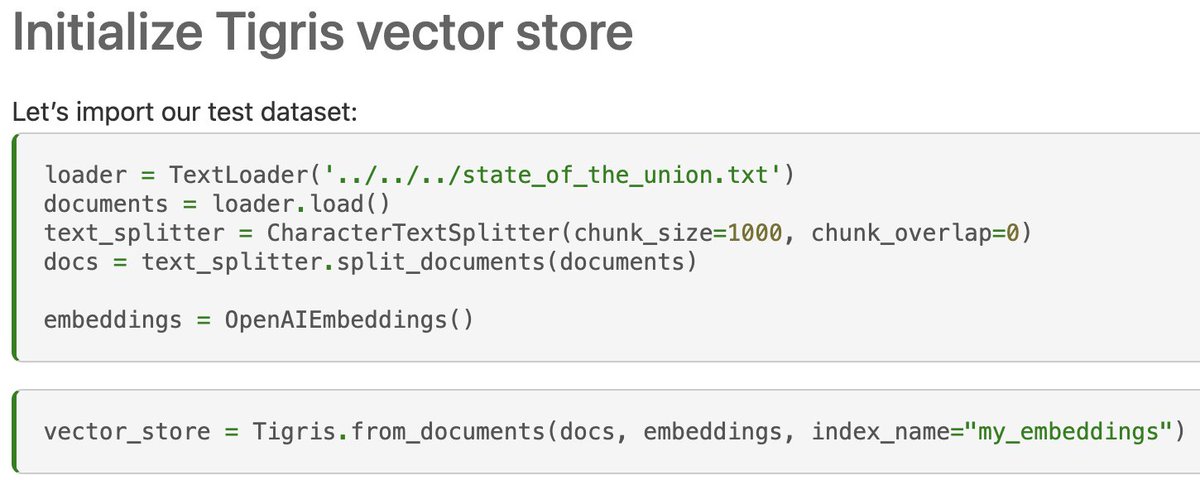
🦜🔗0.0.198 adds a lot of functionality to every step of the ingestion process!
+2 Document Loader (@airtable, XML)
+2 Text Splitter features
+2 Embedding providers
+3 Vectorstores
Lots of detail, so buckle up👇
+2 Document Loader (@airtable, XML)
+2 Text Splitter features
+2 Embedding providers
