
מורה נבוכים לAI!
שמעתם על המאמר החדש שטוען ש"יש אופטימייזר חדש לטרנספורמר שעוקף את אדם במזעור הלוס"?
נמאס לכם מכל מילות הבאזז האלה?
בשרשור הארוך מידי הזה נעשה דיבאזינג לכל הבאז.
מוכנים? 25 מושגים ומונחים, שרשור ע-נ-ק לסופ"ש 🧵>>
#פידטק #פידאטה #פידטכנולוגיה
שמעתם על המאמר החדש שטוען ש"יש אופטימייזר חדש לטרנספורמר שעוקף את אדם במזעור הלוס"?
נמאס לכם מכל מילות הבאזז האלה?
בשרשור הארוך מידי הזה נעשה דיבאזינג לכל הבאז.
מוכנים? 25 מושגים ומונחים, שרשור ע-נ-ק לסופ"ש 🧵>>
#פידטק #פידאטה #פידטכנולוגיה

1. דאטהסט ומודל.
המודל הוא בעצם הAI שפועל על הדאטהסט, שהוא הנתונים מהם הAI לומד.
המודל הוא ה"איך", הדאטהסט הוא ה"ממה" לומדים.
הדאטהסט הוא טבלה עם עמודות ושורות.
בדרך כלל מחלקים דאטהסט ל3 חלקים.
הראשון הוא סט האימון עליו המודל מתאמן. השני הוא >>
המודל הוא בעצם הAI שפועל על הדאטהסט, שהוא הנתונים מהם הAI לומד.
המודל הוא ה"איך", הדאטהסט הוא ה"ממה" לומדים.
הדאטהסט הוא טבלה עם עמודות ושורות.
בדרך כלל מחלקים דאטהסט ל3 חלקים.
הראשון הוא סט האימון עליו המודל מתאמן. השני הוא >>

סט הולידציה, עליו תוך כדי תהליך האימון בודקים את ביצועי המודל, בלי שהוא מתאמן עליו.
השלישי הוא סט הבחינה, שנשמר בצד עד הרגע האחרון, לא נוגעים בו באימון. עושים עליו בדיקה פעם אחת בסוף כדי לייצג כמה המודל באמת למד.
השורות בדאטהסט הן הדגימות השונות, והעמודות מובילות אותנו ל: >>
השלישי הוא סט הבחינה, שנשמר בצד עד הרגע האחרון, לא נוגעים בו באימון. עושים עליו בדיקה פעם אחת בסוף כדי לייצג כמה המודל באמת למד.
השורות בדאטהסט הן הדגימות השונות, והעמודות מובילות אותנו ל: >>

2. פיצ'רים ומימדים.
פיצ'ר הוא מאפיין בודד של רשומה בבסיס נתונים.
פיצ'ר של רשומת "אדם" יכול להיות גיל, שם, כתובת מגורים, משקל, גובה או כל דבר אחר.
דאטהבייס יכיל הרבה רשומות בעלות פיצ'רים.
כשאני מתאר רשומה בעזרת 10 פיצ'רים, אני מתאר בעיה בה 10 מימדים.
בדרך כלל העמודה האחרונה היא >>
פיצ'ר הוא מאפיין בודד של רשומה בבסיס נתונים.
פיצ'ר של רשומת "אדם" יכול להיות גיל, שם, כתובת מגורים, משקל, גובה או כל דבר אחר.
דאטהבייס יכיל הרבה רשומות בעלות פיצ'רים.
כשאני מתאר רשומה בעזרת 10 פיצ'רים, אני מתאר בעיה בה 10 מימדים.
בדרך כלל העמודה האחרונה היא >>

