
With the breach of LastPass and everyone wondering if their vaults will be impervious to attacks. I thought it might be good time to refresh our understanding on two type of encryption. Once we do that let's talk about encryption in password managers. 

There are two classes of encryption, but until 1976 symmetric key encryption was the only show in town. It involves a shared key used to encrypt and decrypt messages.
First up we have symmetric key encryption. This requires the successful sharing of a shared key. If someone gets hold of this key its allows them to decrypt any message they intercept and also encrypt its own messages.

Asymmetric encryption uses a mathematically related pair of keys for encryption and decryption: a public key and a private key.
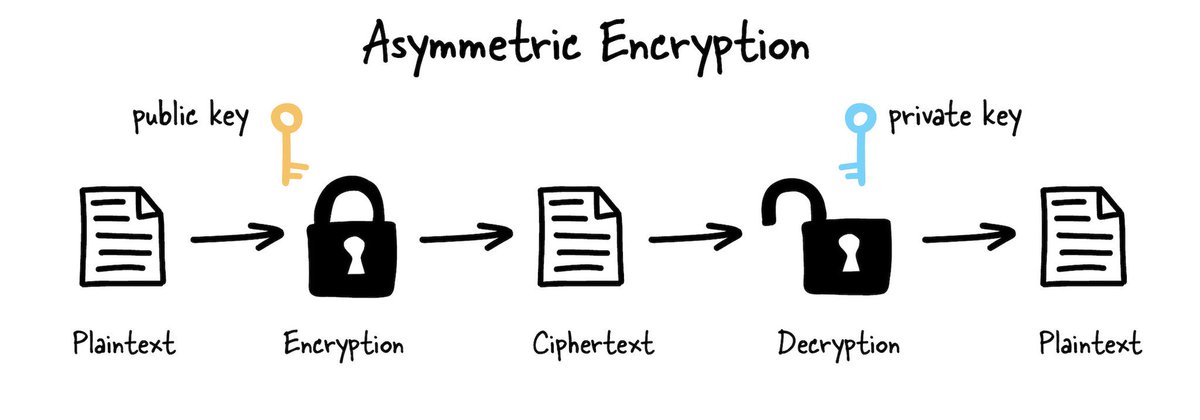
You can encrypt data with either key, but only its pair can decrypt it. The main benefit of this type of encryption is that you can keep your private key entirely private and publicly share the public key, which people can use to encrypt data for you.
Here is the original paper that introduced public key encryption. Called New Directions in Cryptography by Whitfield Diffie and Martin Hellman. ee.stanford.edu/~hellman/publi…
So now back to breach specifics around LastPass.