+3 Vectorstores
Lots of detail, so buckle up👇
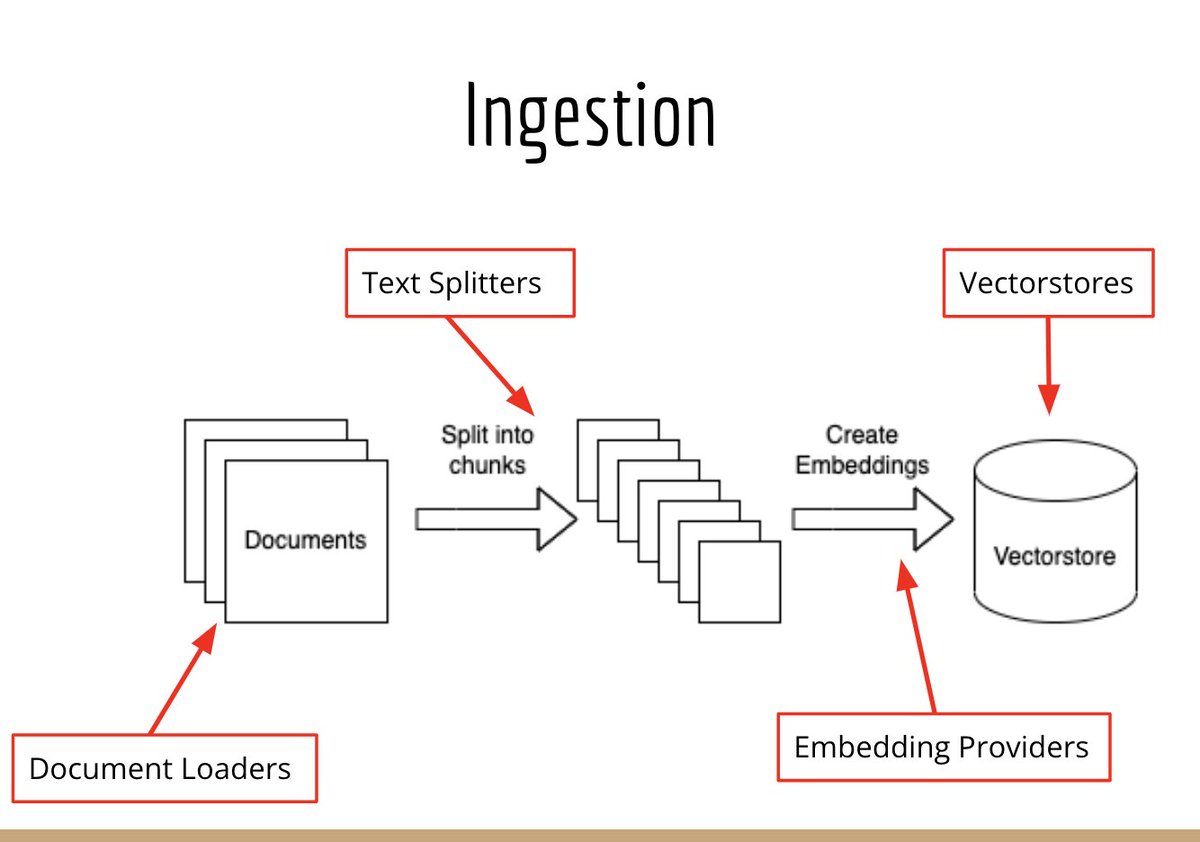
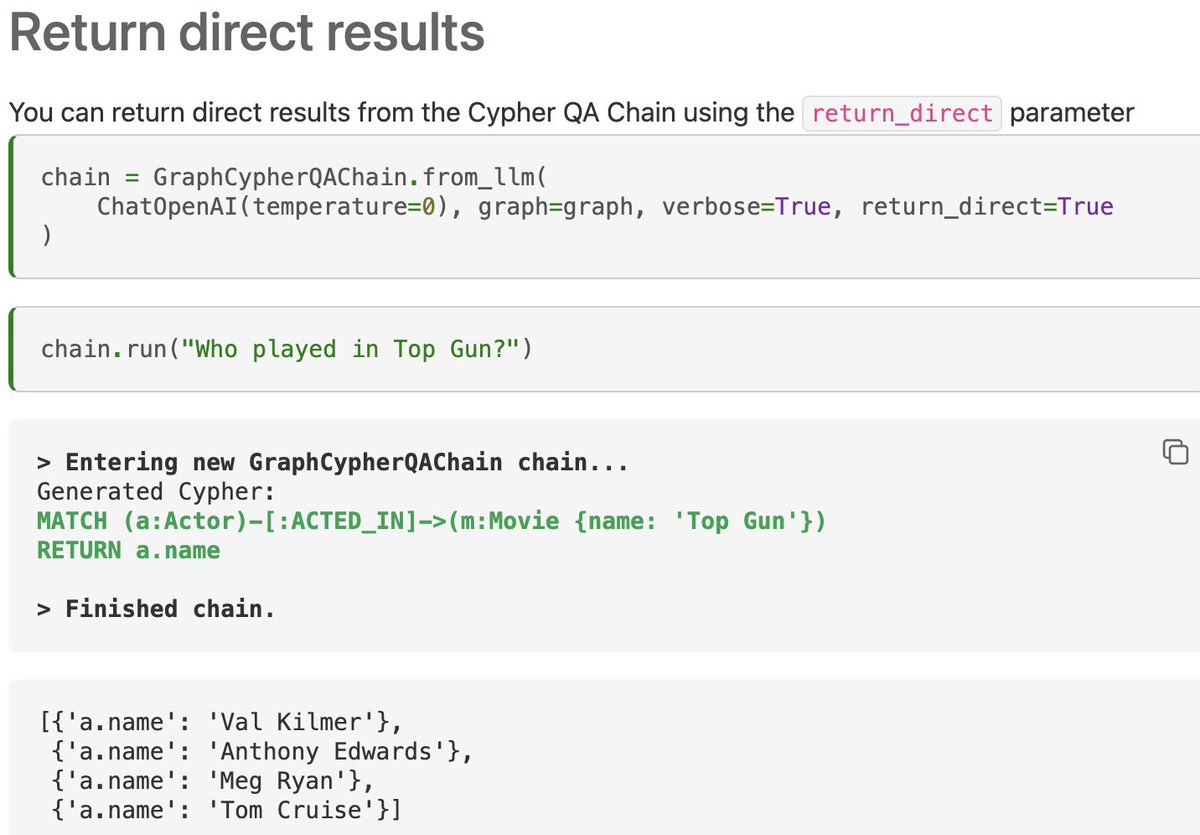
🏓Airtable Loader
@airtable is a super popular platform for storing and collecting data (we've used it internally for meetup sign ups)
You can now easily load data from there with our new document loader!
