
1/14🧵Real world CHUNKING best practices thread:
🔍 A common question I get is: "How should I chunk my data and what's the best chunk size?" Here's my opinion based on my experience with @LangChainAI 🦜🔗and building production grade GenAI applications.
🔍 A common question I get is: "How should I chunk my data and what's the best chunk size?" Here's my opinion based on my experience with @LangChainAI 🦜🔗and building production grade GenAI applications.
2/14 Chunking is the process of splitting long pieces of text into smaller, hopefully semantically meaningful chunks. It's essential when dealing with large text inputs, as LLMs often have limitations on the amount of tokens that can be processed at once. (4k,8k,16k,100k) 

3/14 Eventually, we store all chunks in a vectorstore like @pinecone🌲 and perform similarity search on them then using the results as context to the LLM.
4/14 This approach, known as in-context learning or RAG (Retrieval-Augmented Generation), helps the language model answer with contextual understanding. 🧩🔎(check my thread on RAG)

5/14 Ideally, we want to keep semantically related pieces of data together when chunking. In @LangChainAI🦜🔗 , we use TextSplitters for chunking.

6/14 We need to specify to the @LangChainAI TextSplitters how we want to split the text and create the chunks. We can define the chunk size as well as the option for chunk overlap, although personally, I don't often utilize the chunk overlap feature.
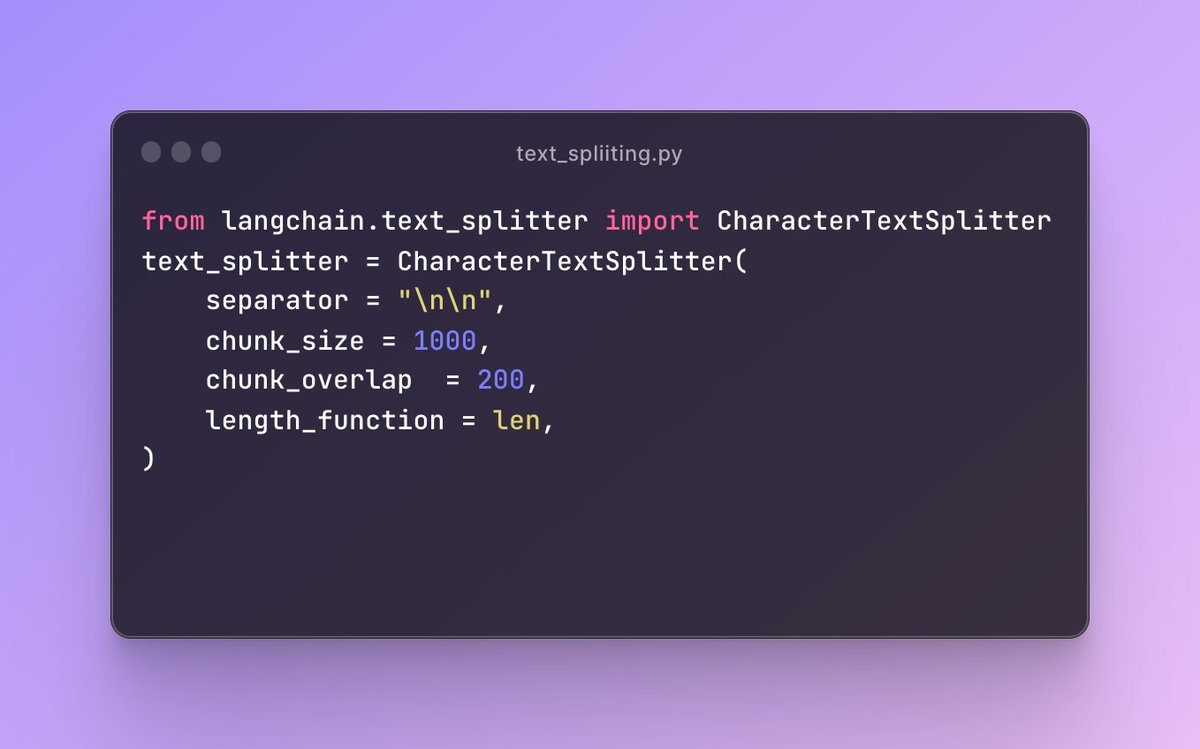
7/14 The most effective strategy I've found is chunking by the existing document formatting.
If we are chunking python files and wikipedia text files we ought to chunk them differently according to their file type.
If we are chunking python files and wikipedia text files we ought to chunk them differently according to their file type.

8/14 Example: In Python, a good separator for chunking can be '\ndef' to represent a function. It's considered best practice to keep functions short, typically no longer than 20 lines of code (unless, of course, you're a Data Scientist and have a knack for longer functions 😂

9/14 So here the chunk size of 300 can be a good heuristic IMO.
Remember there is no silver bullet☑️ and you MUST benchmark everything you do to get optimal results.
Remember there is no silver bullet☑️ and you MUST benchmark everything you do to get optimal results.
10/14 An advantage of @LangChainAI 🦜🔗 text splitters is our ability to create dynamically optimized splitters based on needs so we have full flexibility here

11/14 However Imagine having a ready to go- text splitter specifically tailored to you file extension: .md, .html, or .py files.
@hwchase17 and @LangChainAI 🦜🔗 team, please consider implementing this!) This can saves us lazy devs tons of time with a "best practice" built in.
@hwchase17 and @LangChainAI 🦜🔗 team, please consider implementing this!) This can saves us lazy devs tons of time with a "best practice" built in.

12/14 Rule of thumb👍: When determining the chunk size --> balance. Size should be small enough to ensure effective processing by the LLM, while also being long enough to provide humans with a clear understanding of the semantic meaning within each chunk.
13/15 For text files I found that 500 works well.
When chunking is done correctly, it greatly improves information retrieval. Remember to consider the type of file you're working with when chunking. Each file format requires a different set of rules for optimal chunking.
When chunking is done correctly, it greatly improves information retrieval. Remember to consider the type of file you're working with when chunking. Each file format requires a different set of rules for optimal chunking.
14/15 I teach @LangChainAI 🦜🔗 elaborately in my @udemy course with almost 5k students and 630+ reviews
udemy.com/course/langcha…
Twitter only limited discount:
TWITTER9DCC71C67A9AA
udemy.com/course/langcha…
Twitter only limited discount:
TWITTER9DCC71C67A9AA
15/15 What are your best @LangChainAI🦜🔗 chunking strategies?
would love to hear your thought😎😎😎
@pinecone 🌲 Would love to hear your take on this as well.
#ENDOFTHREAD🧵🧵🧵
would love to hear your thought😎😎😎
@pinecone 🌲 Would love to hear your take on this as well.
#ENDOFTHREAD🧵🧵🧵
• • •
Missing some Tweet in this thread? You can try to
force a refresh














