
I was asked to come talk about "AI art" this Thursday in front of a small selected group of individuals who were curious about the development of the field over the last few months.
Naturally I wanted to blow a few minds – in which I succeeded.
Here's what I showed them 👇
Naturally I wanted to blow a few minds – in which I succeeded.
Here's what I showed them 👇

First course on the menu? Good ol' regular text-to-image which was basically my gateway drug into AI art in July 2022. The first image I've ever created reinvoked that magic I felt as a kid, where magic still was subjectively real.

We've seen an insane acceleration in image quality generated in the last 9 months. So how to better kickoff this thing by questioning reality itself. Can you tell which one of these images is real? Answer below 👇


Answer: None of them. Sorry, I tricked you 🙈
Both images were actually created with Midjourney v5.1 – the latest State of the Art image model there is at the time of writing this: midjourney.com
Food for thought: How can people recognize if an image is real?
Both images were actually created with Midjourney v5.1 – the latest State of the Art image model there is at the time of writing this: midjourney.com
Food for thought: How can people recognize if an image is real?


Just as a comparison. This is how things looked back in July 2022 when I joined and the v2 model was considered State of the Art. The below images have been created with the same prompts for comparison.


Photorealism is only one tiny part of what these model can generate. Here are two more artistic ones. Prompts in ALT.
No style is safe as long as the dataset contain enough text-image pairing for the models to learn about it.
No style is safe as long as the dataset contain enough text-image pairing for the models to learn about it.


But for me personally, as impressive and easy text-to-image has become, it's also the most boring of the latest developments. Image-to-image is a process that enables deeper creativity compared to just text.

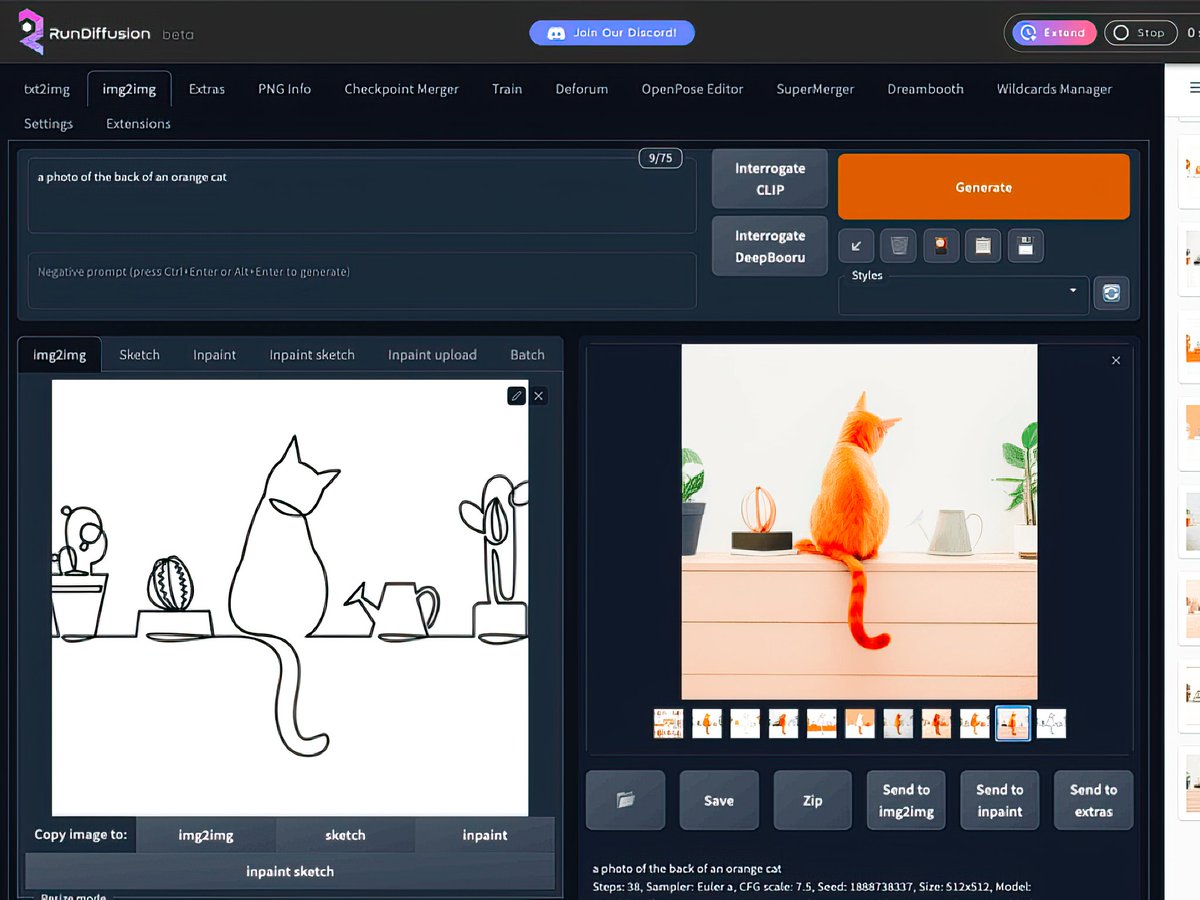
One of the biggest changes for creating images came at the beginning of 2023 with ControlNet. These new models enabled artists to finer control image generation with different guidance methods by providing a sketch for example, which wasn't possible before with pure text.