Docs: python.langchain.com/en/latest/modu…
@airtable is a super popular platform for storing and collecting data (we've used it internally for meetup sign ups)
You can now easily load data from there with our new document loader!
Docs: python.langchain.com/en/latest/modu…
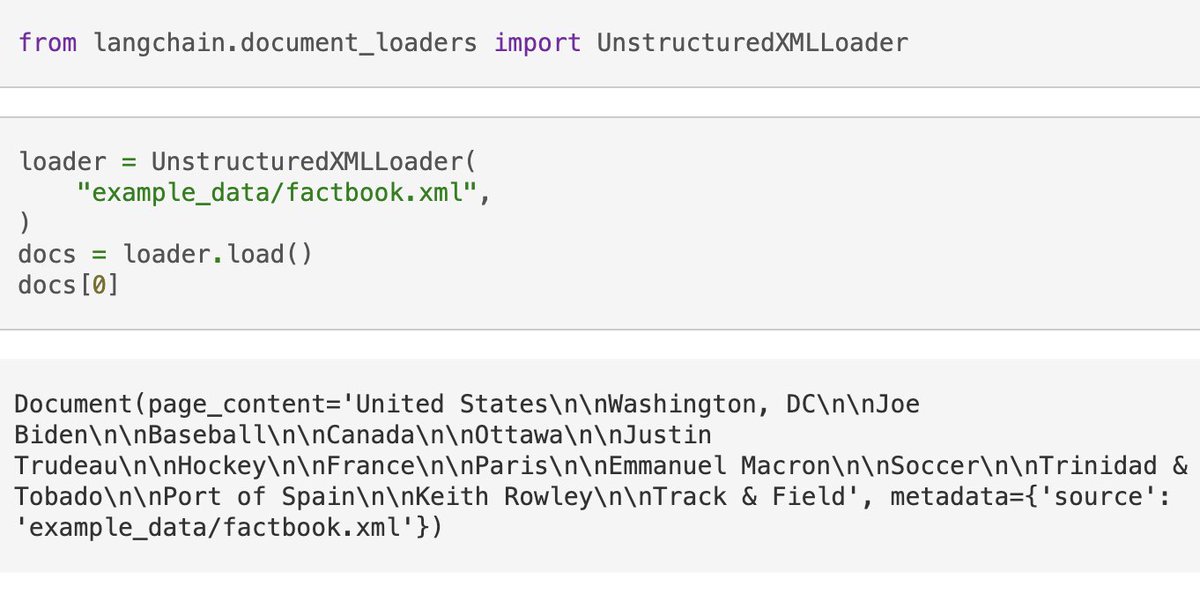
✖️ XML Loader
s/o to our friends at @UnstructuredIO for adding an XML loader!
@mrobinson0623 you're the best
Docs: python.langchain.com/en/latest/modu…
s/o to our friends at @UnstructuredIO for adding an XML loader!
@mrobinson0623 you're the best
Docs: python.langchain.com/en/latest/modu…
🤗 HuggingFace tokenizer Text Splitter
This text splitter uses @huggingface tokenizers to count the tokens in each chunk, and splits it that way
Thanks Jens Madsen for adding!
Docs: python.langchain.com/en/latest/modu…
This text splitter uses @huggingface tokenizers to count the tokens in each chunk, and splits it that way
Thanks Jens Madsen for adding!
