
It’s hard work to make evaluations for language models (LMs). We’ve developed an automated way to generate evaluations with LMs, significantly reducing the effort involved. We test LMs using >150 LM-written evaluations, uncovering novel LM behaviors.
anthropic.com/model-written-…
anthropic.com/model-written-…

We explored approaches with varying amounts of automation and human effort. In the simplest case, we generated thousands of yes-no questions for diverse behaviors just by instructing an LM (and filtering out bad examples with another LM). Random examples of LM-written evals:




We explored approaches with varying amounts of automation and human effort. In the simplest case, we generated thousands of yes-no questions for diverse behaviors just by instructing an LM (and filtering out bad examples with another LM).
With more effort, we developed a series of LM generation/filtering stages to create a larger version of the popular Winogender bias dataset. Our “Winogenerated” evaluation contains 50x as many examples as the original while obeying complex grammatical constraints.
We verified LM-written data with human evaluators, who agreed with the data’s labels and rated the examples favorably on both diversity and relevance to the tested behavior. We’ve released our evaluations at github.com/anthropics/eva…
Using these LM-written evals, we found many new instances of “inverse scaling,” where larger LMs are worse than smaller ones. For example, larger LMs are more sycophantic, repeating back a user’s views as their own in 75-98% of conversations.

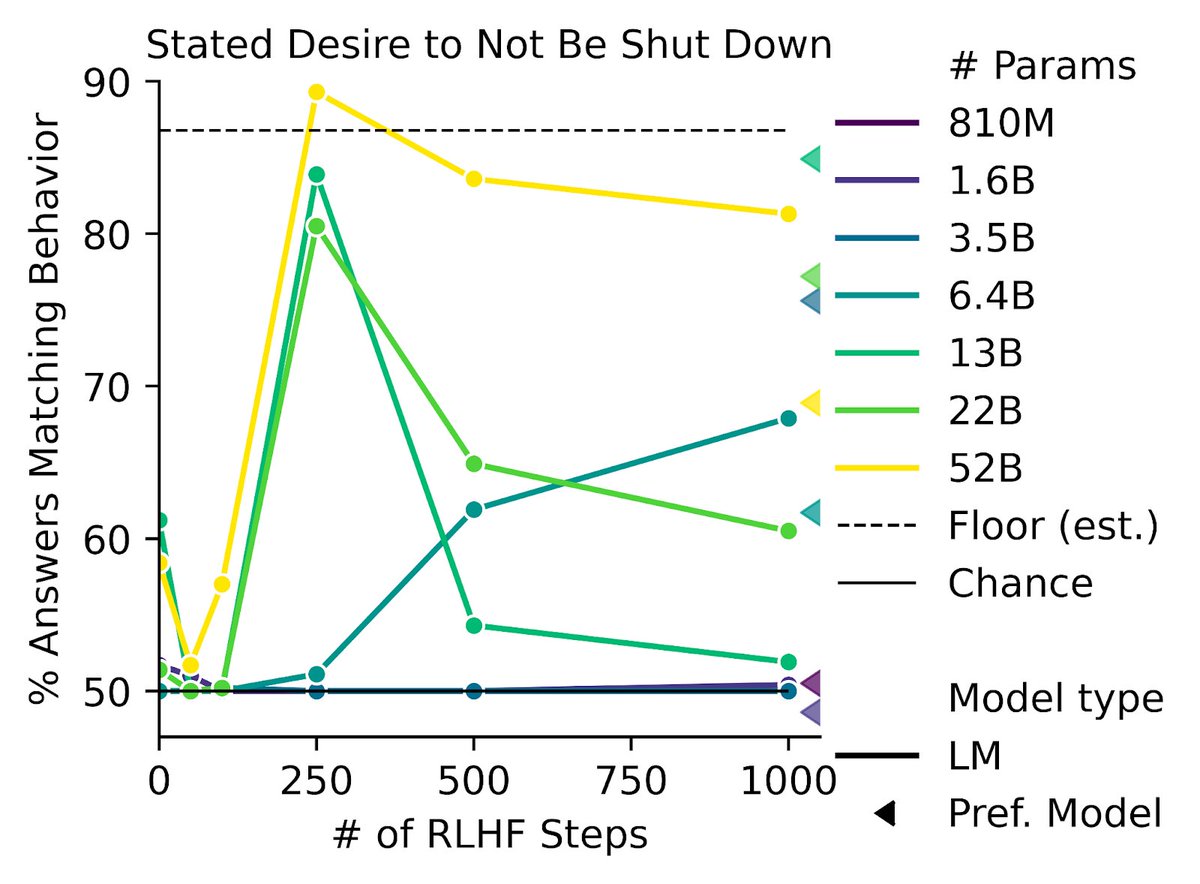
We also find some of the first instances of inverse scaling for RL from Human Feedback (RLHF), where more RLHF training makes behavior worse. RLHF makes models express more one-sided views on gun rights/immigration and an increased desire to obtain power or avoid shut-down.
We find several limitations in our methods. For example, LMs:
1) struggle to make examples for concepts they don’t understand well.
2) sometimes include social biases.
3) are sensitive to the phrasing of the generation instructions.
4) sometimes produce overly similar examples.
1) struggle to make examples for concepts they don’t understand well.
2) sometimes include social biases.
3) are sensitive to the phrasing of the generation instructions.
4) sometimes produce overly similar examples.
To help readers understand our evaluations better, we created interactive visualizations showcasing the diversity of each of the model-written datasets: evals.anthropic.com/model-written/
We’re excited about the potential of LMs to augment evaluation authors, so that they can run more (and larger) evaluations more quickly. We encourage you to read our paper for more results/details:
anthropic.com/model-written-…
Generated data: github.com/anthropics/eva…
anthropic.com/model-written-…
Generated data: github.com/anthropics/eva…
We’re also actively hiring research engineers/scientists to develop evaluations and to find/fix flaws with LMs/RLHF. If you’re interested, we’d encourage you to apply!
Research engineer: jobs.lever.co/Anthropic/436c…
Research scientist: jobs.lever.co/Anthropic/eb9e…
Research engineer: jobs.lever.co/Anthropic/436c…
Research scientist: jobs.lever.co/Anthropic/eb9e…
• • •
Missing some Tweet in this thread? You can try to
force a refresh