3. התיוג.
התיוג הוא משתנה המטרה אותו אני רוצה לחזות.
הוא יכול להיות רציף (טמפרטורה), קטגוריאלי (דגם) או משהו מופשט (תמונה, וקטור, סיום של משפט).
בעיות בהן המשתנה רציף נקראות בעיות רגרסיה.
בעיות בהן המשתנה קטגוריאלי נקראות בעיות קלסיפיקציה/סיווג.
לשאר אפשר להתייחס כ"משימת הלמידה".
התיוג הוא משתנה המטרה אותו אני רוצה לחזות.
הוא יכול להיות רציף (טמפרטורה), קטגוריאלי (דגם) או משהו מופשט (תמונה, וקטור, סיום של משפט).
בעיות בהן המשתנה רציף נקראות בעיות רגרסיה.
בעיות בהן המשתנה קטגוריאלי נקראות בעיות קלסיפיקציה/סיווג.
לשאר אפשר להתייחס כ"משימת הלמידה".

4. למידה מונחית\Supervised Learning.
למידה מתוך סט נתונים מתוייג.
אם יש לי סט שמכיל המון עסקאות אשראי ותיוג לכל עסקה - "רמאות" או "תקין", אני יכול ללמוד לזהות הונאות בלמידה מונחית (סיווג).
אלגוריתמים פופולאריים - עצי החלטות, יערות אקראיים, רשתות נוירונים (בהמשך).
למידה לא מונחית?
למידה מתוך סט נתונים מתוייג.
אם יש לי סט שמכיל המון עסקאות אשראי ותיוג לכל עסקה - "רמאות" או "תקין", אני יכול ללמוד לזהות הונאות בלמידה מונחית (סיווג).
אלגוריתמים פופולאריים - עצי החלטות, יערות אקראיים, רשתות נוירונים (בהמשך).
למידה לא מונחית?

5. למידה לא מונחית\Unsupervised Learning
למידה מנתונים חסרי תיוגים (כשאין).
מכונה גם אשכול\Clustering.
ניסיון לביצוע הפרדת הנתונים לקבוצות ולמידה מההפרדה הזו.
לדוגמא לקחת בסיס נתונים של קונים באתר קניות ולנסות למצוא תתי קבוצות בעלי מאפיינים דומים.
זו למידה חלשה יותר.
למידה מנתונים חסרי תיוגים (כשאין).
מכונה גם אשכול\Clustering.
ניסיון לביצוע הפרדת הנתונים לקבוצות ולמידה מההפרדה הזו.
לדוגמא לקחת בסיס נתונים של קונים באתר קניות ולנסות למצוא תתי קבוצות בעלי מאפיינים דומים.
זו למידה חלשה יותר.

6. למידת חיזוקים/Reinforcement Learning.
שיטת AI בה קיים סוכן המקבל כקלט את מצב המציאות, מוציא כפלט את הצעד הבא ועליו מקבל פרס או קנס, ומזה לומד.
זאת הדרך בה לרוב מאמנים AI לשחק משחקים או לבצע משימות מורכבות, והדרך שבה אימנו את ChatGPT ממודל השלמת משפטים למודל שעונה בסגנון אנושי.
שיטת AI בה קיים סוכן המקבל כקלט את מצב המציאות, מוציא כפלט את הצעד הבא ועליו מקבל פרס או קנס, ומזה לומד.
זאת הדרך בה לרוב מאמנים AI לשחק משחקים או לבצע משימות מורכבות, והדרך שבה אימנו את ChatGPT ממודל השלמת משפטים למודל שעונה בסגנון אנושי.

7. רשת נוירונים.
אלגוריתם שתכליתו לשערך פונקציה שמקבלת כקלט את הפיצ'רים ומוציאה פלט כלשהו, נניח התיוג, תמונה או משפט.
הרשת בנויה משכבות של "נוירונים".
כל אחד מהם מבצע פעולה מתמטית שנכנסת לנוירונים הבאים בשכבה הבאה.
כשרשת נוירונים היא ממש ענקית, זה כבר >>
אלגוריתם שתכליתו לשערך פונקציה שמקבלת כקלט את הפיצ'רים ומוציאה פלט כלשהו, נניח התיוג, תמונה או משפט.
הרשת בנויה משכבות של "נוירונים".
כל אחד מהם מבצע פעולה מתמטית שנכנסת לנוירונים הבאים בשכבה הבאה.
כשרשת נוירונים היא ממש ענקית, זה כבר >>

