
Voici maintenant une tentative d'analyse de ces données 🔽 de températures. Je vais chercher à comprendre un peu les anomalies de température, c'est-à-dire les écarts à la température «attendue» pour le jour donné, et leur distribution statistique, notamment les extrêmes. •1/?
https://twitter.com/gro_tsen/status/1620435663844970497
[Méta: de façon inhabituelle pour moi, je vais rédiger et poster mon fil au fur et à mesure, à un rythme sans doute inégal. C'est pour ça la numérotation de ce tweet dit «2/?», je ne sais pas encore combien il y en aura.] •2/?
La première question qu'on se pose, c'est «quelle est la température “typique” pour un jour donné de l'année?». L'idée évidente c'est de moyenner sur le jeu de données. Le problème c'est que c'est hyper bruité: ⬇️. Ces petites fluctuations ne veulent évidemment RIEN dire. •3/? 

Évidemment qu'il ne fait pas «vraiment» plus froid le 24 avril que le 23 avril, c'est juste un hasard que les choses sont tombées comme ça. En fait, le problème est que le signal est extrêmement bruité: voilà quoi ressemblent l'ensemble des points. ⬇️ •4/?
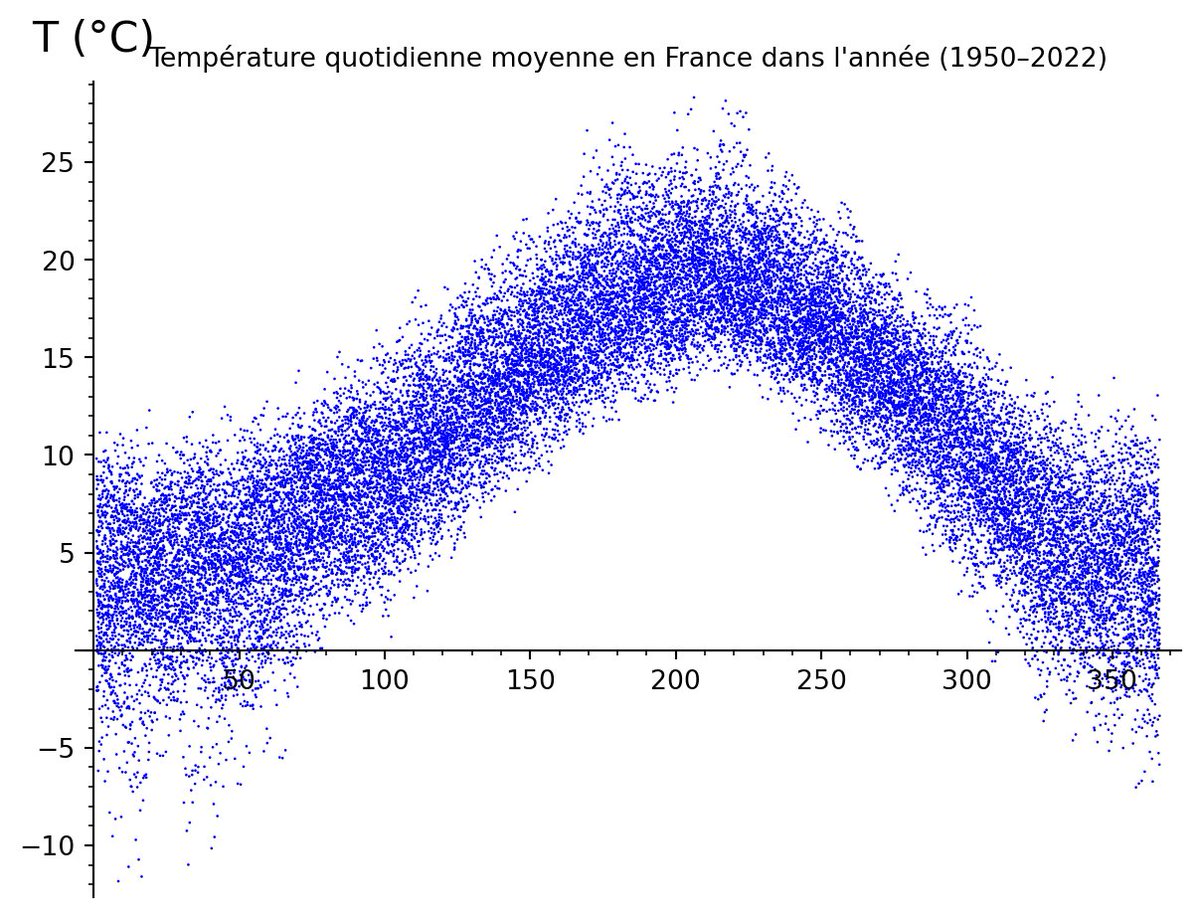
Alors comment on débruite un tel truc? On pourrait penser faire une moyenne par fenêtre glissante (par exemple, 15 jours centrés), mais ça ça revient à faire une convolée avec un signal carré — autant convoler avec une gaussienne, ce sera plus régulier. •5/?
Convoler avec une gaussienne, ça revient à multiplier les coefficients de Fourier par une gaussienne, donc en fait c'est ça que j'ai fait pour le calcul. Reste à choisir la largeur de cette gaussienne. Voici quelques moyennes possibles: ⬇️ •6/?

