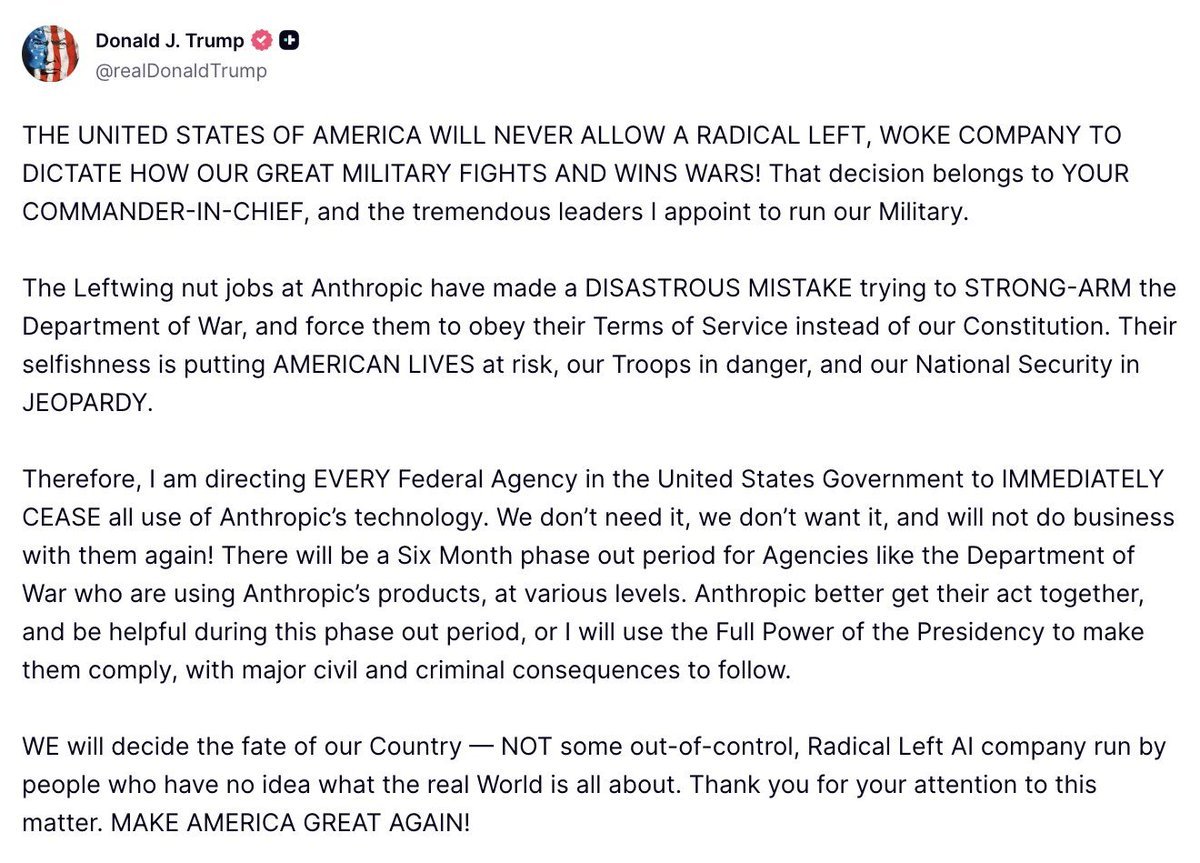
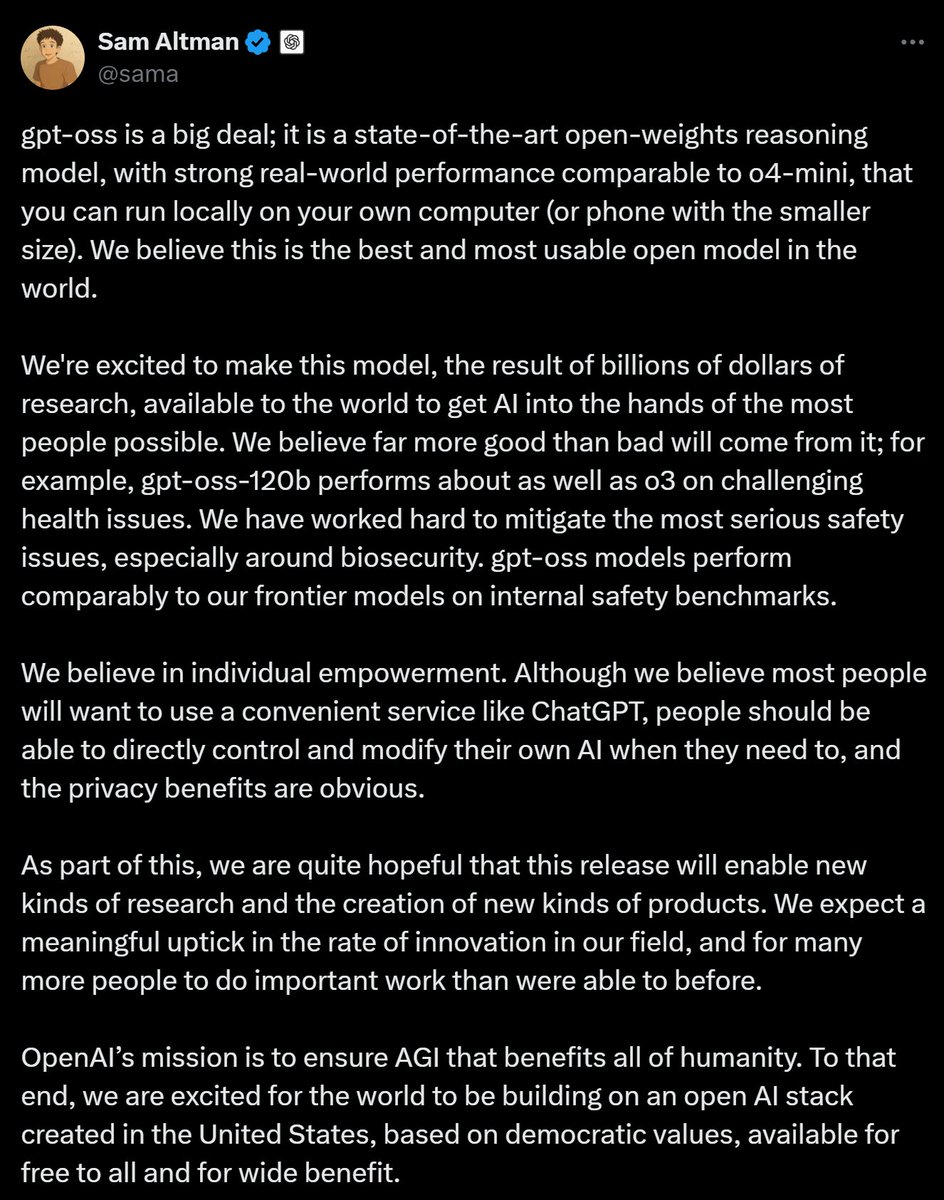
Sé que va a haber un momento en 2023 que da igual lo que esté haciendo o donde esté, recibiré una notificación y se me helará la sangre. Será un momento de pararlo todo y empezar a currar en esto y algo que recordaré por tiempo...
👉 Habrá salido GPT-4
Os cuento cositas [1/n]
👉 Habrá salido GPT-4
Os cuento cositas [1/n]
Desde que aprendimos el patrón GPT-2 -> GPT-3 -> ...
la versión 4 de la familia GPT ha sido el modelo más anticipado de la historia del Deep Learning, y ahora mismo el hype está bastante alto.
Se dicen cosas como estas 👇
la versión 4 de la familia GPT ha sido el modelo más anticipado de la historia del Deep Learning, y ahora mismo el hype está bastante alto.
Se dicen cosas como estas 👇
https://twitter.com/Nick_Davidov/status/1606688723265277952?s=20&t=FHG6Apul44vyirdwa9Lt0g
Si algo ha despertado mi curiosidad por GPT-4 es leer este párrafo del blog de Gary Marcus, quien por normal general (y en este artículo no es la excepción) se sitúa en las antípodas de estos Enormes Modelos del Lenguaje. ¿Hay gente probándolo ya? 👀 

