
LLMs are everywhere but do you know how they generate text❓
Let's take the magic out of it and break things down to first principles!
Today I'll explain what is conditional probability and how it is related to LLMs!
A Thread 🧵👇
Let's take the magic out of it and break things down to first principles!
Today I'll explain what is conditional probability and how it is related to LLMs!
A Thread 🧵👇
Before diving into LLMs, lets understand conditional probability.
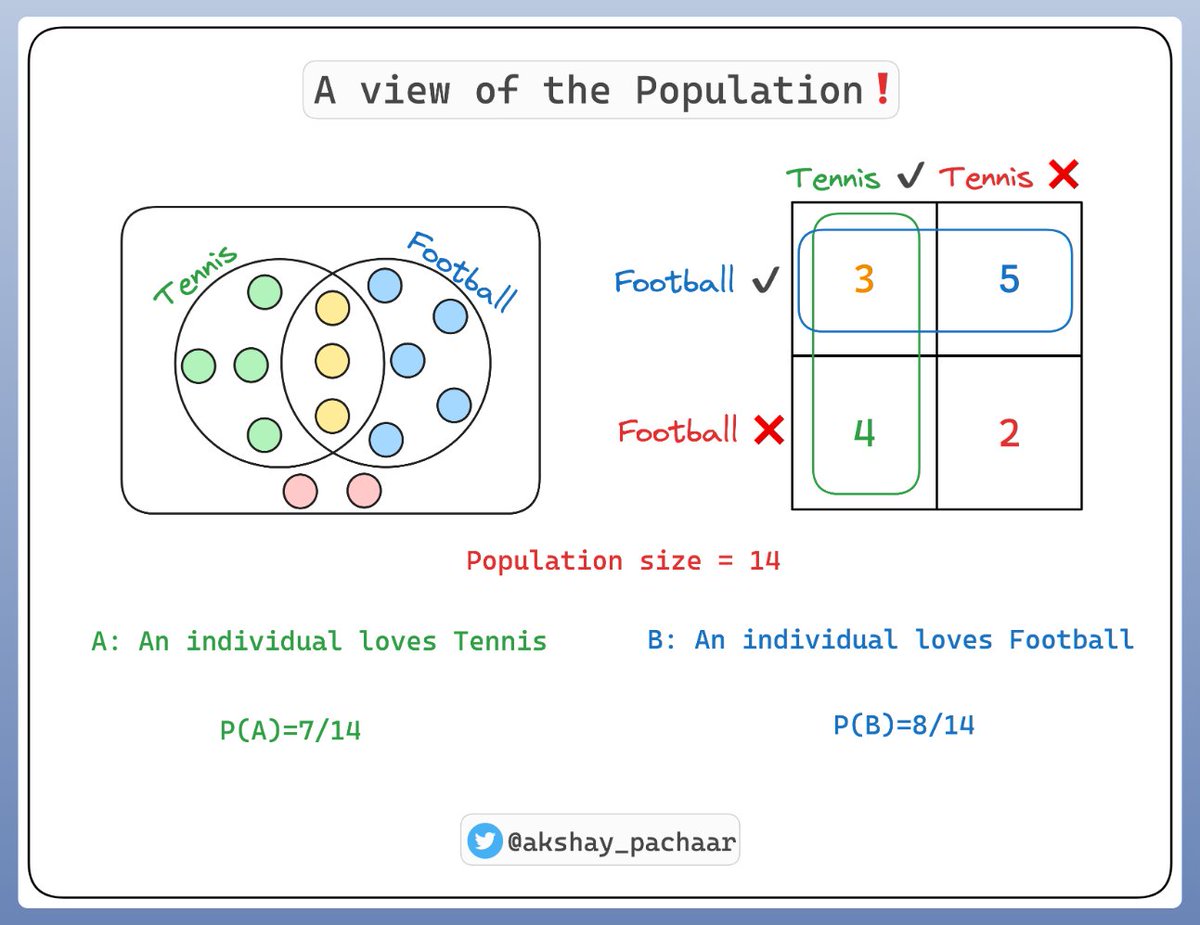
We consider a population of 14 individuals:
- Some of them like Tennis 🎾
- Some like Football ⚽️
- A few like both 🎾 ⚽️
- And few like none
Here's how it looks 👇
We consider a population of 14 individuals:
- Some of them like Tennis 🎾
- Some like Football ⚽️
- A few like both 🎾 ⚽️
- And few like none
Here's how it looks 👇