The main fault here is how they didn't include sensitive metadata like websites URLs in the encrypted payload. Which opens up their customers to social engineering attacks. If you didn't have a strong password, it makes it hard to ensure long term security of your data.
If the number of rounds of PBKDF2 were lower and/or your password wasn't strong cracking these vaults isn't out of the question. There were reports of hashing rounds as low as 5000. With attacker with the right amount of resources this might be possible to crack.
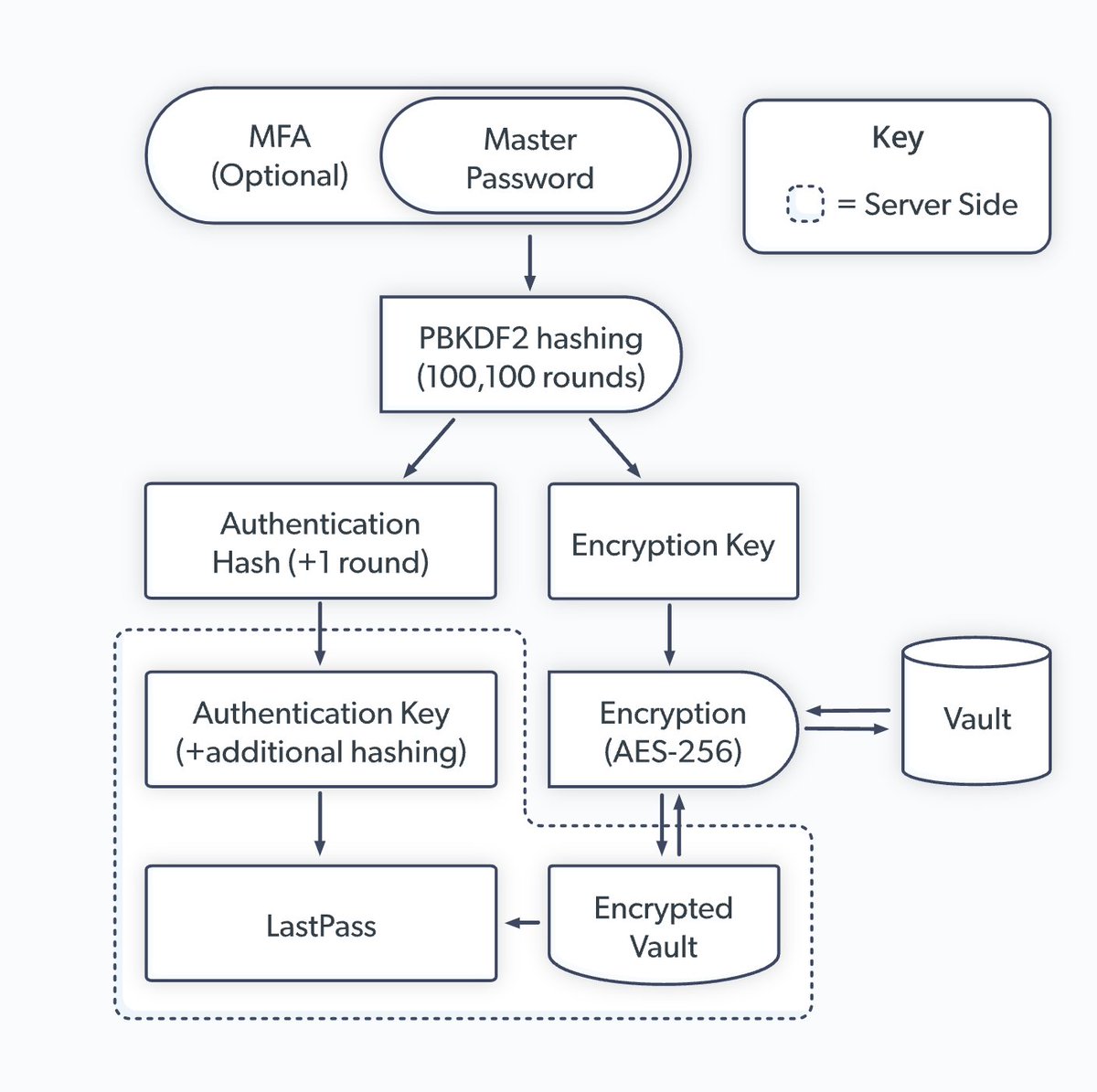
Platforms like @1Password also have a secret key in addition to master password which makes the process much more difficult as well as encrypting all associated metadata that could be an attack vector.
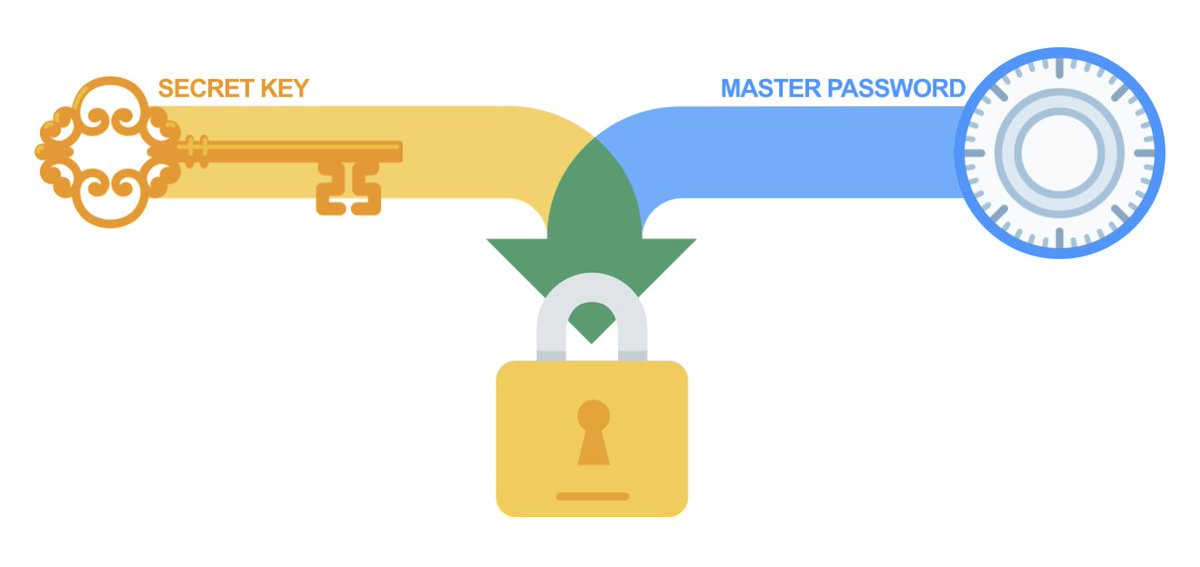
Even if an attacker were to get your encrypted vault data and guess your password they still wouldn't be able to access your encrypted vault data without secret key which you should also guard like a password. Hence the two-secret key derivation.
If want to learn more about encryption we have a more in depth post coming up soon at architecturenotes.co join us and don’t miss out.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



