Si algo impresionó de GPT-3 fue cómo OpenAI logró escalar el tamaño de su modelo frente a sus predecesores. Respecto a GPT-2, la nueva versión aumentó su número de parámetros en >100 veces, hasta los 175 mil millones de parámetros. 🤯
¿Cuánto podría escalar GPT-4? ¿Qué pensáis?
¿Cuánto podría escalar GPT-4? ¿Qué pensáis?

Rumores hablan de esto: un modelo 500 VECES más grande que GPT-3.
...pues no lo creo
Si así fuera tendría miedo de tremenda bestia 😅 Pero creo que lo que vamos a ver es algo más "modesto" quizás un modelo 5 VECES mayor que llegue al BILLÓN de parámetros
...pues no lo creo
Si así fuera tendría miedo de tremenda bestia 😅 Pero creo que lo que vamos a ver es algo más "modesto" quizás un modelo 5 VECES mayor que llegue al BILLÓN de parámetros
https://twitter.com/LinusEkenstam/status/1607102506336911360?s=20&t=hdxWSDqigTmDr3dab4Sgtg
Y es que este año DeepMind con Chinchilla demostró que no hacía falta escalar tanto a estos Enormes Modelos del Lenguaje. Que GPT-3 todavía tenía margen de mejora para ser entrenado más y con más datos sin necesidad de hacerlos MÁS GRANDES. Así que el tamaño no es tan importante.

Sea como sea, tiene pinta de que GPT-4 va a consolidarse como la primera GRAN herramienta de IA que masivamente usaremos para un gran rango de tareas. ChatGPT nos ha mostrado sus posibilidades.
Y si los rumores que llegan desde Silicon Valley son ciertos, lo que viene es grande.
Y si los rumores que llegan desde Silicon Valley son ciertos, lo que viene es grande.
A estas tecnologías se le llaman Enormes Modelos del Lenguaje (LLMs) y si queréis saber por qué es tan interesante hacer a estas IAs cada vez más grandes, en este vídeo se explica muy bien :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh