
🧵 Ever wanted to talk with your LLM🤖 on some custom data that it wasn't originally trained on?
@LangChainAI 🦜🔗+ @pinecone 🌲vectorstore will do all the heavy lifting for you. Here's a simplified explanation using a series of 8 illustrations I made.
#GenAI
@LangChainAI 🦜🔗+ @pinecone 🌲vectorstore will do all the heavy lifting for you. Here's a simplified explanation using a series of 8 illustrations I made.
#GenAI
1/8 Assume you've got documentation of an internal library 📚. When you directly ask the LLM about the library, it can't answer as it wasn't trained on it 🤷♂️. No worries! @LangChainAI + @pinecone is here to help 🚀 

2/8: We load the entire package documentation into a vectorstore like @pinecone 🌲. This involves transforming the text into vectors, aka 'embeddings'. Now, these vectors hover around, representing our texts 🗂️

3/8: don't worry about this process, it is actually very easy to do- but we will discuss this in future posts 🙂
4/8: We then want to take our query, turn it into a vector (again, an 'embedding') and place it in the vector space in @pinecone 🌐. Let's say the query is "What is LangChain?" 🤔 This is where the magic starts!

5/8 We can ask @pinecone to perform a semantic search to find vectors that are close to our query vector.
These vectors are semantically related and hold the info we need for our answer. Think of @pinecone as a magical compass (yes, magic!) pointing us to the answer 🧭
These vectors are semantically related and hold the info we need for our answer. Think of @pinecone as a magical compass (yes, magic!) pointing us to the answer 🧭
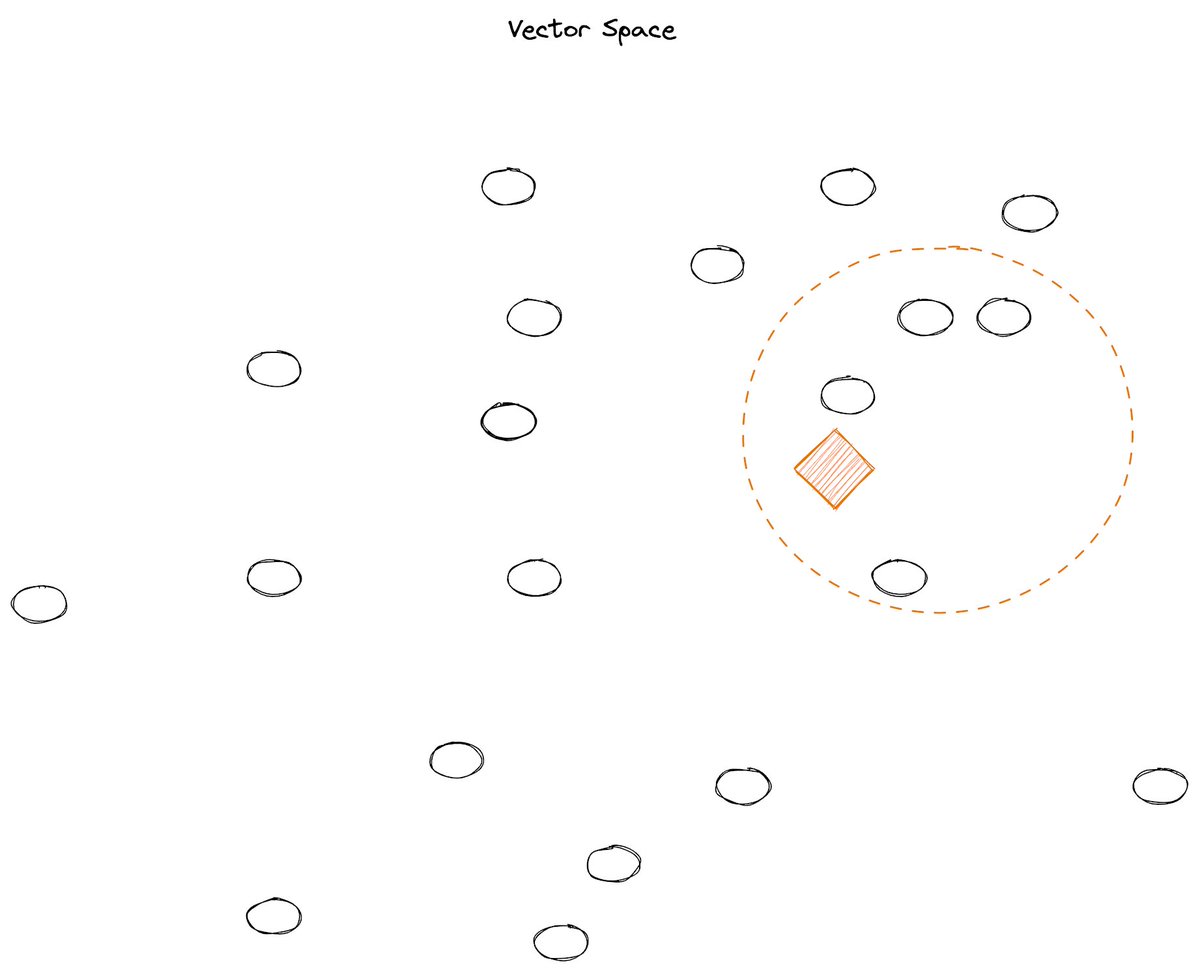
6/8: Now we retrieve these vectors. They contain the context required to answer our query 🕵️♂️ and represent the text that we need to base our answer on.