8. למידה עמוקה (DL) ופרמטרים.
DL הוא תת תחום של לימוד מכונה שמתעסק ברשתות נוירונים גדולות מאד.
הן הרשתות שיכולות להוציא כפלט טקסט (ChatGPT) או תמונה (Dalle2, מידג'רני).
הפרמטרים הם ה"חלקים הזזים" ברשת העמוקה ואחראיים על היכולת להתמודד עם משימות מורכבות.
נוירון מורכב מכמה פרמטרים.
DL הוא תת תחום של לימוד מכונה שמתעסק ברשתות נוירונים גדולות מאד.
הן הרשתות שיכולות להוציא כפלט טקסט (ChatGPT) או תמונה (Dalle2, מידג'רני).
הפרמטרים הם ה"חלקים הזזים" ברשת העמוקה ואחראיים על היכולת להתמודד עם משימות מורכבות.
נוירון מורכב מכמה פרמטרים.

9. פונקצית לוס/Loss.
פונקציה שצריך להגדיר כחלק מתהליך אימון רשתות נוירונים.
המטרה של תהליך האימון הוא למזער אותה ככל שניתן.
היא מתארת את "כשלון" המודל על המידע אותו הוא לומד.
המזעור שלה - הוא בעצם הלמידה.
פונקציות מוכרות - MSE (סכום הריבועים הפחותים) והCross Entropy Loss.
פונקציה שצריך להגדיר כחלק מתהליך אימון רשתות נוירונים.
המטרה של תהליך האימון הוא למזער אותה ככל שניתן.
היא מתארת את "כשלון" המודל על המידע אותו הוא לומד.
המזעור שלה - הוא בעצם הלמידה.
פונקציות מוכרות - MSE (סכום הריבועים הפחותים) והCross Entropy Loss.
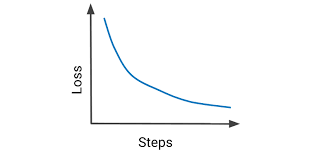
10. הGradient Decent וקצב למידה.
האלגוריתם שבעזרתו ממזערים את הלוס.
הרעיון הוא לבצע נגזרת לפונקציית הLoss, ואם אתם זוכרים מהתיכון, עם נגזרות מוצאים מינימום.
באלגוריתם הזה מבצעים צעדים קטנים אל מזעור אותה פונקציית לוס.
בניגוד לפונקציות בתיכון, אי אפשר פשוט לגזור ולהשוות >>
האלגוריתם שבעזרתו ממזערים את הלוס.
הרעיון הוא לבצע נגזרת לפונקציית הLoss, ואם אתם זוכרים מהתיכון, עם נגזרות מוצאים מינימום.
באלגוריתם הזה מבצעים צעדים קטנים אל מזעור אותה פונקציית לוס.
בניגוד לפונקציות בתיכון, אי אפשר פשוט לגזור ולהשוות >>

לאפס.
השיטה הזו מחשבת לאיזה כיוון צריך להזיז את הפרמטרים ברשת כדי להקטין ככל הניתן את הלוס בהתאם לדאטה, ואז עושה צעד דיסנט קטן לכיוון הזה.
הגרדיאנט הוא נגזרת רב מימדית והמטרה היא לשנות הרבה פרמטרים בבת אחת, בכל פעם קצת כדי למזער את הלוס.
קצב הלמידה הוא ה"כמה קצת זזים" בכל פעם.
השיטה הזו מחשבת לאיזה כיוון צריך להזיז את הפרמטרים ברשת כדי להקטין ככל הניתן את הלוס בהתאם לדאטה, ואז עושה צעד דיסנט קטן לכיוון הזה.
הגרדיאנט הוא נגזרת רב מימדית והמטרה היא לשנות הרבה פרמטרים בבת אחת, בכל פעם קצת כדי למזער את הלוס.
קצב הלמידה הוא ה"כמה קצת זזים" בכל פעם.

