
#TeamClots preprinted an important milestone in the microclot theory of Long Covid etiology. 🧵on the implications, as I understood them. TLDR: it looks like microclot burden will struggle as a standalone biomarker for LC; we should look deeper!
researchsquare.com/article/rs-273…
researchsquare.com/article/rs-273…
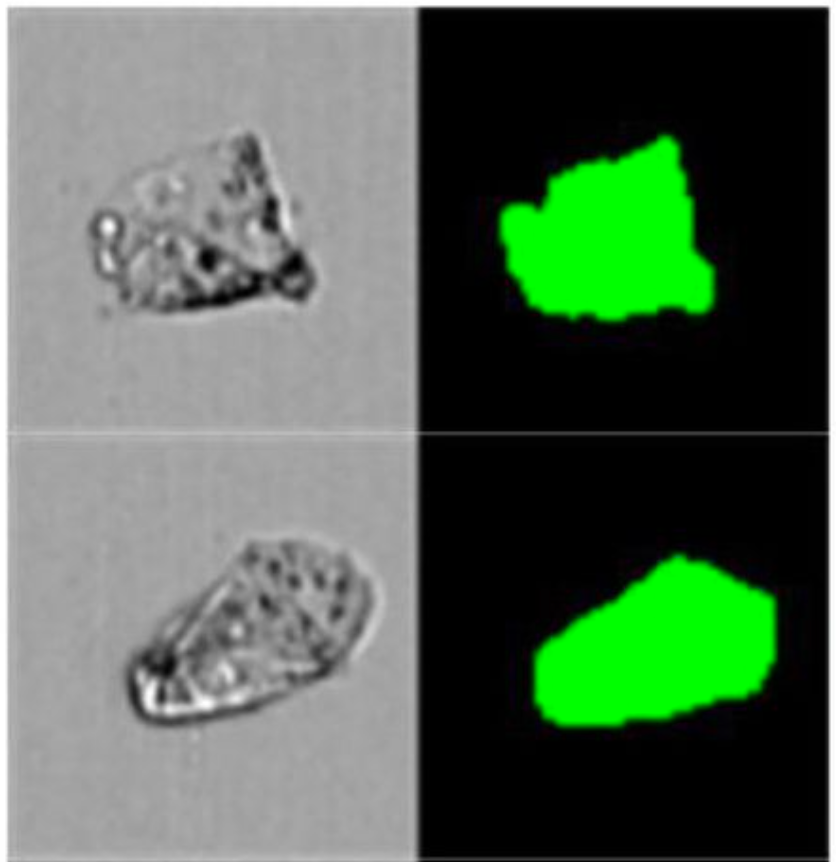
First, why is this an important milestone? This paper uses imaging flow cytometry to quantify the microclot burden in patients, which, AFAIK, is the first time that microclots have been measured in an objective and statistically robust way.

The flow cytometry method captured the following measurements: number of microclot objects per milliliter, mean microclot area, microclot count in area range.
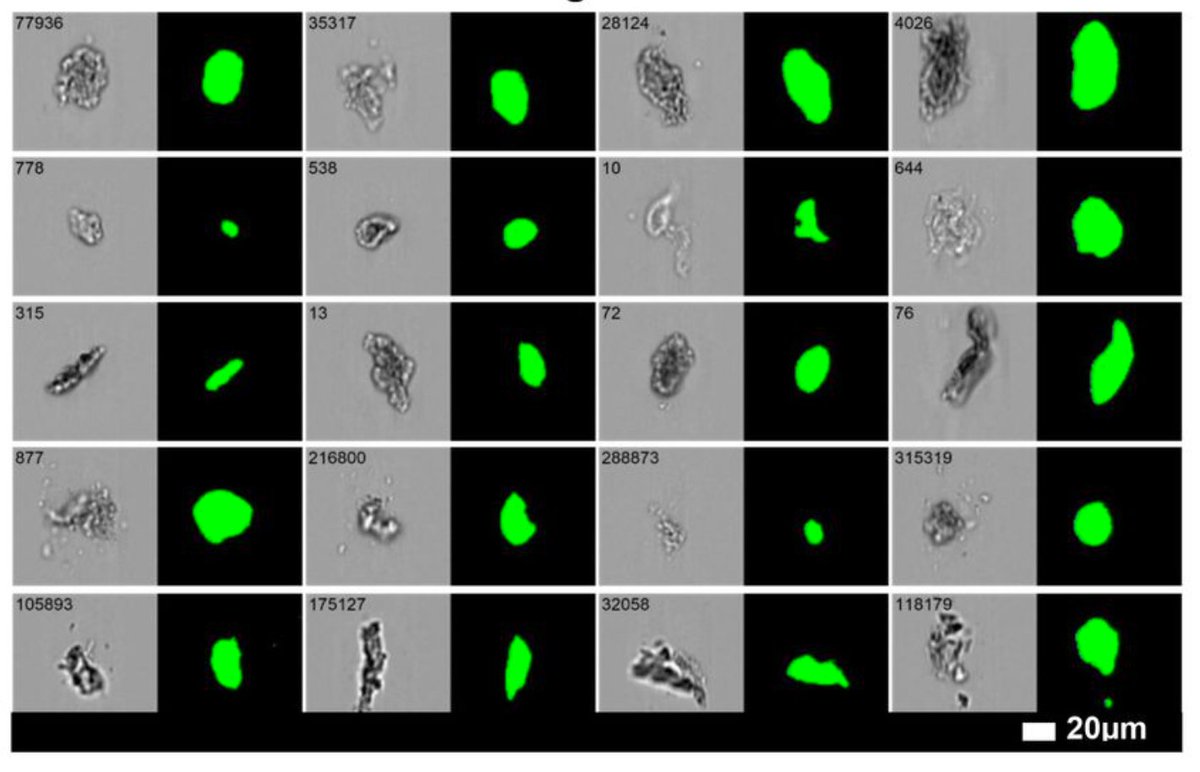
These measurements quantify the microclot burden in terms of microclot number and size. There was a distinction made between microclot objects and microclots that I didn't understand, but what I say applies to the measurements they report in Table 2.

Long Covid patients (#pwLC) had more microclots and microclots of greater size *on average*. But, healthy controls (HCs) had a significant microclot burden as well: 25% of HCs had more microclot objects than 50% of #pwLC; 25% of HCs had larger microclots than 50% of #pwLC.

This suggests that microclot burden (as measured in the paper) will struggle as a standalone biomarker for LC. It seems unlikely that microclot burden correlates with symptomatic burden, and it's not clear why microclot presence is enough to indicate anticoagulation.
The results don't tell us much about whether platelet activation markers can serve as standalone biomarkers. There's also the question of whether microclot composition distinguishes Long Covid, and the largest microclots may be clinically meaningful.
As one of the most rigorous quantifications of microclots, this is an important milestone. My takeaway is that microclot size / number may be part of the story, but, after this, it’s unlikely to be the full story. Thanks #TeamClots, looking forward to the follow-ups!
• • •
Missing some Tweet in this thread? You can try to
force a refresh








