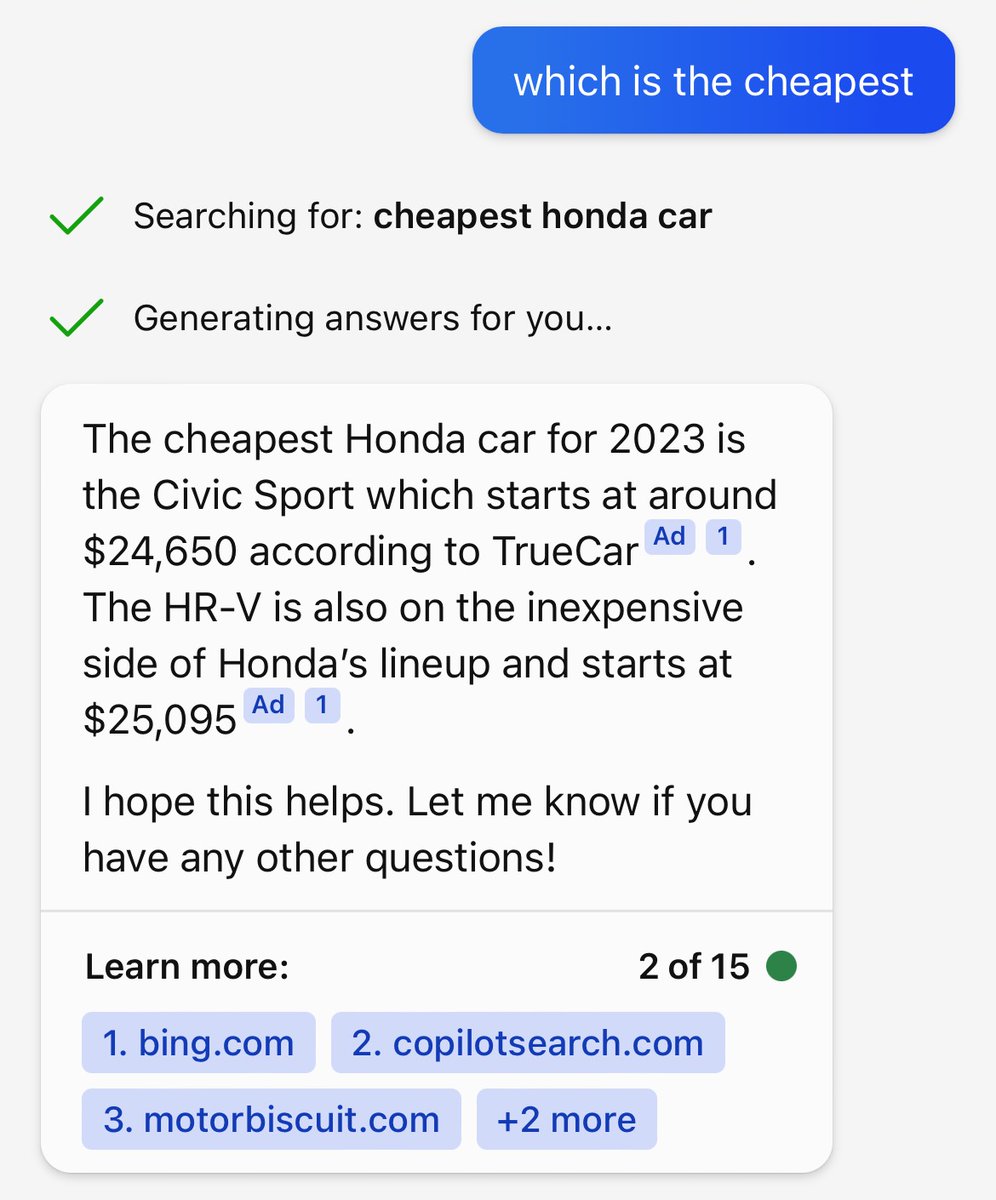
ChatGPT Plugins are UNREAL.
It allows you to interact with your apps (Search, Compile, Calculator, WolframAlpha, Calendar, Zapier) via text, but how does it work?
I'm going to explain 3 techniques — ReAct, Toolformer, LaMDA — and what GPT-4 does.
🧵
1/10
It allows you to interact with your apps (Search, Compile, Calculator, WolframAlpha, Calendar, Zapier) via text, but how does it work?
I'm going to explain 3 techniques — ReAct, Toolformer, LaMDA — and what GPT-4 does.
🧵
1/10
ReAct
Uses some clever few-shot prompt engineering to guide the LLM into dissecting your prompt / question into 3 parts:
—Thought: Introspect on what I need to do.
—Action: Communicate with a tool
—Observation: Reason about the response
And repeating until it's finished.
2/10
Uses some clever few-shot prompt engineering to guide the LLM into dissecting your prompt / question into 3 parts:
—Thought: Introspect on what I need to do.
—Action: Communicate with a tool
—Observation: Reason about the response
And repeating until it's finished.
2/10

