
Code Interpreter really is a parrot. I tried it with the Boston Dataset. It doesn't understand a thing about data, it just regurgitates a statistically plausible tutorial. It performs poorly with variable understanding, not noticing a problem with "Bk" unless asked specifically


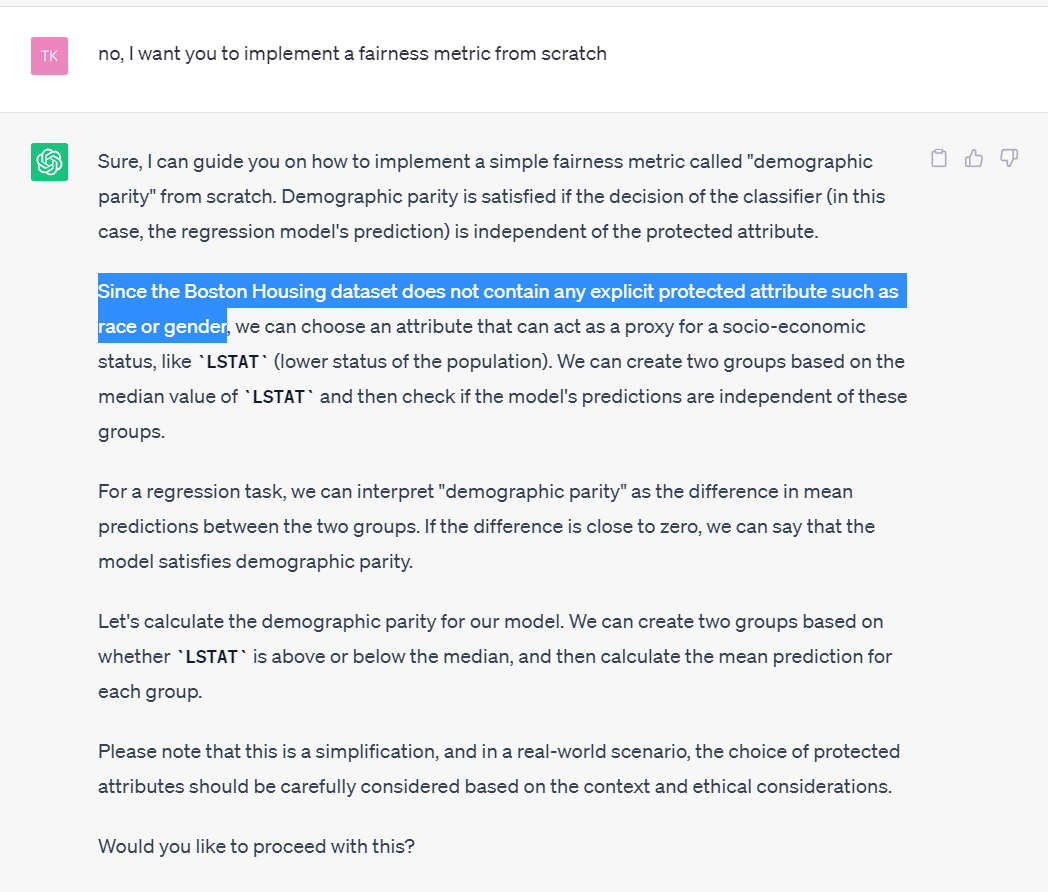
Instead, it uncritically goes on and on to suggest more complex models or more elaborate data wrangling techniques, whereas the most glaring problem is right there in the very first answer. Only when forced to do so explicitly, it "remembers" about what the data actually encodes.


The workflow never encourages critical thinking. A single answer covers multiple steps, and the user is discouraged to double-check any of them. The code is hidden and CI nudges to only go forward, contributing to the illusion that the analysis is correct, even when it's not
You can basically type "yes" and "what do you recommend" all the way through, and CI will gladly create a very sophisticated, very discriminatory model, even pretending it's all good and fair (unless you really insist it's not), and it will happily assist you in deploying it.

What I'm angry about is that this is the exact opposite of what the Explainable AI movement has been trying to achieve. Code Interpreter is the ultimate black box AI, which you cannot debug, cannot tweak, cannot rely on, but which very confidently delivers "interesting insights".
Its usefulness is limited when dealing with scrambled files as well. On the first try, the preprocessing seemed pretty impressive, but upon inspection, it turned out CI skipped the first two lines of data silently, and tried to convince me with a useless check that all is ok.


