Excited to announce that our work, Progress Measures for Grokking via Mechanistic Interpretability, has been accepted as a spotlight at ICLR 23! (despite being rejected from Arxiv twice!)
This was significantly refined from my prior work, thoughts in 🧵
arxiv.org/abs/2301.05217
This was significantly refined from my prior work, thoughts in 🧵
arxiv.org/abs/2301.05217
https://twitter.com/NeelNanda5/status/1559060507524403200
We trained a transformer to grok modular addition and reverse-engineered it. We found that it had learned a Fourier Transform and trig identity based algorithm, so cleanly that we can read it off the weights!
I did not expect this algorithm! I found it by reverse-engineering.
I did not expect this algorithm! I found it by reverse-engineering.




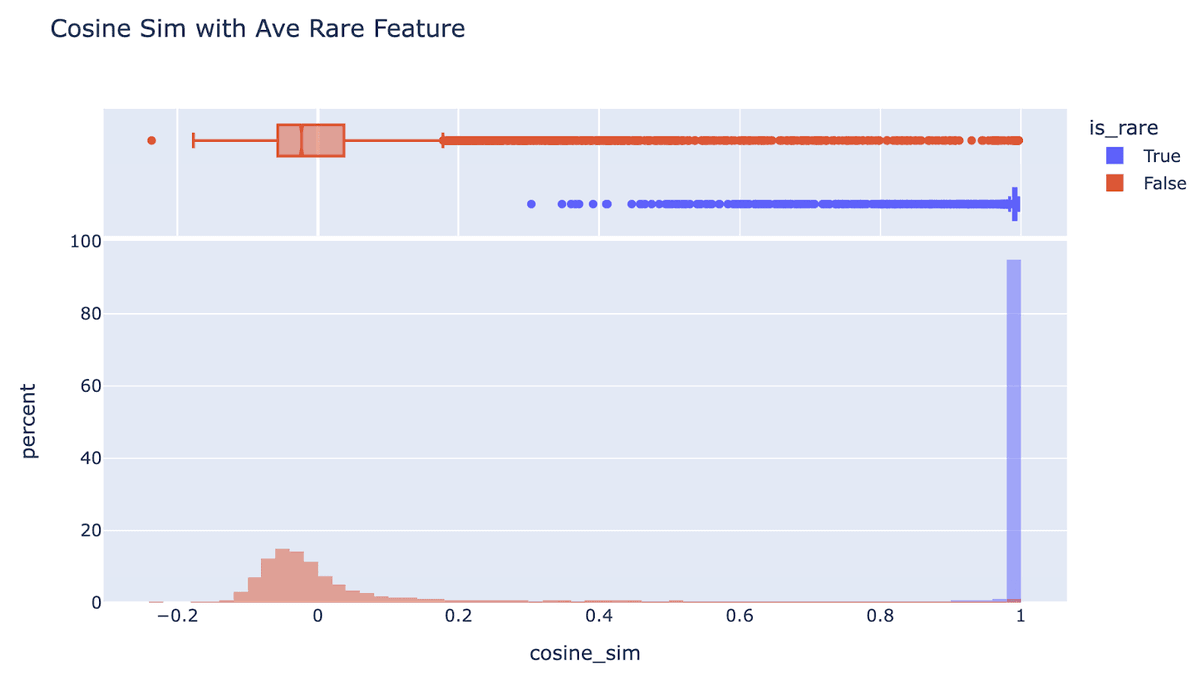
Grokking is hard to study, because there are two valid solutions on train, memorising + generalising. They look the same! But once understood, they can be disentangled:
Restricted loss shows ONLY the generalising performance
Excluded loss shows ONLY the memorising performance
Restricted loss shows ONLY the generalising performance
Excluded loss shows ONLY the memorising performance
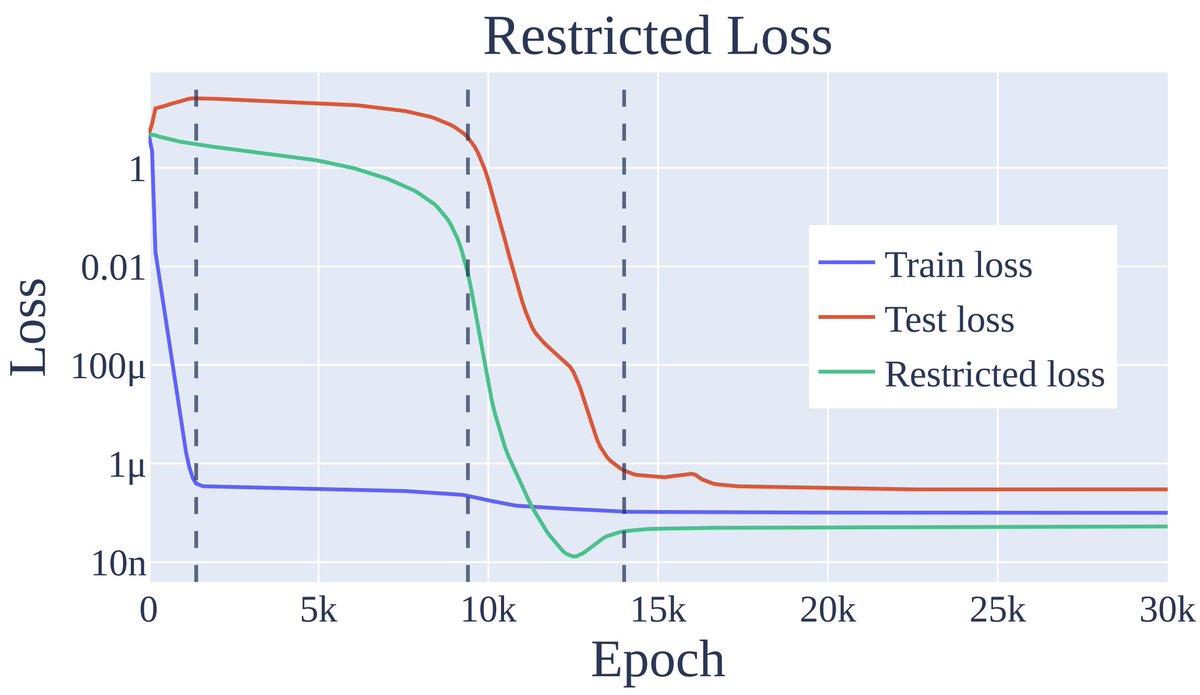
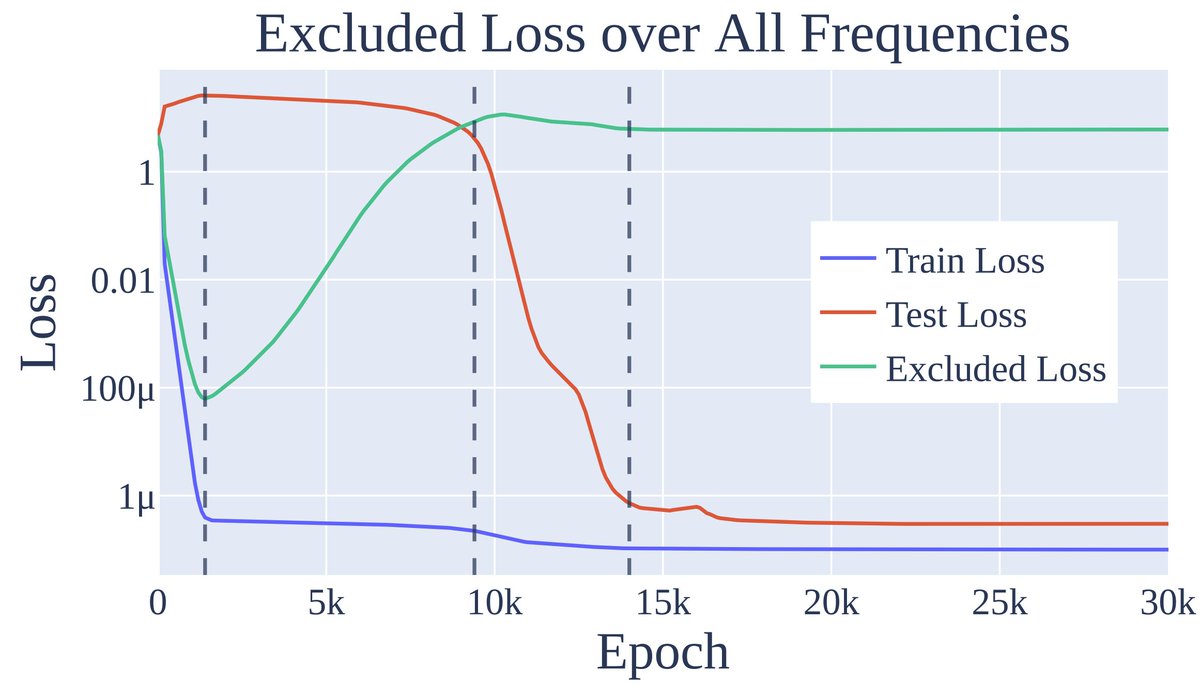
So what's behind grokking?
Three phases of training:
1 Memorization
2 Circuit formation: It smoothly TRANSITIONS from memorising to generalising
3 Cleanup: Removing the memorised solution
Test performance needs a general circuit AND no memorisation so Grokking occurs at cleanup!