Docs: python.langchain.com/en/latest/modu…
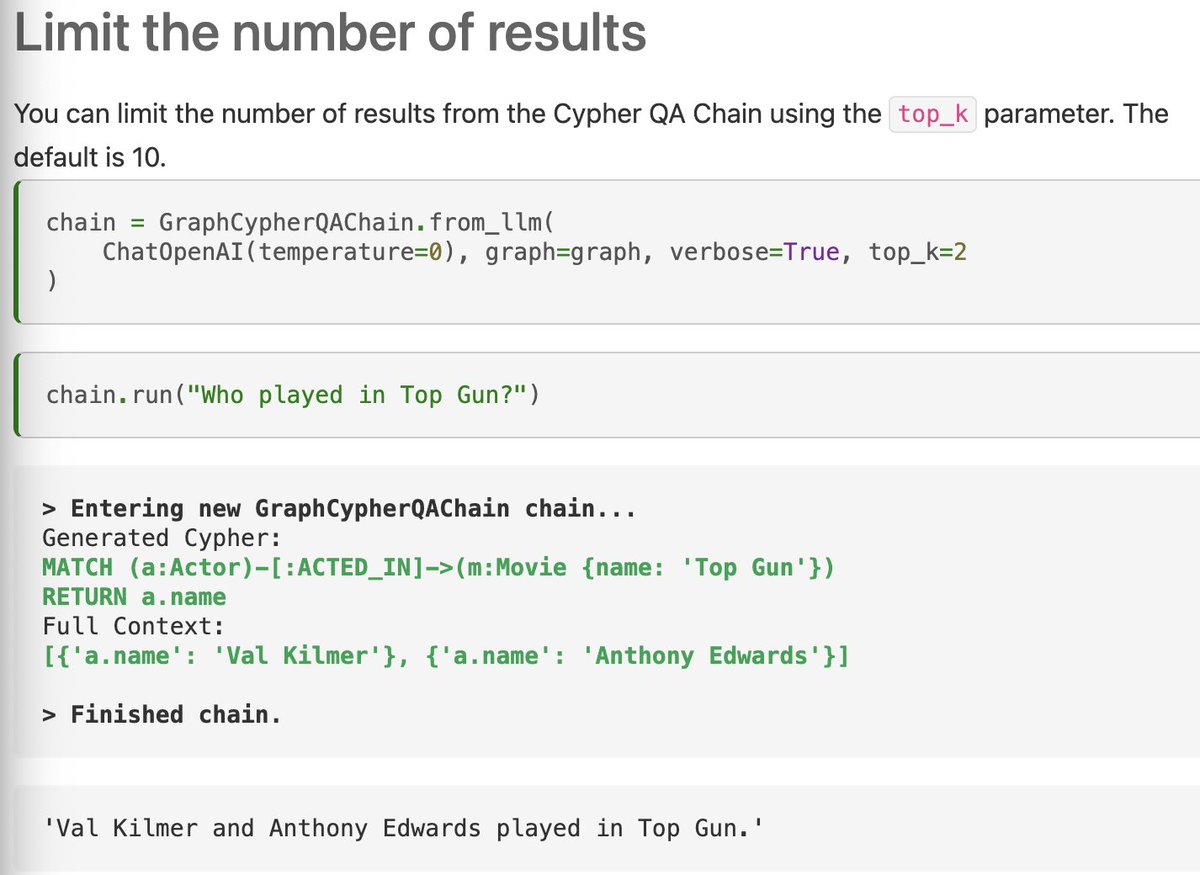
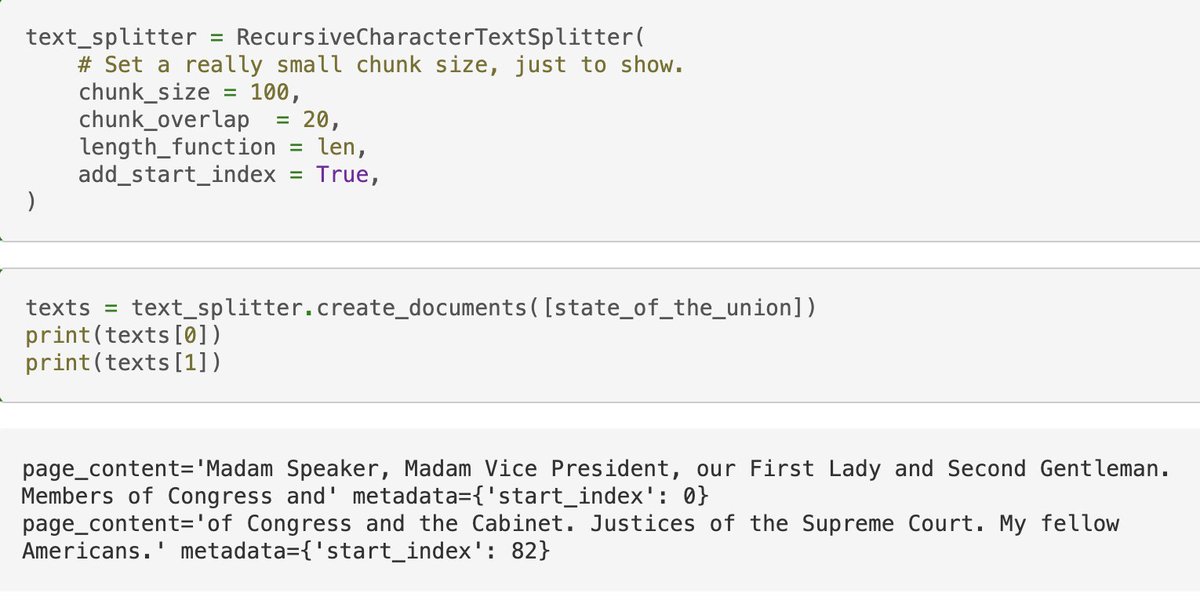
🤩 add_start_index
This addition from `felpigeon` helps to keep track of the chunks you create
It lets you include the starting position of each chunk within the original document in the metadata
Docs: python.langchain.com/en/latest/modu…
This addition from `felpigeon` helps to keep track of the chunks you create
