
Announcing GPT4All-J: The First Apache-2 Licensed Chatbot That Runs Locally on Your Machine💥
github.com/nomic-ai/gpt4a…
Large Language Models must be democratized and decentralized.
github.com/nomic-ai/gpt4a…
Large Language Models must be democratized and decentralized.
We improve on GPT4All by:
- increasing the number of clean training data points
- removing the GPL-licensed LLaMa from the stack
- Releasing easy installers for OSX/Windows/Ubuntu
Details in the technical report: s3.amazonaws.com/static.nomic.a…
- increasing the number of clean training data points
- removing the GPL-licensed LLaMa from the stack
- Releasing easy installers for OSX/Windows/Ubuntu
Details in the technical report: s3.amazonaws.com/static.nomic.a…
GPT4All-J is packaged in an easy-to-use installer. You are a few clicks away from a locally running large language model that can
- answer questions about the world
- write poems and stories
- draft emails and copy
all without the need for internet access.
gpt4all.io
- answer questions about the world
- write poems and stories
- draft emails and copy
all without the need for internet access.
gpt4all.io
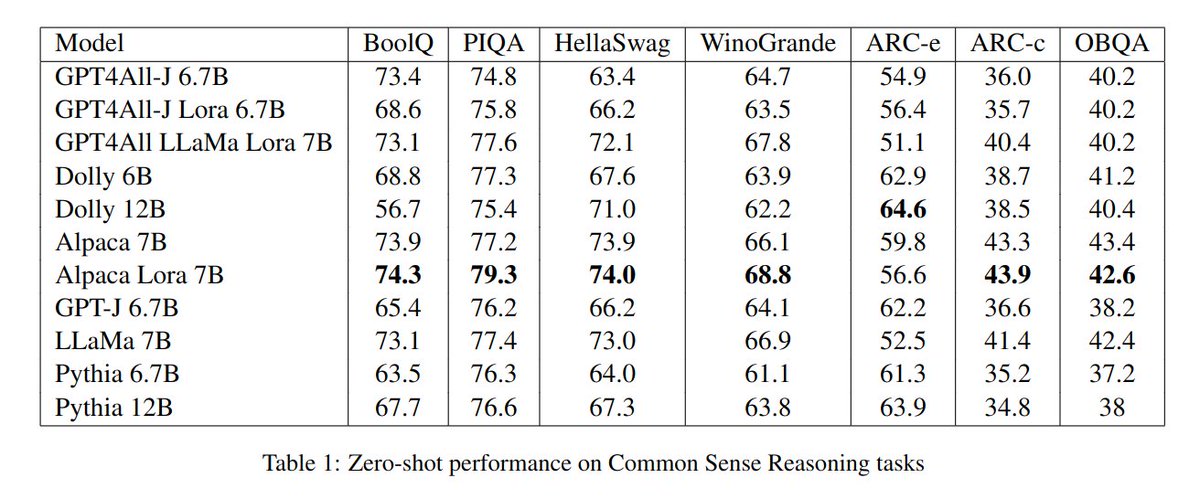
Alongside installers, we release the training data, model weights and perform extensive evaluations of comparable models: 
You can explore the final curated training set in Atlas
atlas.nomic.ai/map/gpt4all-j-…
You'll find large regions dedicated to creative prompts like stories and poems in addition to an increased number of multi-turn responses.
atlas.nomic.ai/map/gpt4all-j-…
You'll find large regions dedicated to creative prompts like stories and poems in addition to an increased number of multi-turn responses.

The LLM itself is an assistant-finetuned version of GPT-J - an LLM released by EleuthrrAI under an Apache-2 License.
GPT-J was more difficult to train than LLaMa but with increased high-quality data and the tireless work of @zach_nussbaum we succeeded.
GPT-J was more difficult to train than LLaMa but with increased high-quality data and the tireless work of @zach_nussbaum we succeeded.
The GPT4All movement grows by the day.
Our community is 10k people strong and filled with elite open-source hackers paving the way to a decentralized future.
We will open-source the data. We will open-source the models. #GPT4All
Join the movement: discord.gg/mGZE39AS3e
Our community is 10k people strong and filled with elite open-source hackers paving the way to a decentralized future.
We will open-source the data. We will open-source the models. #GPT4All
Join the movement: discord.gg/mGZE39AS3e
A few neat things we learned along the way:
GPT-J suffered from significant overfitting during early experimentation. We were able to identify the data responsible for this by filtering for high-loss training examples in Atlas.
atlas.nomic.ai/map/gpt4all-j-…
GPT-J suffered from significant overfitting during early experimentation. We were able to identify the data responsible for this by filtering for high-loss training examples in Atlas.
atlas.nomic.ai/map/gpt4all-j-…

GPT-J really enjoyed memorizing creative examples when we had only a few of them. This directed us to increase the diversity of creative examples leading to a model that could produce more diverse and higher-quality poems, songs, and stories.
GPT-J is certainly a worse model than LLaMa. It was much more difficult to train and prone to overfitting. That difference, however, can be made up with enough diverse and clean data during assistant-style fine-tuning.
The work was worth it. We now have an Apache 2 assistant-style LLM that everyone can build on and it was built with the contributions and input of the entire GPT4All community.
QED.
But the demonstration certainly is not finished.
QED.
But the demonstration certainly is not finished.
We need your help to keep improving. When you download the installer you will have the chance to opt-in to share your data with the GPT4All Open Source data lake.
Opting in you will allow GPT4All models to improve in quality and you to contribute to building LLMs.
Opting in you will allow GPT4All models to improve in quality and you to contribute to building LLMs.
I suppose I forgot to mention that this model runs on your CPU with 4 GBs of RAM at 10 words (tokens) per second.
• • •
Missing some Tweet in this thread? You can try to
force a refresh




