Attention is all you need... but how much of it do you need?
Announcing H3 - a new generative language models that outperforms GPT-Neo-2.7B with only *2* attention layers! Accepted as a *spotlight* at #ICLR2023! 📣 w/ @tri_dao
📜 arxiv.org/abs/2212.14052 1/n
Announcing H3 - a new generative language models that outperforms GPT-Neo-2.7B with only *2* attention layers! Accepted as a *spotlight* at #ICLR2023! 📣 w/ @tri_dao
📜 arxiv.org/abs/2212.14052 1/n
One key point: SSMs are *linear* in sequence length instead of quadratic, and have no fixed context length. Long context for everyone!
We're super excited, so we're releasing our code and model weights today - up to 2.7B parameters!
github.com/HazyResearch/H3 2/n
We're super excited, so we're releasing our code and model weights today - up to 2.7B parameters!
github.com/HazyResearch/H3 2/n
In H3, we replace attention with a new layer based on state space models (SSMs) - with the right modifications, we find that it can outperform Transformers.
Two key ideas:
* Adapting SSMs to be able to do *comparison*
* Making SSMs as hardware-efficient as attention 3/n
Two key ideas:
* Adapting SSMs to be able to do *comparison*
* Making SSMs as hardware-efficient as attention 3/n

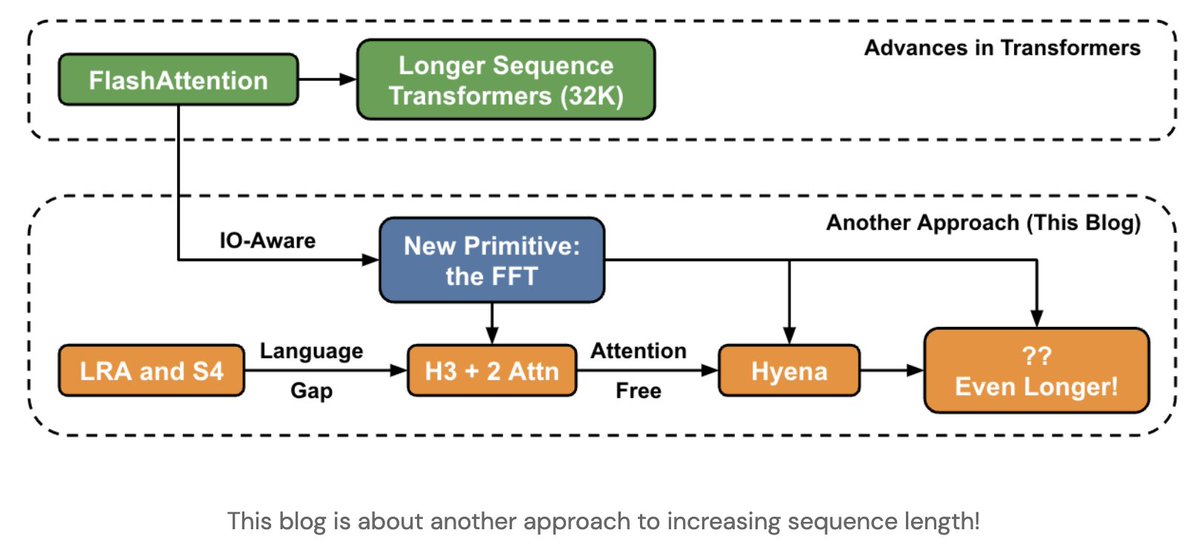
Part 1: the quality gap
SSM's have achieved impressive results on sequence modeling (30+ points over Transformers on Long Range Arena), but have underperformed attention in language modeling.
In our paper, we use *synthetic languages* to probe this gap 4/n
SSM's have achieved impressive results on sequence modeling (30+ points over Transformers on Long Range Arena), but have underperformed attention in language modeling.
In our paper, we use *synthetic languages* to probe this gap 4/n

