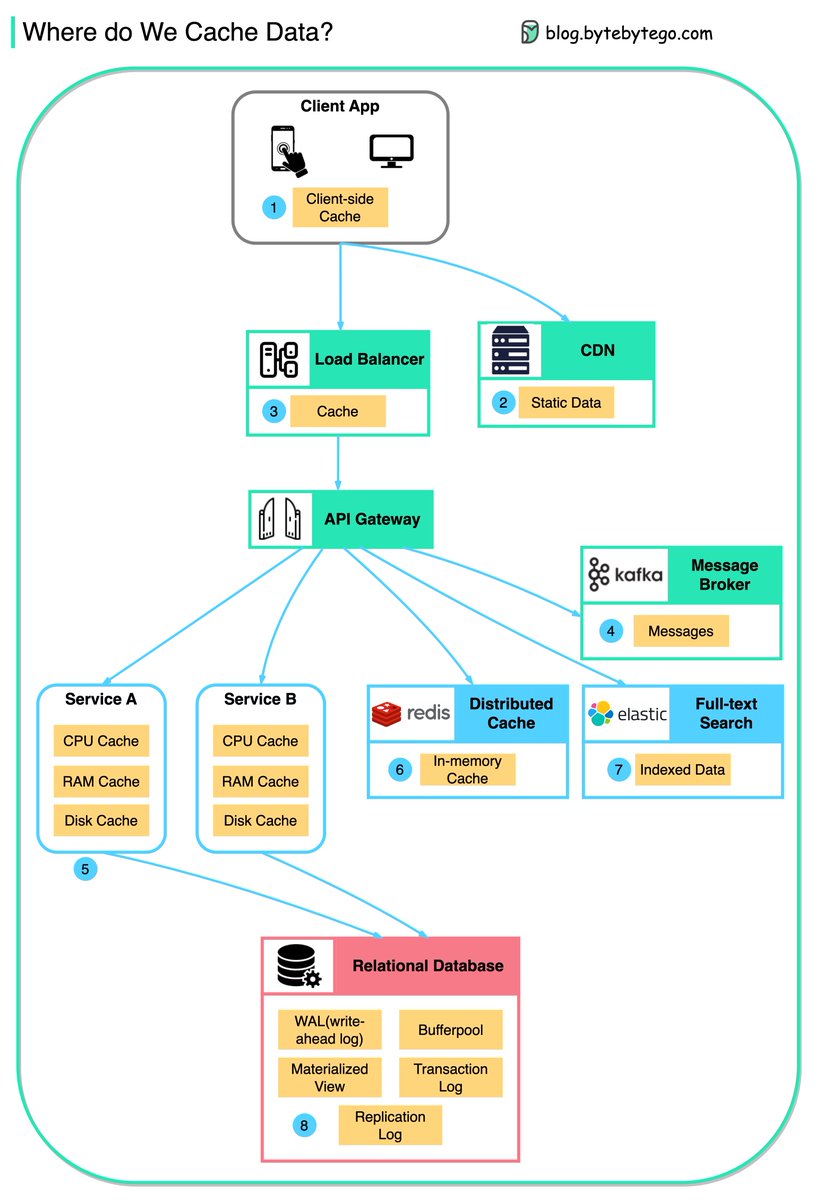
This diagram illustrates where we cache data in a typical architecture.
This diagram illustrates where we cache data in a typical architecture.
/2 There are 𝐦𝐮𝐥𝐭𝐢𝐩𝐥𝐞 𝐥𝐚𝐲𝐞𝐫𝐬 along the flow.
🔹 1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time; we request data again, and the client app tries to retrieve the data from the browser cache first.
🔹 1. Client apps: HTTP responses can be cached by the browser. We request data over HTTP for the first time; we request data again, and the client app tries to retrieve the data from the browser cache first.
/3
🔹 2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
🔹 3. Load Balancer: The load Balancer can cache resources as well.
🔹 2. CDN: CDN caches static web resources. The clients can retrieve data from a CDN node nearby.
🔹 3. Load Balancer: The load Balancer can cache resources as well.
/4
🔹 4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
🔹 4. Messaging infra: Message brokers store messages on disk first, and then consumers retrieve them at their own pace. Depending on the retention policy, the data is cached in Kafka clusters for a period of time.
/5
🔹 5. Services: There are multiple layers of cache in a service. If the data is not cached in CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
🔹 5. Services: There are multiple layers of cache in a service. If the data is not cached in CPU cache, the service will try to retrieve the data from memory. Sometimes the service has a second-level cache to store data on disk.
/6
🔹 6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
🔹 6. Distributed Cache: Distributed cache like Redis hold key-value pairs for multiple services in memory. It provides much better read/write performance than the database.
/7
🔹 7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
🔹 7. Full-text Search: we sometimes need to use full-text searches like Elastic Search for document search or log search. A copy of data is indexed in the search engine as well.
/8
🔹 8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View
🔹 8. Database: Even in the database, we have different levels of caches:
- WAL(Write-ahead Log): data is written to WAL first before building the B tree index
- Bufferpool: A memory area allocated to cache query results
- Materialized View
/9
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
- Transaction log: record all the transactions and database updates
- Replication Log: used to record the replication state in a database cluster
/10 👉 Over to you: With the data cached at so many levels, how can we guarantee the 𝐬𝐞𝐧𝐬𝐢𝐭𝐢𝐯𝐞 𝐮𝐬𝐞𝐫 𝐝𝐚𝐭𝐚 is completely erased from the systems?
Subscribe to our weekly newsletter to learn something new every week: bit.ly/3FEGliw
Subscribe to our weekly newsletter to learn something new every week: bit.ly/3FEGliw
/11 I hope you've found this thread helpful.
Follow me @alexxubyte for more.
Like/Retweet the first tweet below if you can:
Follow me @alexxubyte for more.
Like/Retweet the first tweet below if you can:
https://twitter.com/alexxubyte/status/1604880509086994436
• • •
Missing some Tweet in this thread? You can try to
force a refresh