Other guidance methods include depth maps, canny, segmentation maps and pose. In the example below, Reddit user u/kaiwai_81 generated a few different characters using a pose generated from the MagicPoser iOS app.
Source: reddit.com/r/StableDiffus…
Source: reddit.com/r/StableDiffus…




ControlNet is cool and all, but there is an entire other aspect to image generation, fine-tuning. With the beauty of open-source, it didn't take long for people to train new models to produce new styles. @dymokomi for instance trained his own "aesthetic gradient" embedding.


Image-to-Image also lets us only slightly change an existing image. For instance the old Midjourney --light upscaler made it possible to generate slight variations of an image. By combining these multiple variations with music, we can create the illusion of movement.
Around that time, the deforum google colab started to gain momentum, which made it possible to manipulate images with camera movements and change prompts based on specific frames. Suddenly it was possible to tell more intricate stories.
Naturally, people wanted to try out to manipulate video frames with image-to-image. The below was my first test-run with a video as an input.
And after making sense of how audio can be converted into keyframes, I started to introduce audio reactivity into my deforum creations.
Below is one of my earlier experiments which made use of 238 prompts from the top Midjourney gallery at the time.
Below is one of my earlier experiments which made use of 238 prompts from the top Midjourney gallery at the time.
Now to keep things in perspective, this all wouldn't have been possible with a technical background. I make my daily bread with programming. Current interfaces to create all of the above aren't exactly user friendly interfaces for non-techies.


But things will eventually change. Oh, wait... while writing this thread, they already did. Adobe announced "Generative Fill" which brings text-to-image and image-to-image directly into Photoshop. A game changer in accessibility.
But not only interfaces will change, new workflow and methods will emerge as well. DragGAN from last week brings GAN enabled drag&drop to the table.
Project page: vcai.mpi-inf.mpg.de/projects/DragG…
Unofficial demo: colab.research.google.com/github/Zeqiang…
Project page: vcai.mpi-inf.mpg.de/projects/DragG…
Unofficial demo: colab.research.google.com/github/Zeqiang…
Now, how is this all even possible? Well, language.
More specifically: A paper by Google called "Transformer: A Novel Neural Network Architecture for Language Understanding" which was released back in 2017 makes it all possible.
Transformer: ai.googleblog.com/2017/08/transf…
More specifically: A paper by Google called "Transformer: A Novel Neural Network Architecture for Language Understanding" which was released back in 2017 makes it all possible.
Transformer: ai.googleblog.com/2017/08/transf…

Everything digital when broken down is some form of language. Images have their own language, as well as audio and the same goes for code or brainwaves. Below is an excerpt from "The A.I. Dilemma" from @aza that explains this better than I ever could.
humanetech.com/podcast/the-ai…
humanetech.com/podcast/the-ai…


Let's take a look at a few of the possibilities that opened up because of this. As a programmer, since the release of GPT-4 this Large Language Model has changed my workflow drastically. No more googling or skimming Stackoverflow.

But in the context of art, there are specific libraries that are able to produce visual output with code. p5js is one option which runs in the Browser for example.

Scroll up and take a look again at the Matrix-inspired "Language" image. That image was created with a p5js script generated by GPT-4. You can check out the live version here:
openprocessing.org/sketch/1935387
openprocessing.org/sketch/1935387
aiartweekly.com contributer @0xozram used the same technique for instance to create his submission for the 26th "song lyrics" challenge that ran a few weeks ago.
But p5js is only one example. ChatGPT can also help developing games. Which is what @dpoxley did with art from Midjourney.
Now, text-to-text is obviously possible as well. And with Claude's new 100k token window it's suddenly possible to chat with long dead authors like Marcus Aurelius, ask questions about code repositories, or even to your older self if you kept diaries.
poe.com/Claude-instant…
poe.com/Claude-instant…

Chatting with dead or fictional people is only half the fun through text. What if you could give them an actual voice as well? Modern Text-To-Speech and Voice Cloning makes it possible.