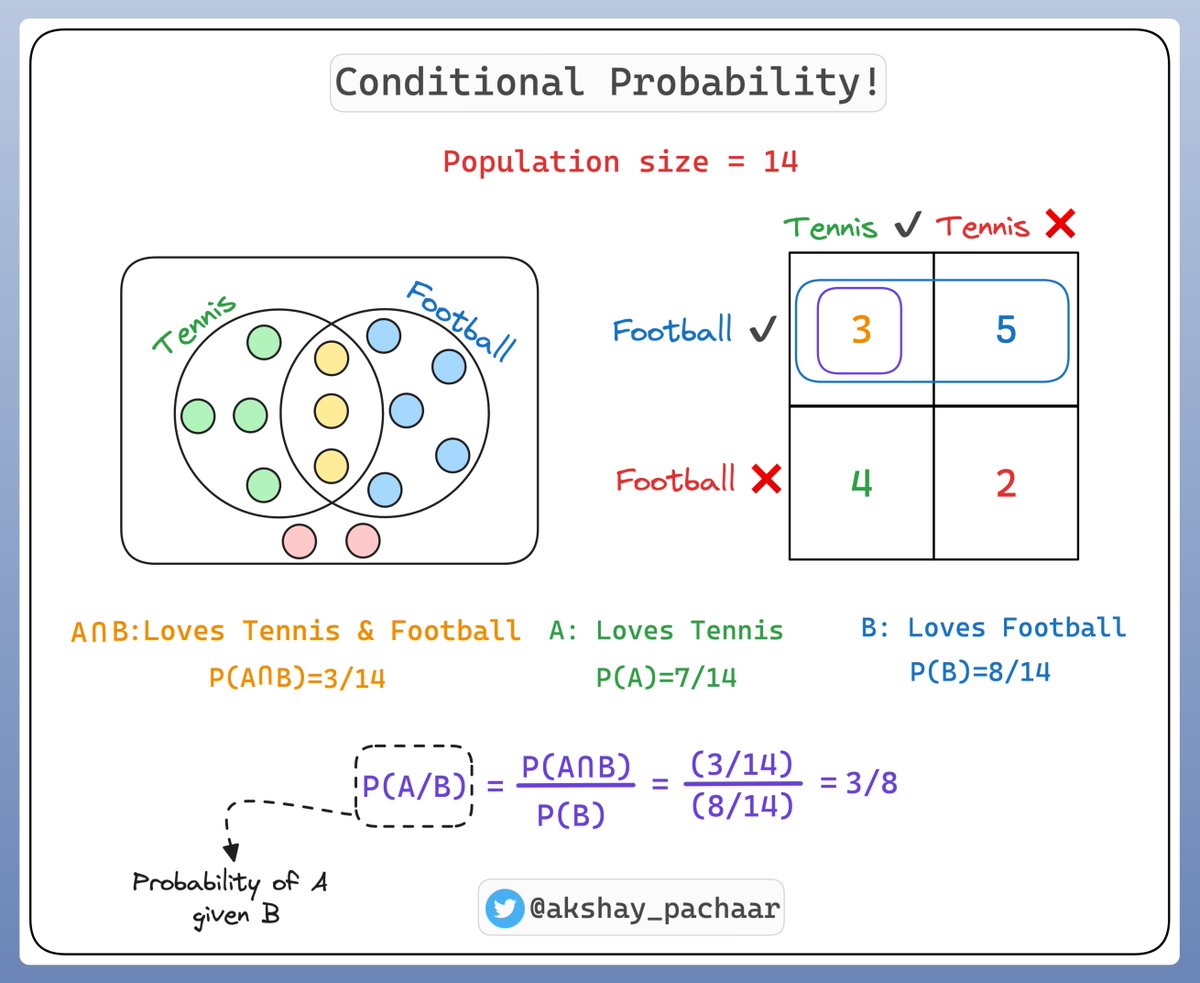
So what is Conditional probability ⁉️
It's a measure of the probability of an event given that another event has occurred.
If the events are A and B, we denote this as P(A|B).
This reads as "probability of A given B"
Check this illustration 👇
It's a measure of the probability of an event given that another event has occurred.
If the events are A and B, we denote this as P(A|B).
This reads as "probability of A given B"
Check this illustration 👇
For instance, if we're predicting whether it will rain today (event A), knowing that it's cloudy (event B) might impact our prediction.
As it's more likely to rain when it's cloudy, we'd say the conditional probability P(A|B) is high.
That's conditional probability for you! 🎉
As it's more likely to rain when it's cloudy, we'd say the conditional probability P(A|B) is high.