Dans le graphe du tweet précédent, la courbe en gris est la moyenne non lissée, les trois courbes bleues sont des versions lissées par convolution avec une gaussienne. Celle en pointillés moyenne «trop», celle en tiretés ne moyenne «pas assez». •7/?
Je dis ça au jugé, je ne connais pas de critère précis pour savoir sur quelle largeur faire la convolution. J'ai finalement choisi de multiplier le coefficient de Fourier d'ordre k/an par exp(−(k/6)²). Ça convole par une gaussienne d'écart-type 1an/(6π√2) ~ 13.7j. •8/?
Bref, voici⬇️ le résultat de ce moyennage, donc la température «attendue» en fonction du jour de l'année: contre la moyenne naïve, d'une part, et contre le nuage de points de l'autre (pas à la même échelle: mon moyennage est la — même — courbe bleue dans les deux). •9/?


Ce qui reste quand on soustrait la température d'un jour donnée à la température «attendue» que je viens de décrire, c'est ce qu'on peut appeler des «anomalies» de températures, représenté ici⬇️ par un nuage de point gris (un point par jour). •10/?

Donc, pour être bien clair, dans le graphe du tweet précédent, un point élevé/bas signifie que le jour est anormalement chaud/froid par rapport à ce jour de l'année, et 0 signifie «comme attendu». La droite rouge est la régression linéaire de l'ensemble. •11/?
Cette droite rouge a une pente de 2.53 degrés par siècle, c'est le réchauffement climatique observé sur mon intervalle de données, cohérent avec ce que j'avais trouvé précédemment🔽. Évidemment ma droite passe par 0 au milieu de l'intervalle. •12/?
https://twitter.com/gro_tsen/status/1586002146381959168
Maintenant ce qui m'intéresse c'est de considérer les jours anormaux ✳︎même✳︎ après soustraction de ce réchauffement climatique. Donc je vais appeler «anomalie corrigée» la différence à la droite de régression. Voici à quoi ça ressemble: ⬇️ •13/??