Back in December I started researching TTS models for an idea I had: to create AI generated greeting cards from St. Nicholas himself. After one week, ecardai.com was born. St. Nicholas voice? Cloned from a friend.
A month later I wanted to test creating a podcast. After doing an interview in text with @darylanselmo, he was so kind as to send me a short clip of his voice, which I cloned and used to create a 10min fully voiced interview with him.
open.spotify.com/show/7pKAl7ByI…
open.spotify.com/show/7pKAl7ByI…
A few weeks ago I took this further and started producing short summary videos for the news segment of aiartweekly.com. Requirement: 10 minute production time. GPT-4 and voice cloning my own voice made it possible.
Cloning voices doesn't just work for regularly spoken text though, but also for singing. I can't share the A.I. Drake song here due to potential copyright issues. But searching for "drake - heart on my sleeve" brings up a song voiced by Drake and The Weeknd. Only it's not them.
Music labels didn't think it's funny though. But luckily there are artists like @Grimezsz who made their voice freely available to anyone who wanted to create something and even offered to split 50% of all earned royalties.
https://twitter.com/Grimezsz/status/1650304051718791170
This didn't take long to get picked up, so people started producing songs with her voice.
But voices aren't the only things that can be generated. Google's new MusicLM model also makes it possible to generate instrumentals. aitestkitchen.withgoogle.com/experiments/mu…
If all of the above didn't make you feel tingly, how about if I tell you that it's nowadays also possible to generate videos from pure text only?

Back in March, the community got access to one of the first open-sourced text-to-video models called ModelScope. I couldn't take it from myself to create a little "Twin Peaks" short – all frames, the script and the narration were completely generated.
Only three weeks later, @runwayml announced their Gen-2 model with a massive improvement in image quality & coherency to anything we've seen before and people started creating amazing things like this fictional car ad by Jeremiah Mayhew.
Source:
Source:
So far with images and video, we've only seen what's possible with 2D. But what about adding another dimension and add depth to it? You should've guessed by now that generating 3D content isn't off the table either.

@SuperXStudios for instance added the ability to generate custom 3D character skins for his game “Fields of Battle 2”. The image is generated using ControlNet, which creates character textures and is then pulled through a custom 3D pipeline.
Source: reddit.com/r/StableDiffus…
Source: reddit.com/r/StableDiffus…
SceneDreamer is a model that is able to generate unbounded 3D scenes from in-the-wild 2D image collections. Our personal 3D worlds just got a step closer.
scene-dreamer.github.io/?ref=aiartweek…
scene-dreamer.github.io/?ref=aiartweek…
@BlockadeLabs just last week released a feature which lets you draw and shape your own 360º 3D worlds.
With NeRF's, even converting people or environments into a 3D scene is as easily done as pointing a camera and shoot.
If you're in need for social interactions, OpenAI's Whisper listens to you, ChatGPT generates a reply for you, and a Text-to-Speech model tells it to you. Take a listen to what Brother Geppetto created by @Tamulur wants to tell you.
If all of the above hasn't blown your mind yet. What if I told you that in the future you'll be able to turn your brainwaves into anything?

On the consumer level there is a device called CROWN by @neurosity which lets you read your brainwaves. As we've learned, brainwaves are just another language which can be transformed into anything else (if there is enough data to make sense of it)
neurosity.co/crown
neurosity.co/crown

YouTuber @fireship_dev for instance trained the above device to tell ChatGPT to generate an excuse for him when he's again late for a Zoom meeting by simply thinking of "left hand pinch".
On the research level, MinD-Vis showed that it's possible to reconstruct images that were shown to test subjects while recording their brains with functional magnetic resonance imaging (fMRI) brain scans.
mind-vis.github.io
mind-vis.github.io

And just last week they made their next breakthrough by showing that the same is possible with videos.
Will we soon be able to visualize our dreams?
mind-video.com
Will we soon be able to visualize our dreams?
mind-video.com
This begs only one question: Wen holodeck?
Joking aside, all of the above is the baddest AI (art) will ever be. Soon we might watch our own on-demand generated "Netflix" movies or visit wild west themed parks with synthetic "actors". A lot of sci-fi might soon be just... fiction
Joking aside, all of the above is the baddest AI (art) will ever be. Soon we might watch our own on-demand generated "Netflix" movies or visit wild west themed parks with synthetic "actors". A lot of sci-fi might soon be just... fiction
Putting this thread together took me a lot of work. If you liked it, please consider liking, replying and retweeting it 👇
And if you haven't already, signup on aiartweekly.com to receive the latest #aiart news directly into your inbox 🧡
And if you haven't already, signup on aiartweekly.com to receive the latest #aiart news directly into your inbox 🧡
https://twitter.com/dreamingtulpa/status/1662003609008058368
If you like Tweets like this, you might enjoy my weekly newsletter, #aiartweekly.
A free, once–weekly e-mail round-up of the latest AI art news, interviews with artists and useful tools & resources.
Join 1700+ subscribers here:
aiartweekly.com
A free, once–weekly e-mail round-up of the latest AI art news, interviews with artists and useful tools & resources.
Join 1700+ subscribers here:
aiartweekly.com
• • •
Missing some Tweet in this thread? You can try to
force a refresh





