11. אפוק/Epoch.
מעבר של רשת הנוירונים על כל סט האימון תוך כדי ביצוע צעדי Gradient Descent.
ברוב המקרים יש צורך ביותר מאפוק אחד כדי למזער את הלוס.
שימו לב שלמרות שבגרף כתוב Test, הסט איתו בודקים דיוק במהלך האימון הוא סט הולידציה.
סט הבחינה נשאר בצד עד הרגע האחרון.
מעבר של רשת הנוירונים על כל סט האימון תוך כדי ביצוע צעדי Gradient Descent.
ברוב המקרים יש צורך ביותר מאפוק אחד כדי למזער את הלוס.
שימו לב שלמרות שבגרף כתוב Test, הסט איתו בודקים דיוק במהלך האימון הוא סט הולידציה.
סט הבחינה נשאר בצד עד הרגע האחרון.

12. הMini Batch
דגימה אקראית של כמות קבועה וקטנה יחסית רשומות מתוך הדאטהסט. הדרך הרווחת לאמן רשת נוירונים היום.
מעבירים מיני באץ' ברשת ועושים צעד דיסנט אחד על כולו.
הוכח כמשפר את יעילות אימון הרשתות יותר מלהעביר אחת אחת, ופרקטי יותר מלהעביר את כל הדאטה ורק אז לחשב גרדיאנט בודד.
דגימה אקראית של כמות קבועה וקטנה יחסית רשומות מתוך הדאטהסט. הדרך הרווחת לאמן רשת נוירונים היום.
מעבירים מיני באץ' ברשת ועושים צעד דיסנט אחד על כולו.
הוכח כמשפר את יעילות אימון הרשתות יותר מלהעביר אחת אחת, ופרקטי יותר מלהעביר את כל הדאטה ורק אז לחשב גרדיאנט בודד.

13. אופטימייזר.
מימוש מחוכם של Gradient Descent.
יש כל מיני דרכים למימוש הפעולה שנקראת Gradient Descent, גם בה יש חלקים זזים.
אופטימייזר יקבע כיצד לבצע אותה.
האופטימייזר הכי פופולארי היום נקרא ADAM.
מימוש מחוכם של Gradient Descent.
יש כל מיני דרכים למימוש הפעולה שנקראת Gradient Descent, גם בה יש חלקים זזים.
אופטימייזר יקבע כיצד לבצע אותה.
האופטימייזר הכי פופולארי היום נקרא ADAM.

14. ארכיטקטורה של רשת נוירונים.
הצורה בה הנוירונים השונים מחוברים זה לזה, הכמות שלהם, מספר השכבות וכדומה.
משפיעה על היכולות השונות של הרשת ללמוד.
החיבור הסטנדרטי נקרא Dense, והוא פשוט מצב שכל הנוירונים בשכבה אחת מחוברים לכל הנוירונים בשכבה הבאה.
הצורה בה הנוירונים השונים מחוברים זה לזה, הכמות שלהם, מספר השכבות וכדומה.
משפיעה על היכולות השונות של הרשת ללמוד.
החיבור הסטנדרטי נקרא Dense, והוא פשוט מצב שכל הנוירונים בשכבה אחת מחוברים לכל הנוירונים בשכבה הבאה.