Pour être bien clair, dans ce graphe, un point représente l'écart entre la température du jour (moyennée-lissée) et la température prédite d'après le jour de l'année ET le modèle linéaire de réchauffement climatique. C'est ça que j'appelle «anomalie corrigée». •14/?
La raison pour laquelle je fais cette double correction (jour dans l'année ET changement climatique), c'est parce que je veux connaître les jours exceptionnellement chauds/froids même pour leur saison et même pour le réchauffement moyen observé (en France). •15/?
Évidemment si on ne corrige pas pour le changement climatique il y a plus de jours «anormalement chauds» maintenant qu'il y a 70 ans. Ce qui m'intéresse c'est la fréquence après correction de la tendance linéaire de base. D'où la double correction. •16/?
https://twitter.com/gro_tsen/status/1619651221010411520
Ceci étant dit, quels sont les jours les plus anormalement chauds de mes données? Ce sont:
1989-12-16: +9.5
1952-07-01: +9.2
1961-12-11: +9.1
1958-02-14: +8.8
2022-06-18: +8.7
2003-08-05: +8.7
1961-12-04: +8.6
1953-12-04: +8.5
2019-06-27: +8.4
2019-07-25: +8.4
•17/?
1989-12-16: +9.5
1952-07-01: +9.2
1961-12-11: +9.1
1958-02-14: +8.8
2022-06-18: +8.7
2003-08-05: +8.7
1961-12-04: +8.6
1953-12-04: +8.5
2019-06-27: +8.4
2019-07-25: +8.4
•17/?
Le 16 décembre 1989 a été le jour le plus ✸anormalement✸ chaud en France depuis 1950, selon moi, donc. (Je répète que c'est après correction du réchauffement climatique linéaire, sinon c'est le 18 juin 2022 qui gagne.) •18/?
Et les jours les plus anormalement froids?
1985-01-08: −15.4
1985-01-16: −15.1
1987-01-12: −14.7
1985-01-15: −14.2
1956-02-02: −14.1
1956-02-10: −13.5
1985-01-14: −13.2
1985-01-06: −13.1
1956-02-11: −13.0
1954-02-01: −12.3
(Valeurs d'écarts à la valeur attendue!)
•19/?
1985-01-08: −15.4
1985-01-16: −15.1
1987-01-12: −14.7
1985-01-15: −14.2
1956-02-02: −14.1
1956-02-10: −13.5
1985-01-14: −13.2
1985-01-06: −13.1
1956-02-11: −13.0
1954-02-01: −12.3
(Valeurs d'écarts à la valeur attendue!)
•19/?
Tous ces jours sont en hiver, parce que les hivers 1985 et 1956 ont été vraiment très froids. On peut bien sûr trouver des jours anormalement froids d'autres saisons. Le plus fort que j'ai d'avril à octobre est le 1986-04-12 avec −8.7 d'écart, puis le 2003-10-24 à −8.1. •20/?
(Visiblement les jours anormalement froids ont tendance à se produire plutôt en hiver, mais même les jours anormalement chauds se produisent souvent en hiver: il y a juste plus de variabilité tes températures en hiver qu'en été.) •21/?
Bon, mais ce qui m'intéresse, ce n'est pas de produire des anecdotes météorologiques, c'est d'étudier la distribution de cette anomalie corrigée. Voici sa fonction de répartition ⬇️ (abscisse: anomalie A, ordonnée: proportion des jours à <A d'anomalie corrigée). •22/?

Les deux barres verticales pointillées représentent un écart-type de part et d'autre de la moyenne (par construction, elle vaut 0). La médiane est à 0.03, donc c'est raisonnablement symétrique. •23/?
Bon, je reprends ce fil là où je l'avais laissé. J'ai défini l'«anomalie corrigée de température d'un jour» comme la différence entre la température observée et celle attendue pour le jour dans l'année compte tenu d'un réchauffement climatique linéaire (à 2.52K/siècle). •24/?
Cette anomalie corrigée a (moyenne 0 par construction et) un écart-type de σ = 2.89K. Sur mes données, 68% des jours ont une anomalie corrigée dans l'intervalle ±σ, et environ 96% dans l'intervalle ±2σ. J'ai mis les 4% restants en gras sur ce graphe ⬇️ (=tweet 13). •25/?

