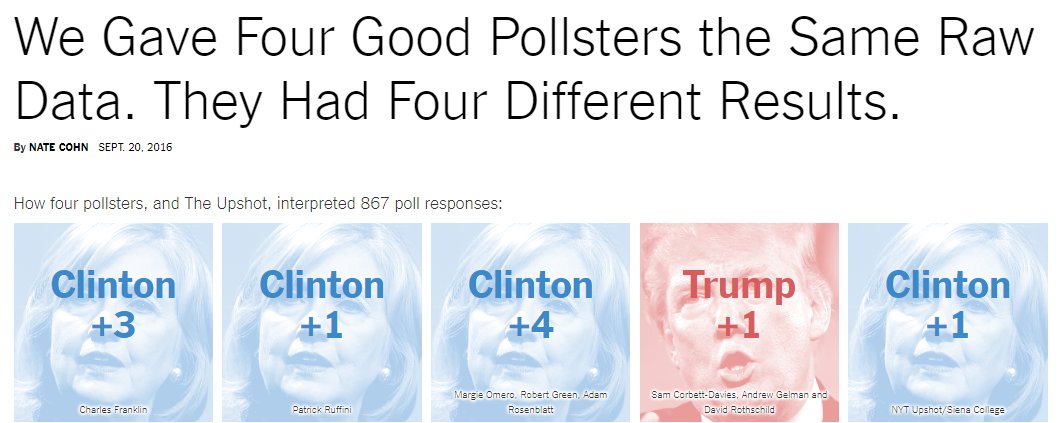
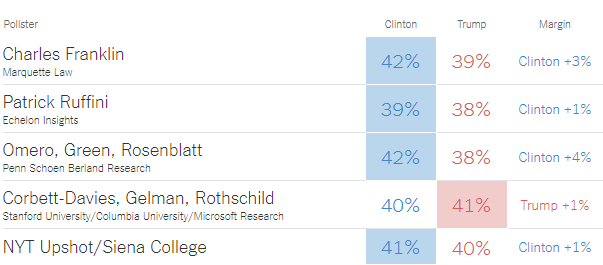
Sobre a Mega Sena: nós, estatísticos, costumamos dizer que não vale a pena apostar, pois o valor esperado é negativo. Ou então falamos que a probabilidade de ganhar na Mega Sena com uma aposta simples de 6 número é de 1 em 50.063.860, ou seja, aprox 0,000002%, *quase* 0%. +
Por outro lado, uma coisa que nós não costumamos dizer é que a probabilidade de ganhar na Mega Sena se vc NÃO apostar é de *exatamente* 0%. A não ser, é claro, que vc encontre de alguma forma um bilhete premiado por aí #CromwellsRule😉
E uma curiosidade pessoal:
Quando entrei na graduação em Estatística, meu pai, um assíduo apostador na loteria, vibrou: "Agora sim a gente ganha na Mega Sena!"
Tive que jogar um balde de água fria nele: "Então pai, não é bem assim..." 😅
Quando entrei na graduação em Estatística, meu pai, um assíduo apostador na loteria, vibrou: "Agora sim a gente ganha na Mega Sena!"
Tive que jogar um balde de água fria nele: "Então pai, não é bem assim..." 😅
• • •
Missing some Tweet in this thread? You can try to
force a refresh