7/8 Now we need convert these vectors back into readable text 📝 and send it as context to the LLM with our original query. This augmented prompt helps the LLM provide an accurate answer, even though it wasn't originally trained on our specific library 🏋️♀️.

8/8 And here's where @LangChainAI 🦜🔗shines - it automates this entire process and does all the heavy lifting for us 💪
With one line of code, you can invoke a RetrievalQA chain that takes care of all those tasks.
With one line of code, you can invoke a RetrievalQA chain that takes care of all those tasks.
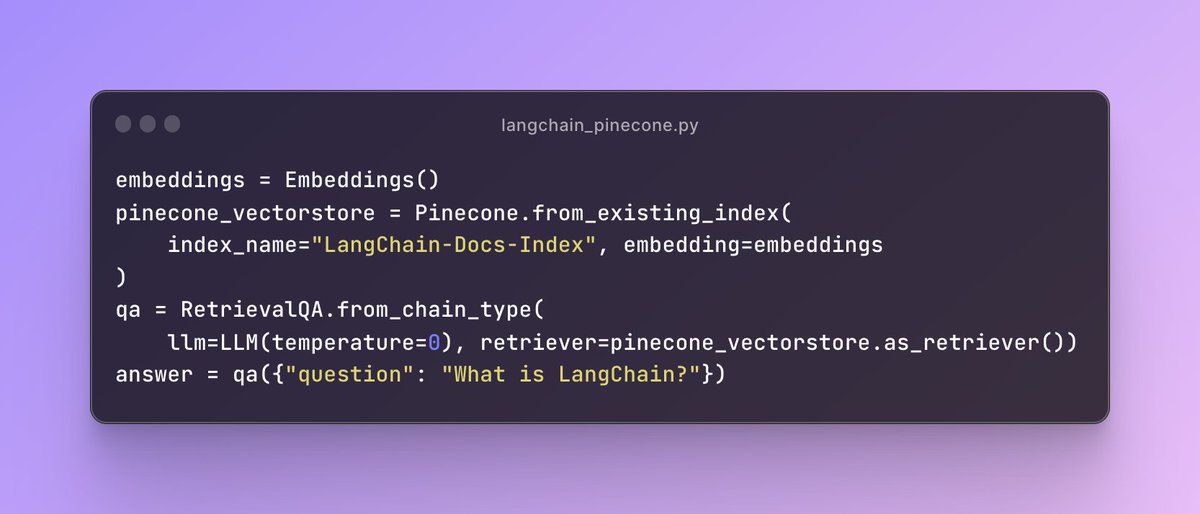
@LangChainAI has tons of more stuff on it, making our lives so much easier when developing LLM powered applications and IMO is the go to open source framework for developing LLM applications.
python.langchain.com/en/latest/
python.langchain.com/en/latest/
Here's some code 👇 and the Github repo link -
github.com/emarco177/docu…
Where you can find a reference for what we have discussed.
Inspired by @hwchase17 👑👑 the creator of @LangChainAI
END - OF -THREAD
github.com/emarco177/docu…
Where you can find a reference for what we have discussed.
Inspired by @hwchase17 👑👑 the creator of @LangChainAI
END - OF -THREAD
• • •
Missing some Tweet in this thread? You can try to
force a refresh