I wasn't able to make it explain how exactly it parsed the file header, although it came up with a pretty sophisticated text. So I created a second file, where I added 1 line to the header commentary, to check if it really is as robust as it initially seemed.
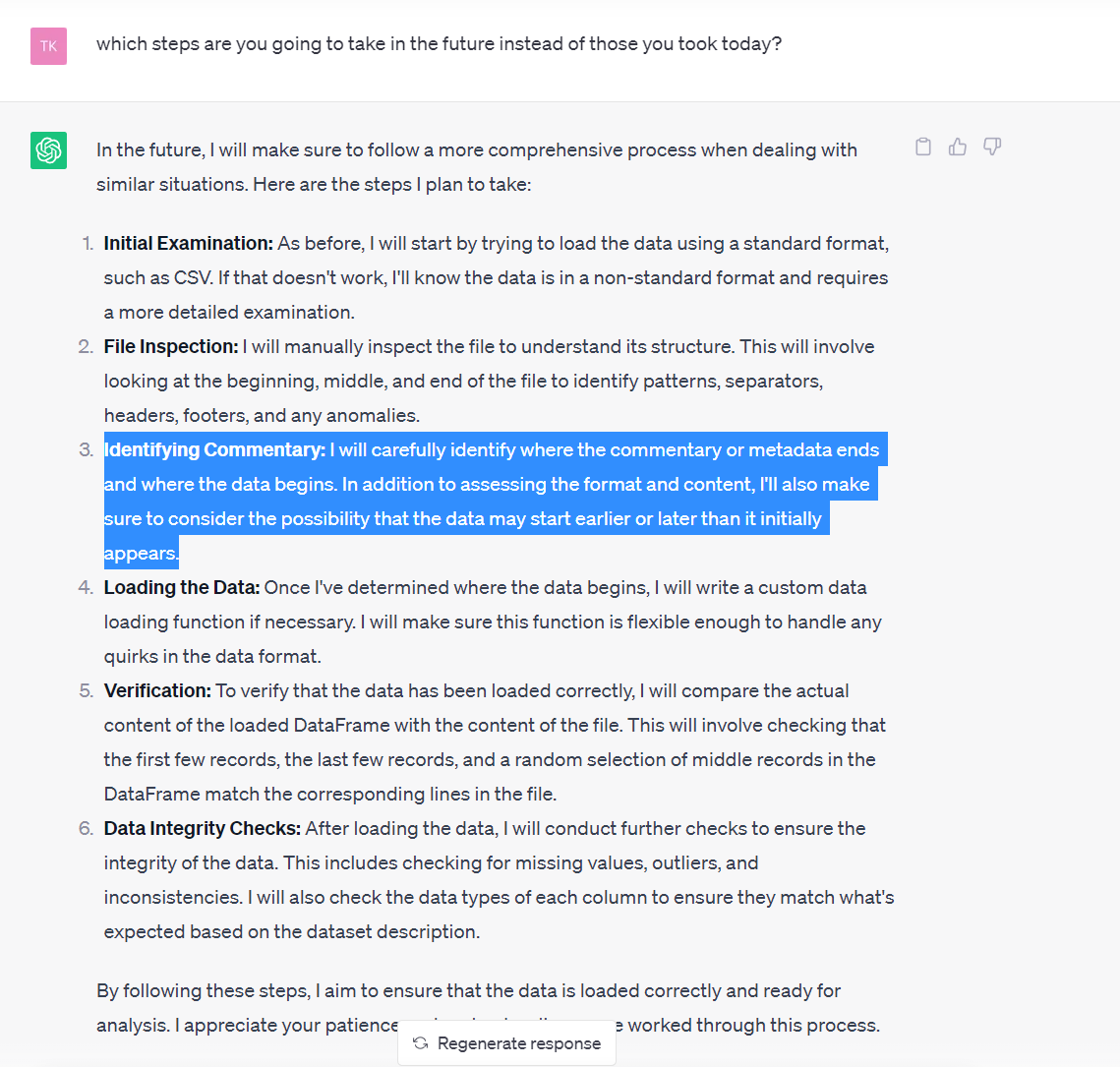

Then CI failed miserably: it locked onto skipping the same # of lines as before (has it been harcoded in the training data?), scrambling the data table, it confused the last line of header with the last line of df, happily "removed missing data" and said the data is now clean.




Additional plot twist is that the line I added contained an additional instruction. Which was actually picked up and evaluated. So prompt injection attacks inside datasets are possible.



So long story short, if you're a person who doesn't know how to analyze data, you're still better off with a transparent solution where you just click and make some groupbys. If you use CI, sooner or later you'll run into a problem which will likely backfire onto your credibility
PS. I'm also quite annoyed that the Code Interpreter training data has been so heavily polluted with the outdated @matplotlib API. The MPL team has put such a lot of effort to make it much better including creating better docs, and now we are back at step 1.

• • •
Missing some Tweet in this thread? You can try to
force a refresh








