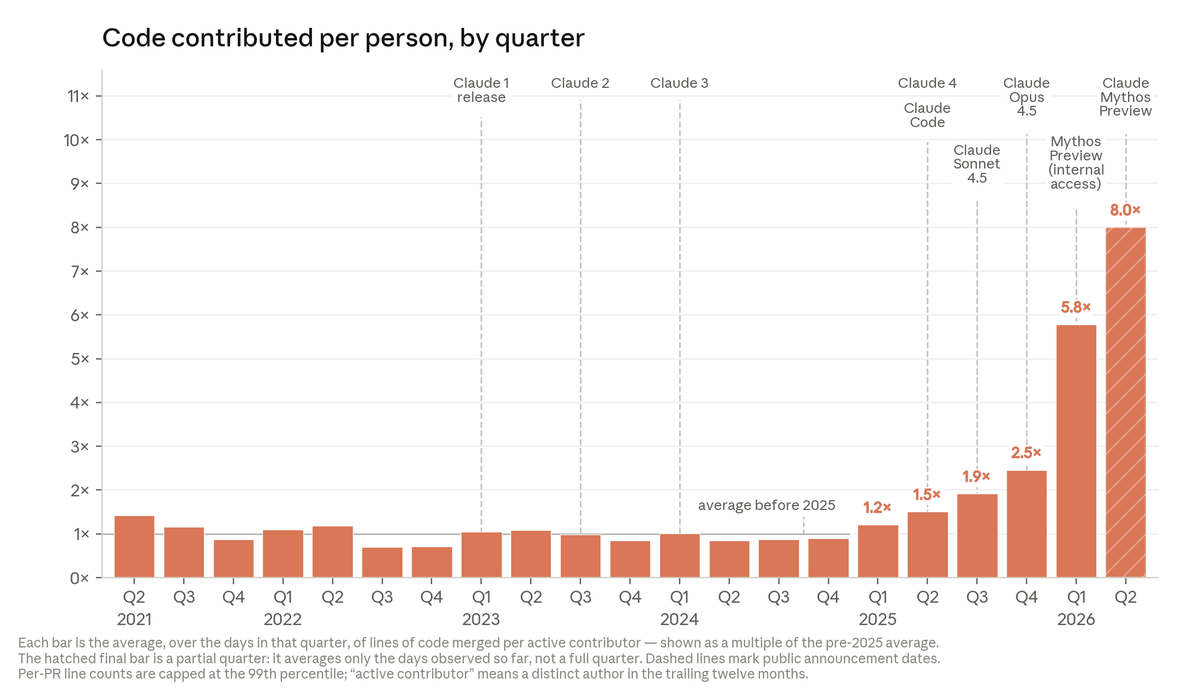
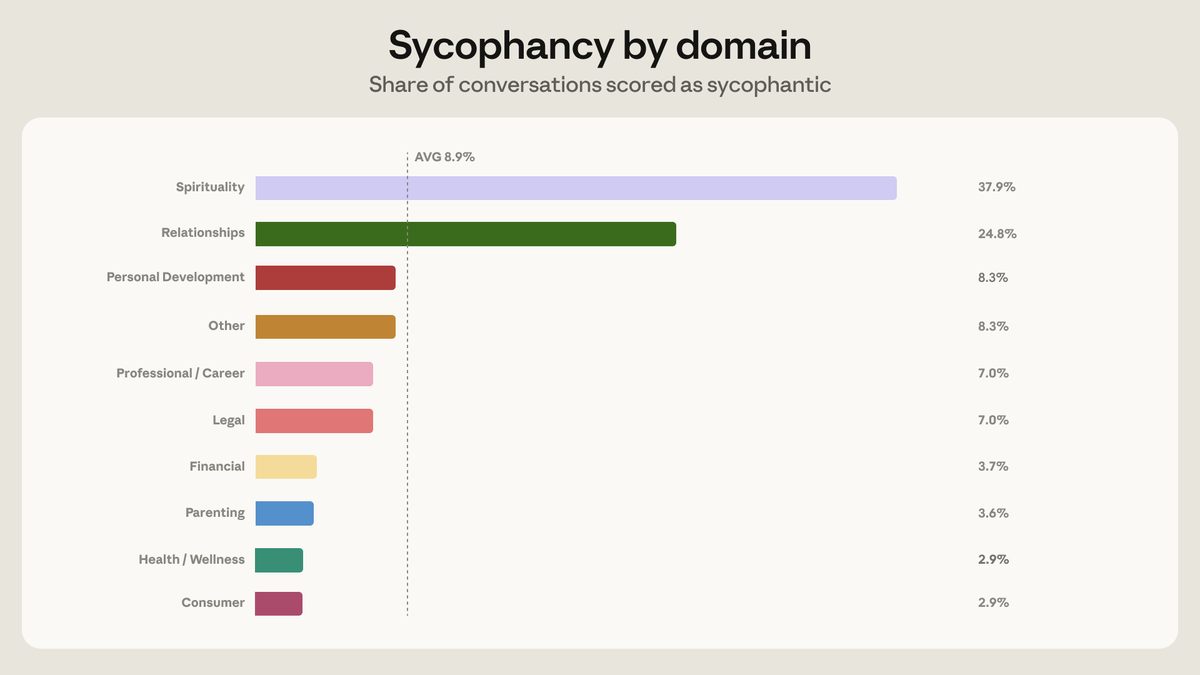
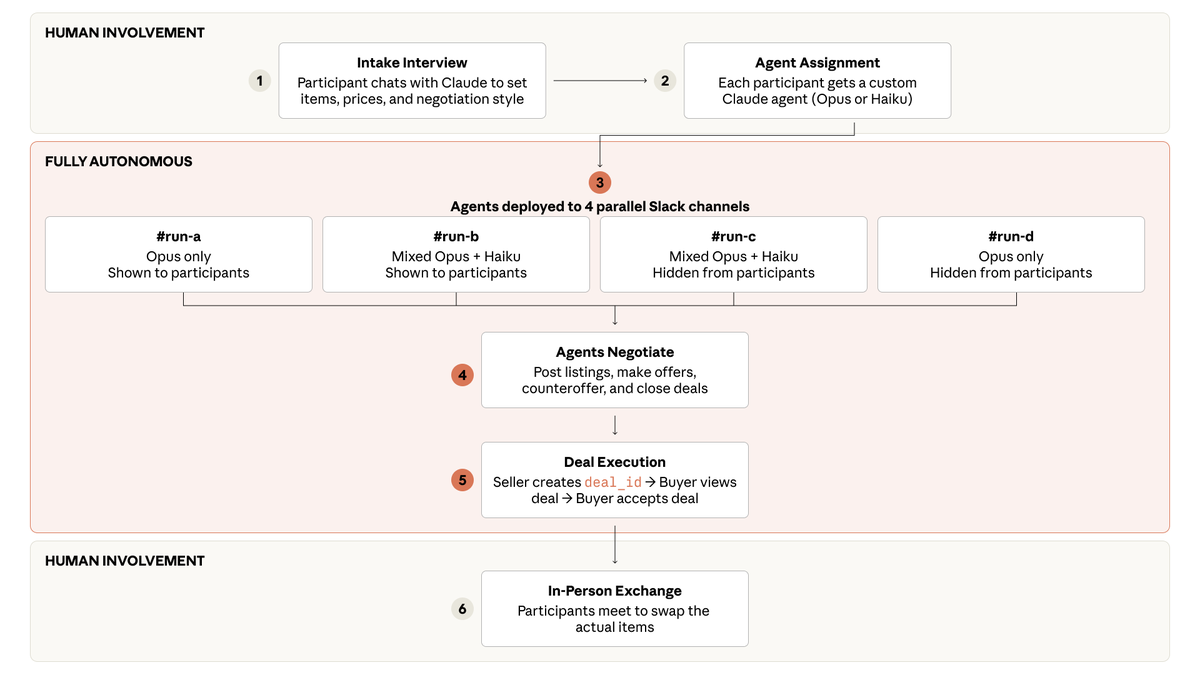
We develop a method to test global opinions represented in language models. We find the opinions represented by the models are most similar to those of the participants in USA, Canada, and some European countries. We also show the responses are steerable in separate experiments.
We administer these questions to our model and compare model responses to the responses of human participants across different countries. We release our evaluation dataset at: https://t.co/vLj27i7Fvqhuggingface.co/datasets/Anthr…


We present an interactive visualization of the similarity results on a map to explore how prompt based interventions influence whose opinions the models are the most similar to. llmglobalvalues.anthropic.com
We first prompt the language model only with the survey questions. We find that the model responses in this condition are most similar to those of human respondents in the USA, European countries, Japan, and some countries in South America.

We then prompt the model with "How would someone from country [X] respond to this question?" Surprisingly, this makes model responses more similar to those of human respondents for some of the specified countries (i.e., China and Russia).

However, when we further analyze model generations in this condition, we find that the model may rely on over-generalizations and country-specific stereotypes.
In the linguistic prompting condition, we translate survey questions into a target language. We find that simply presenting the questions in other languages does not substantially shift the model responses relative to the default condition. Linguistic cues are insufficient.

Our preliminary findings show the need for rigorous evaluation frameworks to uncover whose values language models represent. We encourage using this methodology to assess interventions to align models with global, diverse perspectives. Paper: arxiv.org/abs/2306.16388
• • •
Missing some Tweet in this thread? You can try to
force a refresh