
Surprised by the loss of LLaMA-7B still going down after 1 trillion tokens?
In a new blogpost, I explain why you shouldn't be and argue we haven't reached the limit of the recent trend of training smaller LLMs for longer:
harmdevries.com/post/model-siz…
Analysis in 🧵👇
In a new blogpost, I explain why you shouldn't be and argue we haven't reached the limit of the recent trend of training smaller LLMs for longer:
harmdevries.com/post/model-siz…
Analysis in 🧵👇

The result follows from the Chinchilla scaling laws providing insight into the model size and compute overhead trade-off.
Let's start Chinchilla's 3rd approach: it models the loss L as a function of the number of parameters N and number of training tokens D.
Let's start Chinchilla's 3rd approach: it models the loss L as a function of the number of parameters N and number of training tokens D.

To derive the trade-off, we can ask to scale the optimal parameters by k_N and training tokens by k_D while reaching the same loss as the compute-optimal model.

The exact solution for the scaling factor k_D is in the blogpost. But let's look at the plot of the compute overhead against the model size reduction k_N. Interestingly, this plot is identical across all compute budgets!
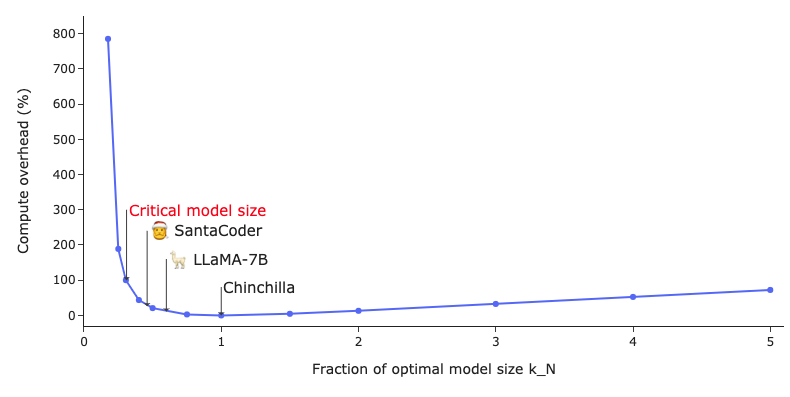
i) 50% of the compute-optimal model leads to 20% compute overhead
ii) 30% results in a 100% overhead
ii) For even smaller models, overhead skyrockets
I estimate that at ±30% we reach the "critical model size", the minimal LLM capacity required to reach the specific loss level.
ii) 30% results in a 100% overhead
ii) For even smaller models, overhead skyrockets
I estimate that at ±30% we reach the "critical model size", the minimal LLM capacity required to reach the specific loss level.
LLaMa-7B is around 57% of the compute-optimal model, leading to a 12% compute overhead.
It's pretty far from the critical model size and could/should have been trained for longer if we want to squeeze the most out of this model size.
It's pretty far from the critical model size and could/should have been trained for longer if we want to squeeze the most out of this model size.
How far can we push the small-model-long-training regime? Let's look at an updated Chinchilla table.
Around the critical model size, we should expect to train a 6B model on 6 trillion tokens, or a 21B model on 28T tokens! We are still far from the limit of this regime!
Around the critical model size, we should expect to train a 6B model on 6 trillion tokens, or a 21B model on 28T tokens! We are still far from the limit of this regime!

This analysis is the result of discussions with many amazing collaborators at the @BigCodeProject. Come join us if you're interested in these research topics!
https://twitter.com/harmdevries77/status/1646524056538316805
• • •
Missing some Tweet in this thread? You can try to
force a refresh



