
0/12 📢🧵Unpopular Opinion thread - Vectorstores are here to stay! 🔐🚀
I've noticed a lot of tweets lately discussing how #LLM s with larger context windows will make vector-databases obsolete. However, I respectfully disagree. Here's why:
I've noticed a lot of tweets lately discussing how #LLM s with larger context windows will make vector-databases obsolete. However, I respectfully disagree. Here's why:

1/12 @LangChainAI 🦜🔗 @pinecone 🌲 @weaviate_io @elastic @Redisinc @milvusio let me know what you think😎 I think you will like this.

2/12: Too much context hurts performance. As the context window expands, #LLM s can "forget" information from the beginning of the prompt. With contexts larger than ~50k tokens, this becomes a challenge.

3/12: LLMs are statistical creatures, "guessing" the next word. When we provide massive context, the number of possible guesses dramatically increases, including bad ones. This raises the odds of hallucinating wrong words.
4/12: In-context learning or RAG, powered by vectorstores, is incredibly powerful. It allows us to build advanced systems that rely on finding relevant context. Relevant context is key to addressing the task at hand.
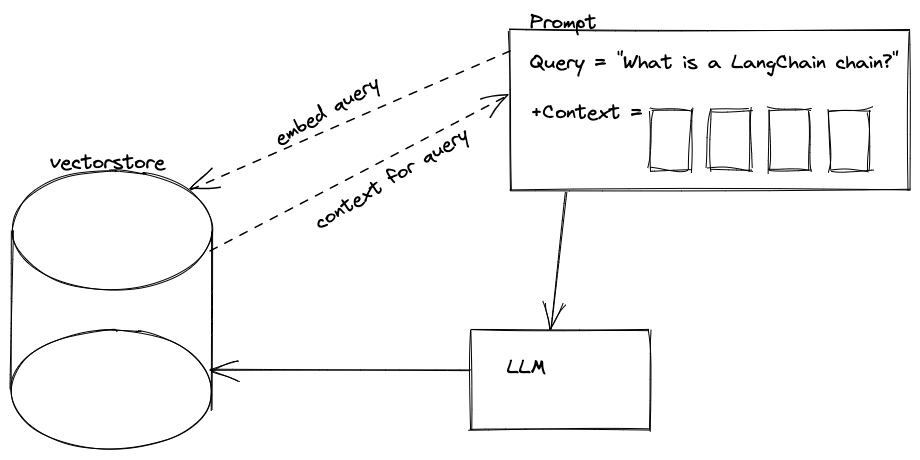
5/12: Example: Claud by @AnthropicAI can digest 100k tokens, indicating the trend of models moving toward increasingly larger context. In the future, large context will become the standard

6/12: From my experience, sending "enough" context, precise and laser-focused, yields better results than flooding the model with unnecessary "junk" context. Quality over quantity.

7/12: Just like in caching, a bigger cache doesn't always mean better performance. There can be a knee graph, and we might reach a point where adding more context doesn't significantly improve results. We could plateau.
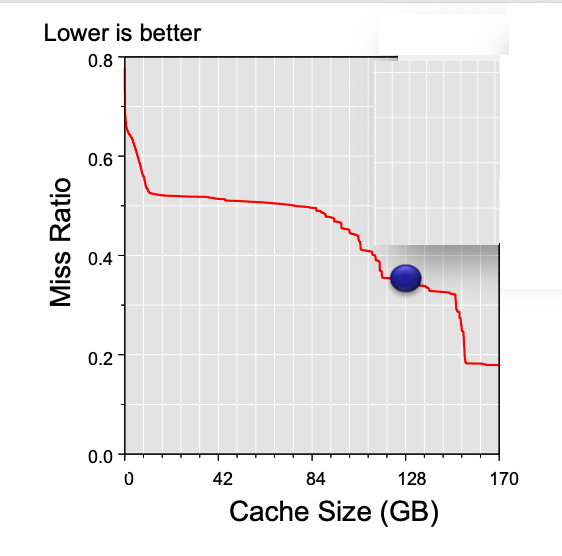
8/12: IMO, a limit of around 20-30k tokens will be the max and offer the sweet spot. If we exceed the common 8k token limit, we have elegant techniques like map reduce, reranking, refinement, summarization —all supported by @LangChainAI 🦜 🔗doing the heavy lifting for us
10/12: It's also important to consider the cost factor. Since we pay per token, minimizing the number of tokens used becomes crucial. Optimal context selection helps optimize costs while maintaining quality. 💰💡
11/12: Vectorstores are invaluable tools for similarity and hybrid search. They assist us in finding the most relevant context which can also be filtered by metadata, empowering us to build complex apps effectively.
12/12 :I teach @LangChainAI 🦜🔗 elaborately and LLM application development in my @udemy course with 5k+ students and 700+ reviews
Twitter only limited discount: TWITTER9DCC71C67A9AAudemy.com/course/langcha…
Twitter only limited discount: TWITTER9DCC71C67A9AAudemy.com/course/langcha…
13/12 @jeffreyhuber giving an honorable mention for Chroma DB open source
https://t.co/CnzbEWu2TAtrychroma.com
https://t.co/CnzbEWu2TAtrychroma.com

• • •
Missing some Tweet in this thread? You can try to
force a refresh