15. רשת קונבולוציה.
ארכיטקטורת הסטנדרט היום בעיבוד תמונה.
קונבולוציה היא פעולה מתמטית שמבוצעת על כל הפיקסלים בתמונה ומזקקת מהם מאפיינים כמו קצוות, צורות שחוזרות על עצמן וכדומה.
רשתות קונבולוציה מתחילות משכבות קונבולוציה, ואחריהן בדרך כלל שכבות Dense עד הפלט.
ארכיטקטורת הסטנדרט היום בעיבוד תמונה.
קונבולוציה היא פעולה מתמטית שמבוצעת על כל הפיקסלים בתמונה ומזקקת מהם מאפיינים כמו קצוות, צורות שחוזרות על עצמן וכדומה.
רשתות קונבולוציה מתחילות משכבות קונבולוציה, ואחריהן בדרך כלל שכבות Dense עד הפלט.
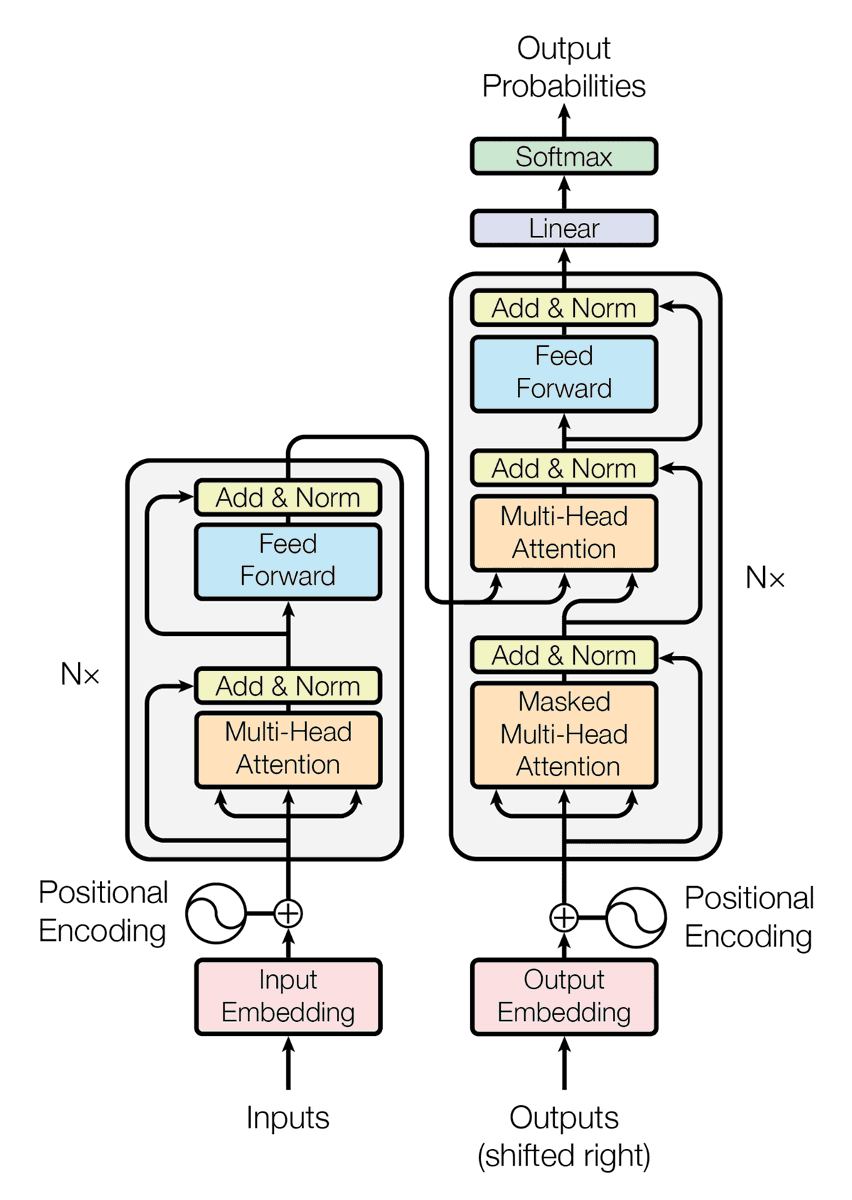
16. טרנספורמר.
רשת עמוקה מיוחדת שטובה במיוחד בעיבוד שפה, אך לא רק.
מכילה "ראשי Attention", שזו בעצם צורה מיוחדת של הרבה שכבות בהן הנוירונים מסודרים כך שהם יוכלו לנתח חשיבויות וקשרים בין מילים בטקסט. הטכנולוגיה שבבסיס ChatGPT וכל מודלי השפה.
מתחילים להשתמש בהם גם לעיבוד תמונה.
רשת עמוקה מיוחדת שטובה במיוחד בעיבוד שפה, אך לא רק.
מכילה "ראשי Attention", שזו בעצם צורה מיוחדת של הרבה שכבות בהן הנוירונים מסודרים כך שהם יוכלו לנתח חשיבויות וקשרים בין מילים בטקסט. הטכנולוגיה שבבסיס ChatGPT וכל מודלי השפה.
מתחילים להשתמש בהם גם לעיבוד תמונה.
17. הRNN/LSTM - שתי ארכיטקטורות ששלטו בעיבוד סדרות לפני הטרנספורמרים.
רשתות שבנויות בצורה בה אפשר להכניס לתוכן רצף ארוך של מידע והן ידעו להתייחס אל רובו.
אם יש לכל מטופל 100 רשומות עם 20 פיצ'רים שמתארים כל שלב בטיפול, לא ארצה רשת שמקבלת קלט ומוציאה פלט, אלא מתמודדת עם כל הסדרה.
רשתות שבנויות בצורה בה אפשר להכניס לתוכן רצף ארוך של מידע והן ידעו להתייחס אל רובו.
אם יש לכל מטופל 100 רשומות עם 20 פיצ'רים שמתארים כל שלב בטיפול, לא ארצה רשת שמקבלת קלט ומוציאה פלט, אלא מתמודדת עם כל הסדרה.