It lets you include the starting position of each chunk within the original document in the metadata
Docs: python.langchain.com/en/latest/modu…
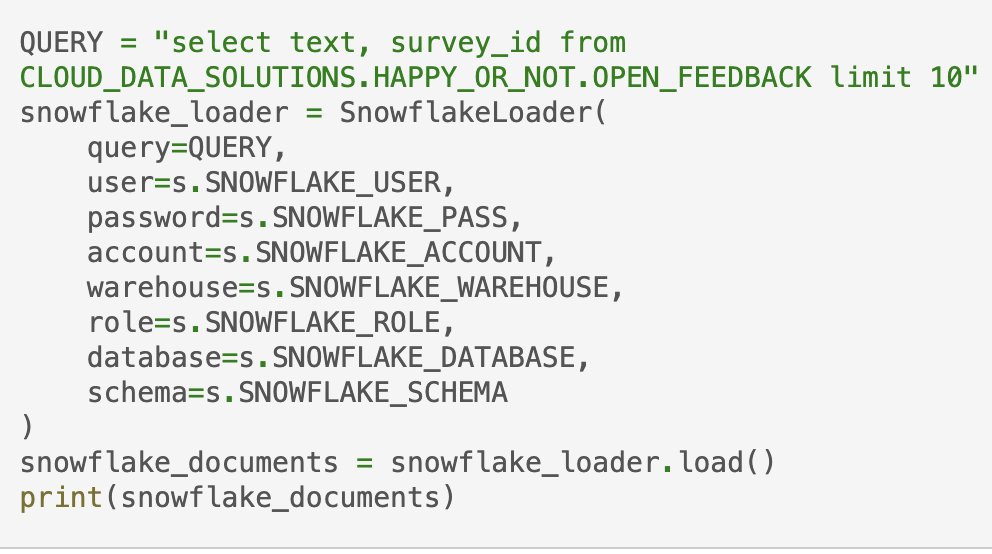
💨Dashscope Embeddings
Dashscope is DAMO Academys multilingual text unified vector model. It caters to multiple mainstream languages worldwide.
h/t wenmeng zhou
Docs: python.langchain.com/en/latest/modu…
Dashscope is DAMO Academys multilingual text unified vector model. It caters to multiple mainstream languages worldwide.