These synthetic languages (inspired by great work like transformer-circuits.pub/2022/in-contex…) test how well SSMs can do in-context learning compared to attention.
We find a critical missing capability -- SSMs have trouble *comparing tokens* across the sequence. 5/n
We find a critical missing capability -- SSMs have trouble *comparing tokens* across the sequence. 5/n
In response, we designed the H3 layer (Hungry Hungry Hippos) to plug this gap.
The H3 layer stacks two SSMs, and uses some simple multiplicative interactions between them (gating) to do comparisons. 6/n
The H3 layer stacks two SSMs, and uses some simple multiplicative interactions between them (gating) to do comparisons. 6/n

The H3 layer closes the gap on our synthetics, and the gains translate to strong downstream performance on language modeling.
We replaced almost all the attention blocks in a Transformer with H3 layers, and trained on the PILE. Our model *outperforms* GPT-Neo in PPL! 7/n
We replaced almost all the attention blocks in a Transformer with H3 layers, and trained on the PILE. Our model *outperforms* GPT-Neo in PPL! 7/n

These gains also translate to strong downstream zero- and few-shot performance. On SuperGLUE, our zero-shot performance outperforms Transformer models of similar sizes. 8/n

Part 2: the efficiency gap
But that's not all! In order to scale H3 up to billion-parameter models, we had to make it as hardware-efficient as attention.
The convolution is O(N log N) asymptotically, but still underperforms FlashAttention for short sequences... 9/n
But that's not all! In order to scale H3 up to billion-parameter models, we had to make it as hardware-efficient as attention.
The convolution is O(N log N) asymptotically, but still underperforms FlashAttention for short sequences... 9/n

What's the problem? Long convolutions require multiple FFT calls, which introduce expensive GPU memory reads/writes.
We develop FlashConv to address this problem.
FlashConv uses a block FFT algorithm to increase FLOP util, and uses state passing to scale to long sequences. 10/n
We develop FlashConv to address this problem.
FlashConv uses a block FFT algorithm to increase FLOP util, and uses state passing to scale to long sequences. 10/n

With FlashConv, we can make SSMs outperform attention for almost all sequence lengths -- up to 35x faster than FlashAttention for long sequences! 11/n

The upshot: we can scale H3 up to *2.7B* parameter models. And because of the state passing, we can run inference blazing fast -- up to *2.4x* faster than highly-optimized Transformers.
Up to 1,980 tokens/second! 12/n
Up to 1,980 tokens/second! 12/n

We're super excited about these advances, so we're releasing our code and model weights today:
github.com/HazyResearch/H3 13/n
github.com/HazyResearch/H3 13/n
And we've got two blog posts up on our work -- first, read about our synthetic languages and how we developed H3:
hazyresearch.stanford.edu/blog/2023-01-2… 14/n
hazyresearch.stanford.edu/blog/2023-01-2… 14/n
Then check out our blog up on @togethercompute about how FlashConv speeds up SSMs:
together.xyz/blog/h3 15/n
together.xyz/blog/h3 15/n
Overall, really excited about new models/architectures like this. What happens if we don't need attention to get the magic we've been seeing, and we can get the same quality with a linear operator?
No more fixed context windows, long context for everyone! 16/n
No more fixed context windows, long context for everyone! 16/n
With @tri_dao (co-first), @KhaledSaab11, @ai_with_brains, Atri Rudra, and @HazyResearch!
Thanks to @StanfordAILab, @StanfordHAI, @StanfordCRFM, and @togethercompute for helping provide us with the compute necessary to train these models! 17/17
Thanks to @StanfordAILab, @StanfordHAI, @StanfordCRFM, and @togethercompute for helping provide us with the compute necessary to train these models! 17/17
And thanks to @_albertgu for helpful discussions about the H3 architecture - and more importantly, sending us daily hippo videos :)
• • •
Missing some Tweet in this thread? You can try to
force a refresh