18. שיכון\Embedding.
תהליך בו אנחנו ממירים קלט שאיננו במספרים למספרים בצורה משמעותית.
לדוגמא, מחקר בשם word2vec יצר ייצוג מספרי (וקטור) לכל מילה, בצורה שבה
King-man+woman=king.
שיכון מתבצע על ידי העברה בתוך רשת נוירונים ושימוש במספרים שבשכבות הפנימיות כשיכון עצמו.
תהליך בו אנחנו ממירים קלט שאיננו במספרים למספרים בצורה משמעותית.
לדוגמא, מחקר בשם word2vec יצר ייצוג מספרי (וקטור) לכל מילה, בצורה שבה
King-man+woman=king.
שיכון מתבצע על ידי העברה בתוך רשת נוירונים ושימוש במספרים שבשכבות הפנימיות כשיכון עצמו.

19. עצי החלטות, יערות אקראיים ובוסטינג.
עץ החלטות הוא אלגוריתם שמפצל את הדאטה שוב ושוב, כל פעם לפי הפיצ'ר הכי יעיל כדי לבצע סיווג או רגרסיה.
בסוף מתקבלת צורה של "עץ" שאפשר ללכת לאורכו ובכך לבצע את המשימה בצורה מאד ברורה ומוסברת.
יער אקראי הוא בעצם ערבוב של המון עצים שאומנו >>
עץ החלטות הוא אלגוריתם שמפצל את הדאטה שוב ושוב, כל פעם לפי הפיצ'ר הכי יעיל כדי לבצע סיווג או רגרסיה.
בסוף מתקבלת צורה של "עץ" שאפשר ללכת לאורכו ובכך לבצע את המשימה בצורה מאד ברורה ומוסברת.
יער אקראי הוא בעצם ערבוב של המון עצים שאומנו >>

קצת אחרת, כדי לייצר מודל "מגוון" עם הרבה דעות.
העצים מצביעים והרוב קובע.
גרדיאנט בוסטינג, או רק בוסטינג, היא שיטה בה מערבבים הרבה עצים "חלשים" ליצירת מודל חזק בדרך יותר מתוחכמת מסתם לבצע הצבעה של הרוב קובע. יש מיליון וריאציות איך לבצע את זה.
המוכרות - XGBoost, LightGMB, Catboost.
העצים מצביעים והרוב קובע.
גרדיאנט בוסטינג, או רק בוסטינג, היא שיטה בה מערבבים הרבה עצים "חלשים" ליצירת מודל חזק בדרך יותר מתוחכמת מסתם לבצע הצבעה של הרוב קובע. יש מיליון וריאציות איך לבצע את זה.
המוכרות - XGBoost, LightGMB, Catboost.