h/t wenmeng zhou
Docs: python.langchain.com/en/latest/modu…

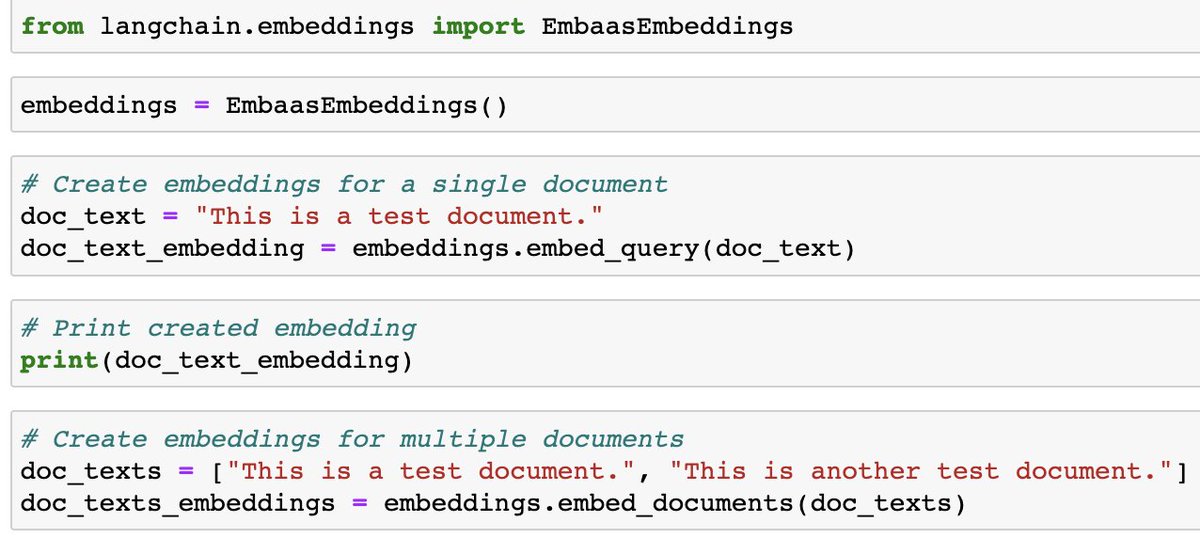
🫢Embaas Embeddings
embaas is a fully managed NLP API service that offers features like embedding generation, document text extraction, document to embeddings and more
Thanks to Julius Lipp for adding
Docs: python.langchain.com/en/latest/modu…
embaas is a fully managed NLP API service that offers features like embedding generation, document text extraction, document to embeddings and more
Thanks to Julius Lipp for adding
Docs: python.langchain.com/en/latest/modu…
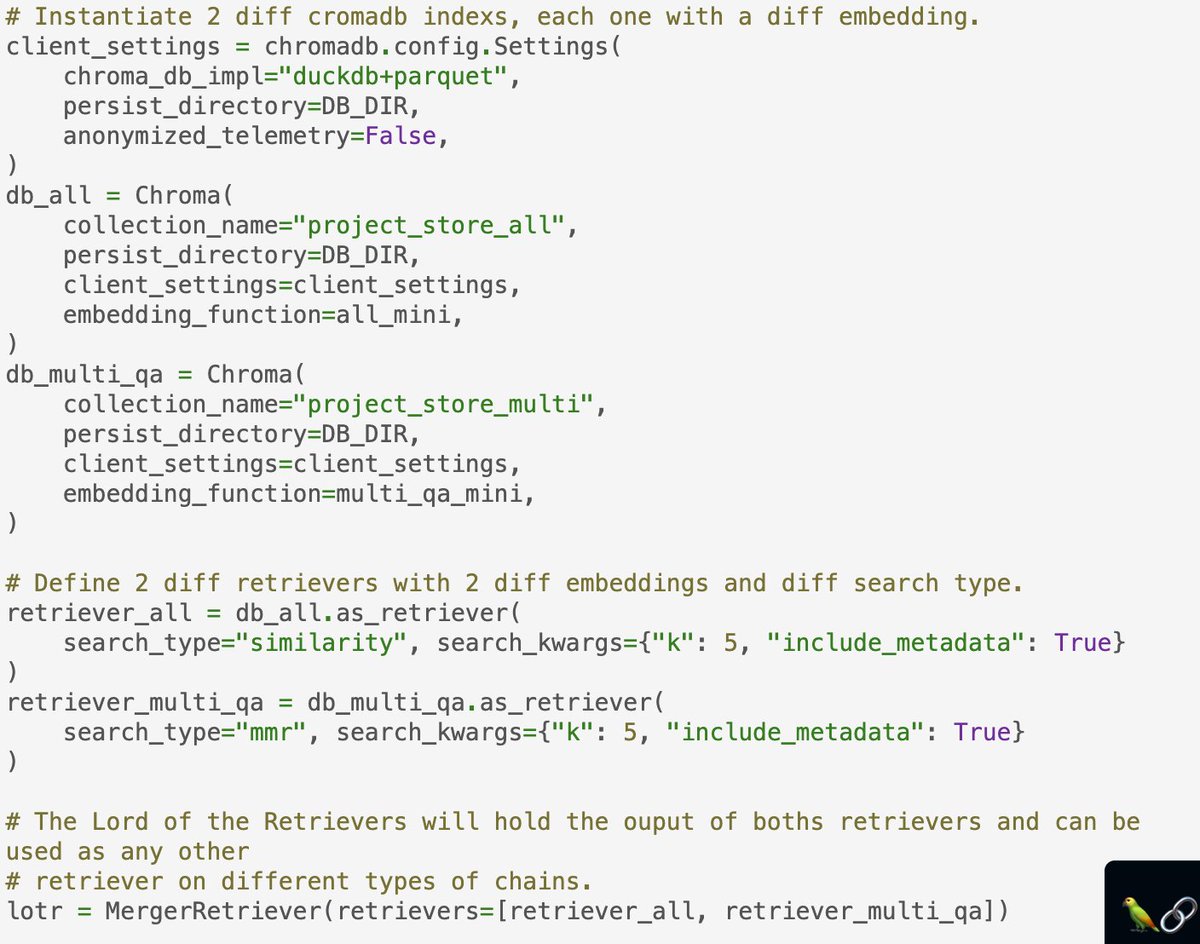
🧑⚖️AwaDB Vectorstore
AwaDB is an AI Native database for the search and storage of embedding vectors used by LLM Applications.