That's conditional probability for you! 🎉
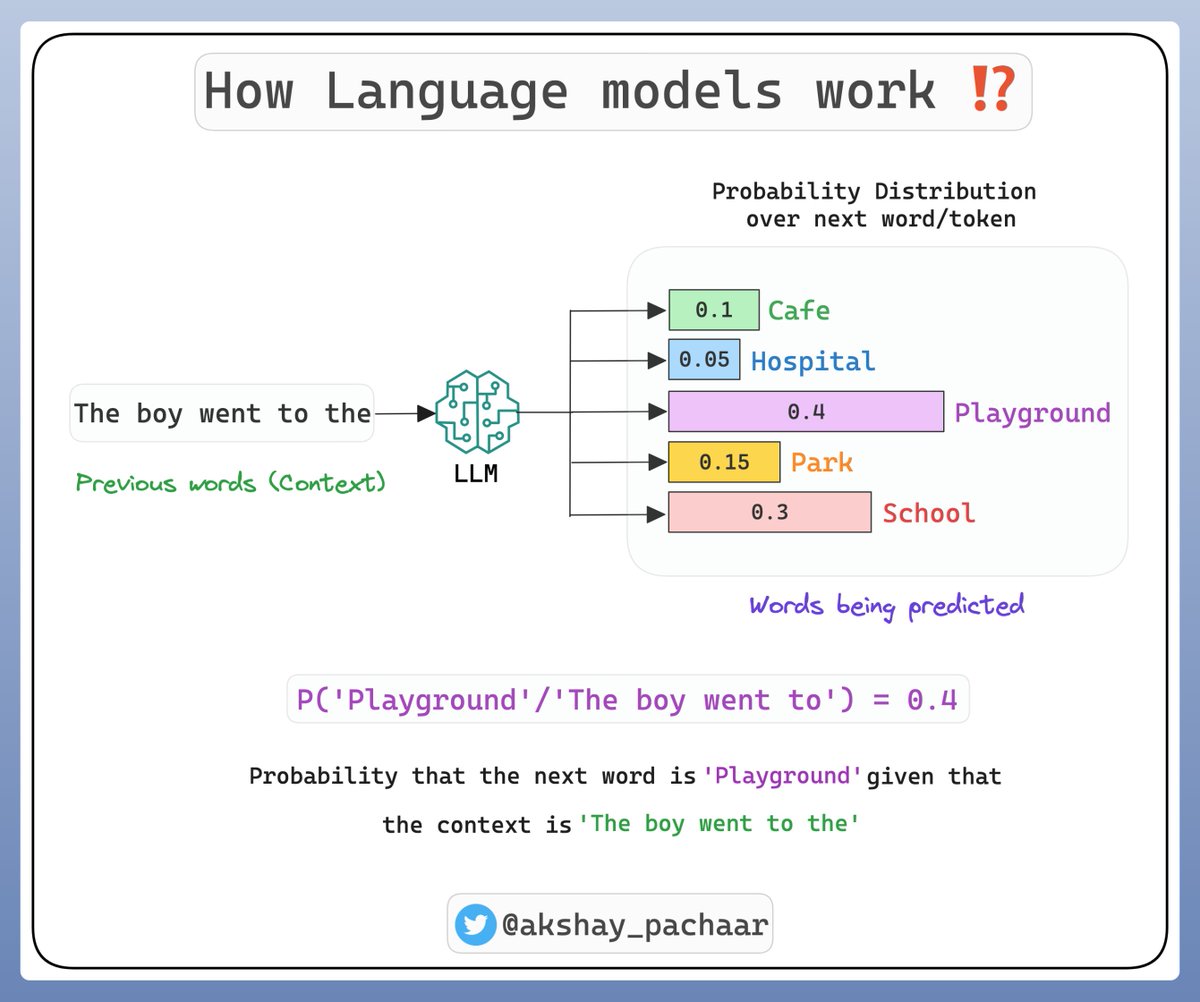
Now, how does this apply to LLMs like GPT-4❓
These models are tasked with predicting the next word in a sequence.
This is a question of conditional probability: given the words that have come before, what is the most likely next word?
These models are tasked with predicting the next word in a sequence.
This is a question of conditional probability: given the words that have come before, what is the most likely next word?

To predict the next word, the model calculates the conditional probability for each possible next word, given the previous words (context).
The word with the highest conditional probability is chosen as the prediction.
The word with the highest conditional probability is chosen as the prediction.

The LLM learns a high-dimensional probability distribution over sequences of words.
And the parameters of this distribution are the trained weights!
The training or rather pre-training** is supervised.
I'll talk about the different training steps next time!**
Check this 👇
And the parameters of this distribution are the trained weights!
The training or rather pre-training** is supervised.
I'll talk about the different training steps next time!**
Check this 👇

Hopefully, this thread has demystified a bit of the magic behind LLMs and the concept of conditional probability.
if you want to learn more about building with LLMs, @LightningAI has some top resources on the same!
Check this out👇
lightning.ai/pages/blog/
if you want to learn more about building with LLMs, @LightningAI has some top resources on the same!
Check this out👇
lightning.ai/pages/blog/

That's a wrap!
If you interested in:
- Python 🐍
- Data Science 📈
- Machine Learning 🤖
- MLOps 🛠
- NLP 🗣
- Computer Vision 🎥
- LLMs 🧠
I'm sharing daily content over here, follow me → @akshay_pachaar if you haven't already!!
Cheers! 🥂
If you interested in:
- Python 🐍
- Data Science 📈
- Machine Learning 🤖
- MLOps 🛠
- NLP 🗣
- Computer Vision 🎥
- LLMs 🧠
I'm sharing daily content over here, follow me → @akshay_pachaar if you haven't already!!
Cheers! 🥂
• • •
Missing some Tweet in this thread? You can try to
force a refresh