21. היפר פרמטרים\Hyper Parameters
שימו לב - שונה מ"פרמטרים"!
המספרים שקובעים את הצורה וצורת הפעולה של מודל לימוד המכונה.
פה נבין מדוגמא, הנה דברים שהם היפר פרמטר: ברשתות, מספר הנוירונים בכל שכבה, מספר השכבות, סוג השכבות, קצב הלימוד. בעצים - הגבלת עומק העץ, הנוסחה שלפיה >>
שימו לב - שונה מ"פרמטרים"!
המספרים שקובעים את הצורה וצורת הפעולה של מודל לימוד המכונה.
פה נבין מדוגמא, הנה דברים שהם היפר פרמטר: ברשתות, מספר הנוירונים בכל שכבה, מספר השכבות, סוג השכבות, קצב הלימוד. בעצים - הגבלת עומק העץ, הנוסחה שלפיה >>

מחליטים איך לפצל את הדאטה.
בעצם ההיפר פרמטרים הם כל ההחלטות שצריך לקבל לפני שמריצים את המודל.
הם הכפתורים על לוח הבקרה שצריך ללכוונן לפני שלוחצים "שגר".
המציאה של ההגדרה הנכונה שלהם היא בד"כ אמפירית בניסויים, לא בגלל שיש תאוריה ענפה מאחורי מה כל דבר צריך להיות.
בעצם ההיפר פרמטרים הם כל ההחלטות שצריך לקבל לפני שמריצים את המודל.
הם הכפתורים על לוח הבקרה שצריך ללכוונן לפני שלוחצים "שגר".
המציאה של ההגדרה הנכונה שלהם היא בד"כ אמפירית בניסויים, לא בגלל שיש תאוריה ענפה מאחורי מה כל דבר צריך להיות.
22. בעיות הOverfitting/Underfitting
מודל פשוט מידי לא יצליח לפתור את הבעיה.
מודל מסובך מידי יחבר את הנקודות בצורה OVER מתאימה ולא יצליח ללמוד להכליל, כלומר להתמודד עם מידע חדש שהוא לא ראה (למרות 0 טעות באימון).
אין דרך חד משמעית לדעת מראש איך לבנות נכון מודל.
ניסוי וטעיה.
מודל פשוט מידי לא יצליח לפתור את הבעיה.
מודל מסובך מידי יחבר את הנקודות בצורה OVER מתאימה ולא יצליח ללמוד להכליל, כלומר להתמודד עם מידע חדש שהוא לא ראה (למרות 0 טעות באימון).
אין דרך חד משמעית לדעת מראש איך לבנות נכון מודל.
ניסוי וטעיה.

23. הPrompt Engineering.
מודלי שפה אמורים להיות נגישים בשפה יום יומית. הגיעו חכמולוגים וגילו שאם הם מדברים איתם (=כותבים Prompt) בצורה מאד ספציפית, מקבלים תוצאות טובות יותר.
זה לא הנדסה. זה שם מפוצץ ללמצוא את הטקסט הכי מתאים.
נכון גם למודלים שמייצרים תמונות (Dalle2, מידג'רני וכו)
מודלי שפה אמורים להיות נגישים בשפה יום יומית. הגיעו חכמולוגים וגילו שאם הם מדברים איתם (=כותבים Prompt) בצורה מאד ספציפית, מקבלים תוצאות טובות יותר.
זה לא הנדסה. זה שם מפוצץ ללמצוא את הטקסט הכי מתאים.
נכון גם למודלים שמייצרים תמונות (Dalle2, מידג'רני וכו)
24. מודלי דיפוזיה\Diffusion Models.
אלה המודלים שמייצרים תמונות.
עובדים במשימה של "הרעשה" וניסון להחזיר את התמונה לקדמותה.
בשילוב עם טרנספורמרים, הם לומדים רעש שמייצג סוגים שונים של תמונות ויכולים לערבב אותן לפי דרישה.
הבסיס לכל טכנולוגיית התמונות שאנחנו מופגזים בה באופן מוגזם.
אלה המודלים שמייצרים תמונות.
עובדים במשימה של "הרעשה" וניסון להחזיר את התמונה לקדמותה.
בשילוב עם טרנספורמרים, הם לומדים רעש שמייצג סוגים שונים של תמונות ויכולים לערבב אותן לפי דרישה.
הבסיס לכל טכנולוגיית התמונות שאנחנו מופגזים בה באופן מוגזם.