Three phases of training:
1 Memorization
2 Circuit formation: It smoothly TRANSITIONS from memorising to generalising
3 Cleanup: Removing the memorised solution
Test performance needs a general circuit AND no memorisation so Grokking occurs at cleanup!
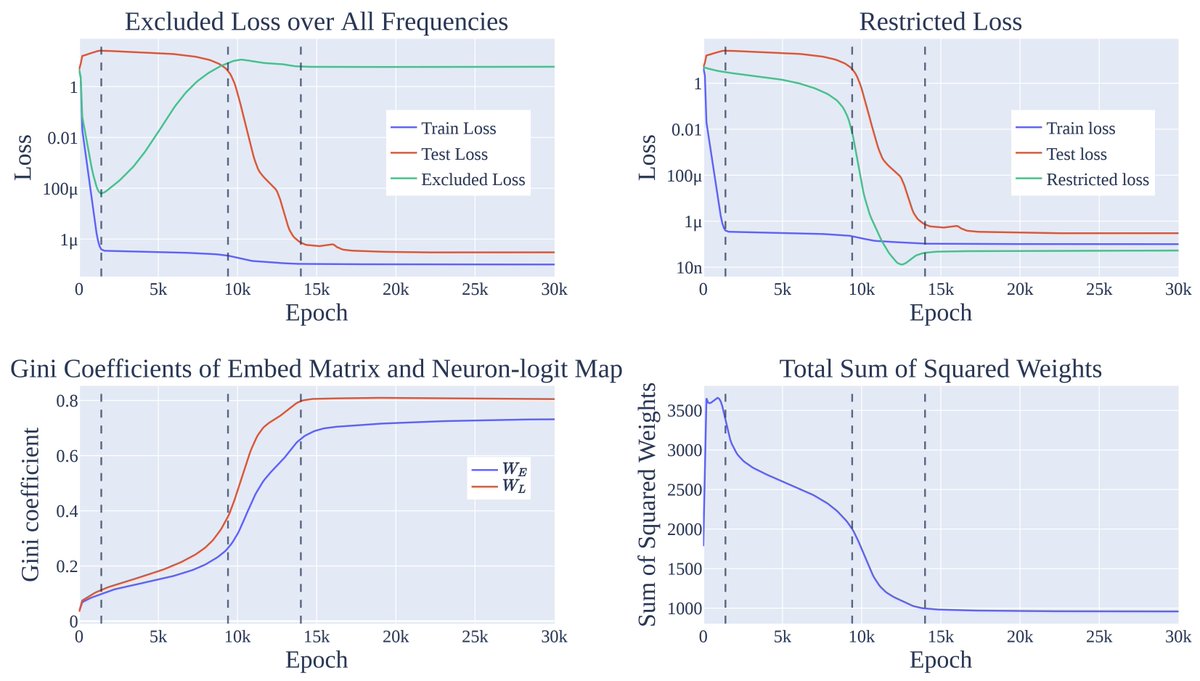
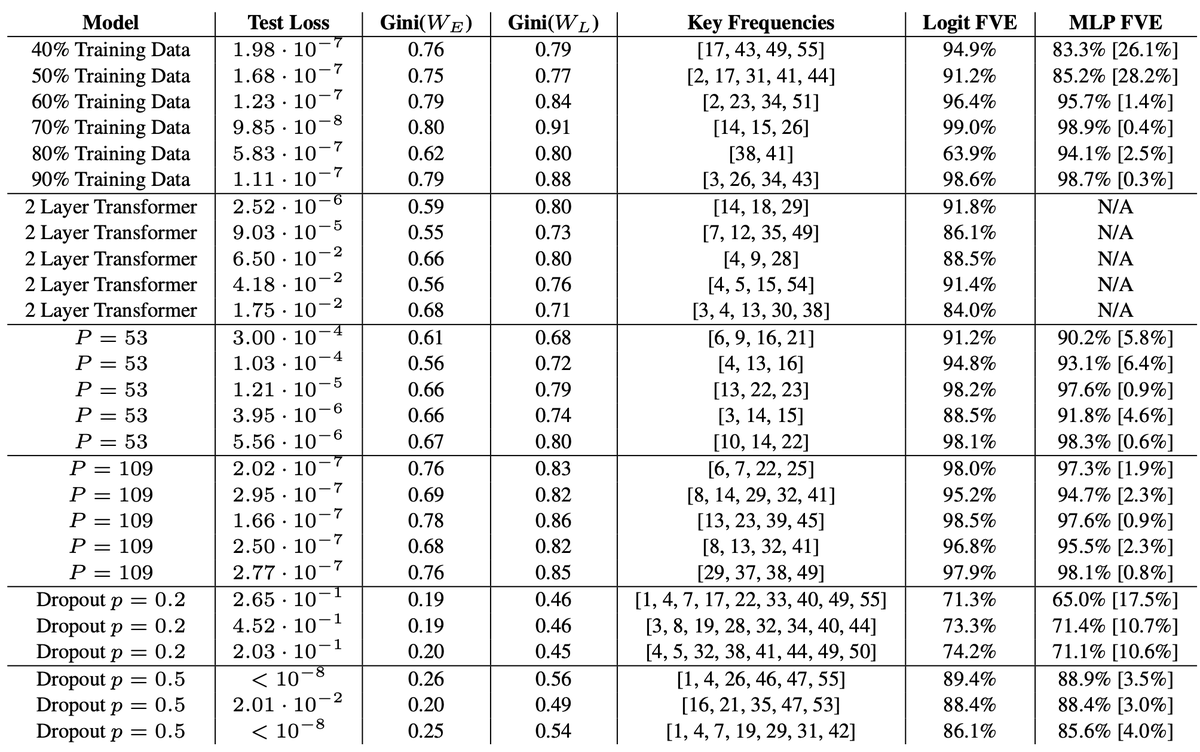
To check that these results are robust and not cherry picked, we train a range of models across architectures, random seeds, and modular base, and see that our algorithm and the predicted phases of training are consistent.
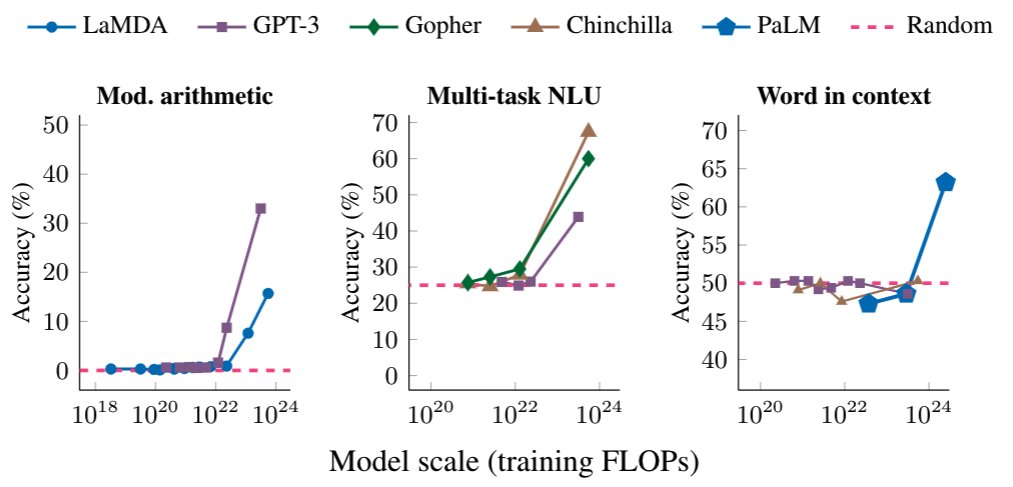
Frontier models often show unexpected emergent behaviour, like arithmetic! Our work demonstrates a new approach: mechanistic explanation derived progress measures. If we know what we're looking for, even in a toy setting, we can design metrics to track the hidden progress.
The broader vision of this work is to apply mech interp to the science of deep learning. Neural networks are full of mysteries, but CAN be understood if we try hard enough. What further questions can be demystified by distilling simple examples? I'd love this for lottery tickets!
@AnthropicAI recently applied a similar mindset to understanding memorisation and double descent. Some great work from Tom Henighan, @shancarter, @trishume, @nelhage and @ch402!
https://twitter.com/AnthropicAI/status/1611045993516249088
To my knowledge, this is one of the first papers from the mech interp community at a top ML conference, and I hope it's the start of many more! There's a lot of work to be done, and I'd love to see more engagement with academia.
I lay out some directions I'm excited about here:
I lay out some directions I'm excited about here:
https://twitter.com/NeelNanda5/status/1608209599844478976
Thanks a lot to my coauthors, @lieberum_t, Jess Smith, @JacobSteinhardt and especially @justanotherlaw, without whom this paper would have never happened.
Check out @justanotherlaw's thread for what's new from the original version
And check out our website for interactive versions of the main figures (I will hopefully make the formatting less jank at some point)
progress-measures-grokking.io
And check out our website for interactive versions of the main figures (I will hopefully make the formatting less jank at some point)
progress-measures-grokking.io
https://twitter.com/justanotherlaw/status/1616591243664031744
• • •
Missing some Tweet in this thread? You can try to
force a refresh