Thanks to ljeagle for adding
Docs: python.langchain.com/en/latest/modu…
AwaDB is an AI Native database for the search and storage of embedding vectors used by LLM Applications.
Thanks to ljeagle for adding
Docs: python.langchain.com/en/latest/modu…

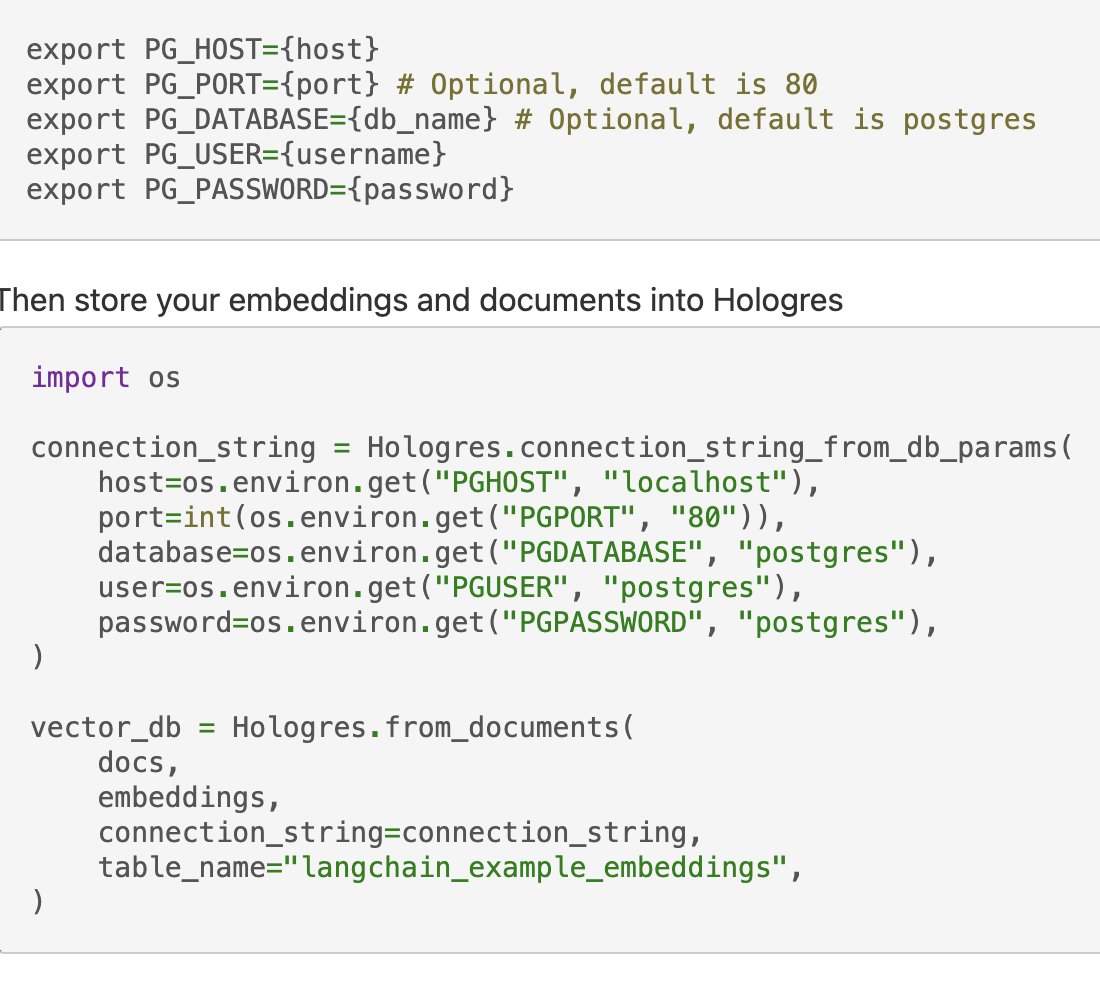
🕳️Hologres Vectorstore
Hologres is a unified real-time data warehousing service developed by Alibaba Cloud
Thanks Changgeng Zhao for adding
Docs: python.langchain.com/en/latest/modu…
Hologres is a unified real-time data warehousing service developed by Alibaba Cloud
Thanks Changgeng Zhao for adding
Docs: python.langchain.com/en/latest/modu…
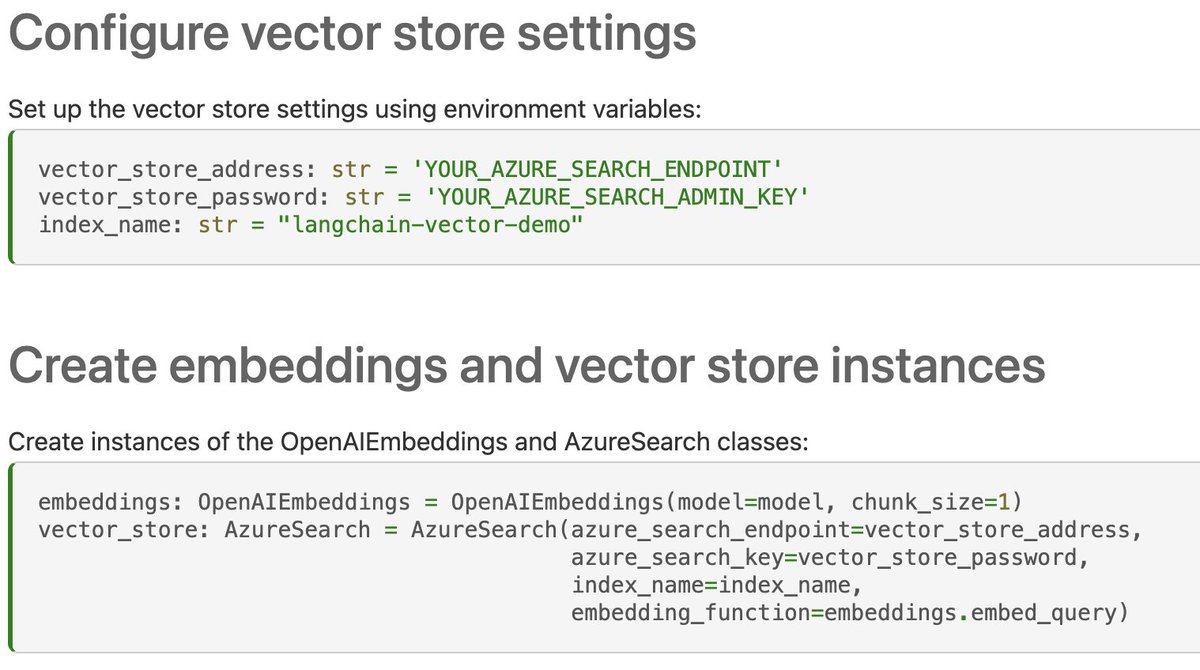
🟦Azure Cognitive Search Vectorstore
And finally, the biggest of them all - an integration with Azure Cognitive Search's new vectorstore functionality (still in beta)
Thanks to Fabrizio Ruocco for all his work in merging in!
Docs: python.langchain.com/en/latest/modu…
And finally, the biggest of them all - an integration with Azure Cognitive Search's new vectorstore functionality (still in beta)
Thanks to Fabrizio Ruocco for all his work in merging in!
Docs: python.langchain.com/en/latest/modu…
Which of these steps is the most challenging and deserves more love?
Or is there another step that we should improve on?
Or is there another step that we should improve on?
• • •
Missing some Tweet in this thread? You can try to
force a refresh