25. מדען נתונים.
מדען נתונים הוא מי שצריך להכיר את כל היתרונות, החסרונות, המגבלות והחוזקות של כל הכלים האלה, להסתכל על בעיה בעיניים ולחקור. להבין מה מתאים, איך מתאים, איך ליישם נכון ואיך למנוע מצבים של "הצלחה באימון וכישלון בקרב".
האלגוריתמים האלה רחוקים מלהיות Plug And Play >>
מדען נתונים הוא מי שצריך להכיר את כל היתרונות, החסרונות, המגבלות והחוזקות של כל הכלים האלה, להסתכל על בעיה בעיניים ולחקור. להבין מה מתאים, איך מתאים, איך ליישם נכון ואיך למנוע מצבים של "הצלחה באימון וכישלון בקרב".
האלגוריתמים האלה רחוקים מלהיות Plug And Play >>

וכל זה בלי להתחיל לדבר על לפתח אותם, לשדרג אותם ולחשוב על רעיונות חדשים.
המון מהרעיונות שהצגתי פה הגיחו לעולם ב10-15 שנה האחרונות, זה מדע ממש חדש.
כל רעיון כאן נאבק על מקומו, זה התחיל ב20, עלה ל25 וקיבלתם עיתון.
דברים שלא נכנסו: PCA, VAE, GANs, EDA, Transfer Learning >>
המון מהרעיונות שהצגתי פה הגיחו לעולם ב10-15 שנה האחרונות, זה מדע ממש חדש.
כל רעיון כאן נאבק על מקומו, זה התחיל ב20, עלה ל25 וקיבלתם עיתון.
דברים שלא נכנסו: PCA, VAE, GANs, EDA, Transfer Learning >>
ועוד המון שבטח אתחרט עוד דקה שלא פה.
ו.. זהו!
וואו, איזה שרשור לסופ"ש.
מקווה שנהנתם.
רוצים לא לפספס אף שרשור שלי?
בואו לערוץ הטלגרם השקט, תקבלו התראה כל פעם שעולה שרשור חדש!
linktr.ee/tsoofbaror
ו.. זהו!
וואו, איזה שרשור לסופ"ש.
מקווה שנהנתם.
רוצים לא לפספס אף שרשור שלי?
בואו לערוץ הטלגרם השקט, תקבלו התראה כל פעם שעולה שרשור חדש!
linktr.ee/tsoofbaror
אם זה השרשור הראשון שלי שאתם קוראים, היי!
מזמין אתכם לחקור איתי את הקישקע של הAI,
כל פעם בדרך אחרת.
זה הזמן לעקוב אחרי:
twitter.com/tsoofbaror
מזמין אתכם לרטווט ולהגיב אם אהבתם,
ולהתעלם לגמרי אם השתעממתם. 😍
מזמין אתכם לחקור איתי את הקישקע של הAI,
כל פעם בדרך אחרת.
זה הזמן לעקוב אחרי:
twitter.com/tsoofbaror
מזמין אתכם לרטווט ולהגיב אם אהבתם,
ולהתעלם לגמרי אם השתעממתם. 😍
King-man+woman=Queen!!!
• • •
Missing some Tweet in this thread? You can try to
force a refresh