ReAct
Facts
—Available today in LangChain!
—Requires more powerful models (100B+)
—Finetuning > prompting, at least for ~50B param models
—API must be text-based (Zapier NLA, Calculator, Search)
3/10
Facts
—Available today in LangChain!
—Requires more powerful models (100B+)
—Finetuning > prompting, at least for ~50B param models
—API must be text-based (Zapier NLA, Calculator, Search)
3/10
Toolformer
Fine-tunes a LLM on a dataset that annotates text with API calls. Dataset is generated from an LLM, discarding samples that, after execution, isn't useful.
The answer to your question is fed in to the fine-tuned LLM and the annotated API calls execute.
4/10
Fine-tunes a LLM on a dataset that annotates text with API calls. Dataset is generated from an LLM, discarding samples that, after execution, isn't useful.
The answer to your question is fed in to the fine-tuned LLM and the annotated API calls execute.
4/10

Toolformer
Facts
—1k-25k examples per API
—Sensitive to wording
—Can work on weaker model (GPT-J 6B)
—API must be text-based
5/10
Facts
—1k-25k examples per API
—Sensitive to wording
—Can work on weaker model (GPT-J 6B)
—API must be text-based
5/10
LaMDA
A separate "research" LLM is fine-tuned to generate an API call from the "base" LLM output, iteratively until the research model thinks the answer is ready.
6/10
A separate "research" LLM is fine-tuned to generate an API call from the "base" LLM output, iteratively until the research model thinks the answer is ready.
6/10

LaMDA
Facts
—Seems quite similar to Toolformer
—Launched in Bard! (that's why its good at math and factual accuracy)
—API must be text-based
—Model size requirements not clear
7/10
Facts
—Seems quite similar to Toolformer
—Launched in Bard! (that's why its good at math and factual accuracy)
—API must be text-based
—Model size requirements not clear
7/10
GPT-4's Plugin approach
—Likely prompt-based
—Can work on APIs that aren't just text->text
—Relies on a) the OpenAPI spec's natural language description of params b) enabling only specific APIs at a time
—BingChat is a reduced version of plugins with only 1 tool: Bing
8/10
—Likely prompt-based
—Can work on APIs that aren't just text->text
—Relies on a) the OpenAPI spec's natural language description of params b) enabling only specific APIs at a time
—BingChat is a reduced version of plugins with only 1 tool: Bing
8/10
Speculating a little:
—Can you train a small model per-plugin once to convert an API spec into a text -> text interface for increased accuracy?
—If multiple plugins can resolve a query, how do you choose?
—For N turned on plugins, how does performance change with higher N?
9/10
—Can you train a small model per-plugin once to convert an API spec into a text -> text interface for increased accuracy?
—If multiple plugins can resolve a query, how do you choose?
—For N turned on plugins, how does performance change with higher N?
9/10
ChatGPT w/ Plugins is becoming everything all the voice assistant products hoped to be. I wonder if in the future it can expand beyond APIs to perform actions on apps purely based on pixels!
"Make up an excuse to cancel all the people I have a meetings with today!"
10/10
"Make up an excuse to cancel all the people I have a meetings with today!"
10/10
Sources:
ReAct [Google]: arxiv.org/pdf/2210.03629…
Toolformer [Facebook]: arxiv.org/pdf/2302.04761…
LaMDA [Google]: arxiv.org/pdf/2201.08239…
ChatGPT Plugins [OpenAI]: github.com/Jeadie/awesome…
ReAct [Google]: arxiv.org/pdf/2210.03629…
Toolformer [Facebook]: arxiv.org/pdf/2302.04761…
LaMDA [Google]: arxiv.org/pdf/2201.08239…
ChatGPT Plugins [OpenAI]: github.com/Jeadie/awesome…
• • •
Missing some Tweet in this thread? You can try to
force a refresh