Première question qu'on peut se poser: ces 4% de jours où l'anomalie (corrigée) sort de l'intervalle ±2σ, donc qui sont anormalement chauds ou froids au niveau 2σ (en gras sur le graphique du tweet précédent) deviennent-ils de plus en plus fréquents avec le temps? •26/?
À vue de nez on ne dirait pas. Pour être un peu plus précis que ce «vue de nez», j'ai calculé le barycentre dans l'intervalle de temps des jours «anormalement chauds à 2σ» et «anormalement froids à 2σ», et ils valent 0.497 et 0.500 respectivement … •27/?
… (où 0 = le 1er janvier 1950 et 1 = le 31 décembre 2022, points extrêmes de mon jeu de données), bref ces jours anormaux n'ont pas tendance à devenir plus fréquents (ça décalerait le barycentre vers 1), ils me semblent au contraire étonnamment bien répartis. •28/?
⚠️ Je répète que ceci est APRÈS correction par un changement climatique linéaire. Autrement dit, ce que je dis est que les événement extrêmes ne semblent pas devenir plus fréquents / extrêmes que prédit par ce modèle linéaire (ici estimé à 2.53 degré par siècle), … •29/?
… je ne suis PAS en train de dire que les extrêmes de canicule ne deviennent pas plus fréquents, juste qu'ils ne deviennent pas PLUS fréquents que ce qu'on attend par un modèle linéaire de changement climatique. •30/?
D'ailleurs, pour illustrer le point précédent, si je refais le calcul du tweet 27 avec l'anomalie brute (non corrigée), je trouve un barycentre de 0.677 pour les jours chauds à >2σ et 0.415 pour les froids à <−2σ. Donc sans correction, on voit très bien le réchauffement! •31/?
OK, donc si je résume, the story so far:
‣ Je modélise la température par:
(température «attendue» pour le jour de l'année [tweet 9])
+ (changement climatique linéaire [tweet 12])
+ «anomalie corrigée»
Je cherche à comprendre la distribution de cette dernière.
•32/?
‣ Je modélise la température par:
(température «attendue» pour le jour de l'année [tweet 9])
+ (changement climatique linéaire [tweet 12])
+ «anomalie corrigée»
Je cherche à comprendre la distribution de cette dernière.
•32/?
‣ L'anomalie corrigée a un écart-type de σ = 2.89K (degrés). Sa distribution observée est tracée tweet 22. Ses écarts à ±σ et ±2σ suivent largement la forme d'une gaussienne. Ils ne semblent pas devenir plus fréquents avec le temps. •33/??
❧ Je peux calculer d'autres quantités sur mes anomalies corrigées, notamment l'asymétrie en.wikipedia.org/wiki/Skewness et l'excès d'aplatissement en.wikipedia.org/wiki/Kurtosis qui sont en gros le 3e et 4e moments de la variable, correctement normalisés (cf. Wikipédia): … •34/?
… ces quantités mesurent en gros combien la loi de la distribution n'est pas gaussienne au niveau des 3e et 4e moments. Je trouve:
⁃ asymétrie = −0.22, donc décalée vers les anomalies négatives,
⁃ kurtosis normalisé = 0.21, donc plus aplatie qu'une gaussienne.
•35/?
⁃ asymétrie = −0.22, donc décalée vers les anomalies négatives,
⁃ kurtosis normalisé = 0.21, donc plus aplatie qu'une gaussienne.
•35/?
Bon alors honnêtement ces valeurs d'asymétrie et de kurtosis ne me parlent pas trop (peut-être qu'elles parleront à d'autres), mais ce que je peux faire c'est tracer la distribution en échelle log pour comparer à une gaussienne: ⬇️ (en bleu: ℙ(X<a), en rouge ℙ(X>a)). •36/?

Donc, le graphe du tweet précédent montre la proportion des jours ayant une anomalie corrigée <a (en bleu) ou >a (en rouge), avec, en pointillés gris, la distribution gaussienne de même écart-type σ = 2.89K (i.e., essentiellement la fonction d'erreur). •37/?
Ce que je vois là-dessus, c'est que jusque vers 2% de probabilité de part ou d'autre dans l'intervalle ±2σ les anomalies corrigées sont bien modélisées par une gaussienne, mais après il y a des différences significatives, et asymétriques: … •38/?
… les anomalies de FROID sont PLUS probables que ce que le suggère un modèle gaussien avec l'écart-type observé («la queue froide est plus épaisse» 🙊), les anomalies de CHAUD sont au contraire MOINS probables. •39/?
Bon, pour nuancer cette affirmation, quand je dis «plus probables» ça peut aussi dire «plus durables», parce que tout ce que mes calculs voient c'est des nombres de jours d'anomalie, sans tenir compte de leur groupement. •40/?
Par ailleurs, il serait peut-être intéressant de comparer la distribution observée avec une distribution standard ayant non seulement cette moyenne (0) et cet écart-type (σ) mais aussi l'asymétrie et le kurtosis mesurés. Mais je ne sais connais pas ces trucs. •41/?
Bon, je veux clore ce fil (avant que Twitter ne ferme son API publique), donc je mets juste un dernier graphique, montrant l'autocorrélation (r de Pearson) des anomalies corrigées à n jours d'intervalle. La régression de log(r) a une pente de −0.22/j. •42/44

J'avais déjà fait 🔽 un calcul d'autocorrélation des températures, mais cette fois je corrige l'effet saisonnier, donc l'autocorrélation tend bien vers 0 avec pente logarithmique 1/(4.5j): c'est le temps typique de dissipation des anomalies. •43/44
https://twitter.com/gro_tsen/status/1603808798157709313
Bon, je finis ce fil par le code Sage que j'ai utilisé pour ces graphiques et analyses: gist.github.com/Gro-Tsen/92774… (c'est un peu le bordel, mais si on l'évalue ligne à ligne ça doit reproduire les graphes qui précèdent dans ce fil). La source des données est rappelée. •44/44
• • •
Missing some Tweet in this thread? You can try to
force a refresh




