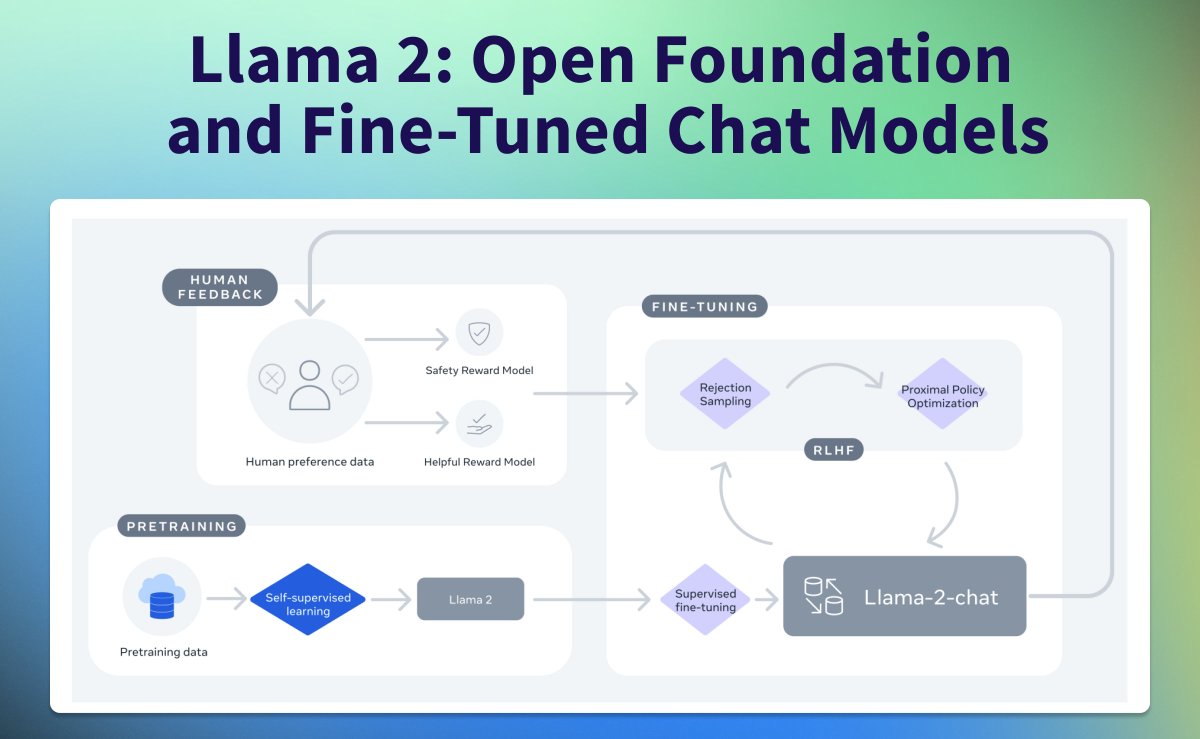
Is Llama 2 special or just a better iteration of Llama 1? 🤔 Over the weekend, I had time to read the paper in which Meta released. 📖
Below are some of my findings, which you might have missed📝
🧵 1/6
Below are some of my findings, which you might have missed📝
🧵 1/6
🧠 A 34B version may come later after more testing
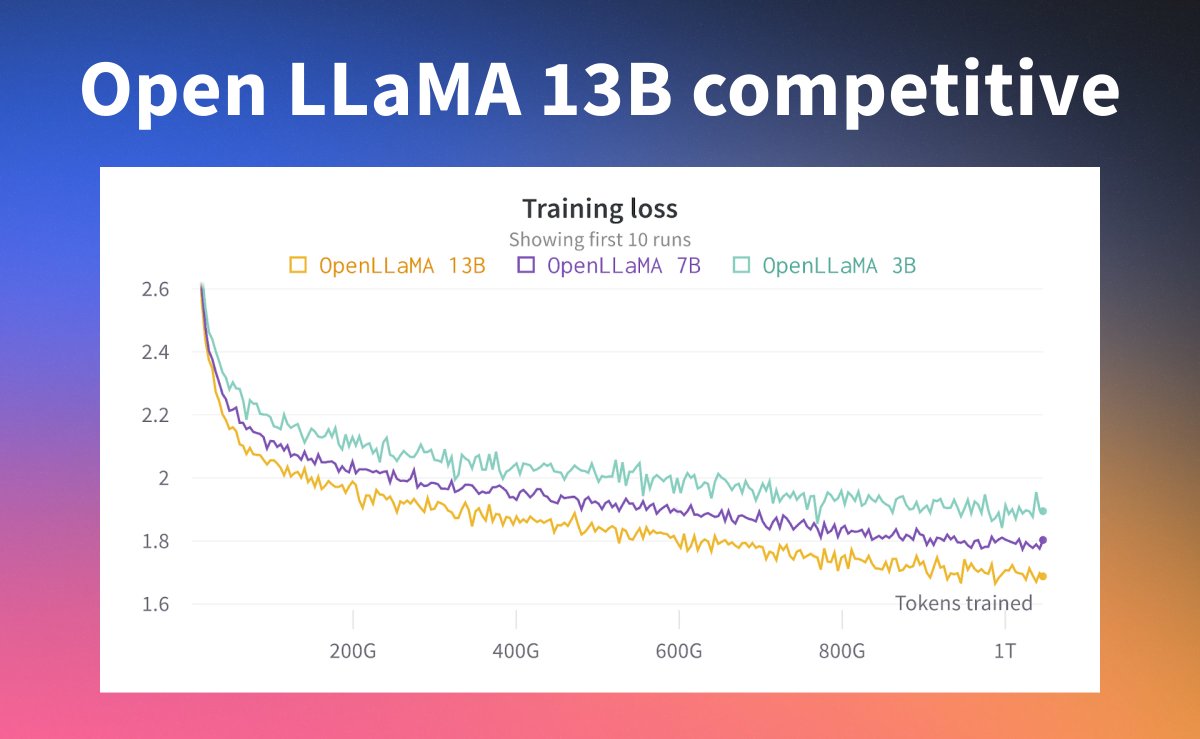
⚖️ The 7B model used a 285x token to parameter ratio, with loss still decreasing.
💰 Training the 7B would cost ~$1M in AWS compute (5$ per A100 on AWS on-demand)
🛫 Llama Chat was started before Llama 2 finished training
🧵2/6
⚖️ The 7B model used a 285x token to parameter ratio, with loss still decreasing.
💰 Training the 7B would cost ~$1M in AWS compute (5$ per A100 on AWS on-demand)
🛫 Llama Chat was started before Llama 2 finished training
🧵2/6
◼️ User prompts were masked/zeroed in SFT & RLHF training
👑 Reward Model (RM) accuracy is one of the most important proxies for Chat model
🚀 Collecting data in batches helped improve the overall model, since RM and LLM where iteratively re-trained.
🧵3/6
👑 Reward Model (RM) accuracy is one of the most important proxies for Chat model
🚀 Collecting data in batches helped improve the overall model, since RM and LLM where iteratively re-trained.
🧵3/6
🔢 Used Rejection Sampling (RS) to distill knowledge from 70B for a better SFT dataset
🤔 Only used RS for the first 3 versions, then extended to RS + PPO
🆕 Proposed GAtt, inspired by Context Distillation, to augment fine-tuning data for better multi-turn conversations
🧵4/6
🤔 Only used RS for the first 3 versions, then extended to RS + PPO
🆕 Proposed GAtt, inspired by Context Distillation, to augment fine-tuning data for better multi-turn conversations
🧵4/6
💡 RS + RM can boost performance by 10% compared to SFT
🛠 Chat model learned to use tools.
Check out the full paper here:
🧵5/6arxiv.org/abs/2307.03172
🛠 Chat model learned to use tools.
Check out the full paper here:
🧵5/6arxiv.org/abs/2307.03172
Meta says, “…reinforcement learning proved highly effective, particularly given its cost and time effectiveness. Our findings underscore that the crucial determinant of RLHF’s success lies in the synergy it fosters between humans and LLMs throughout the annotation process.”
wrong paper 🙃 arxiv.org/abs/2307.09288
• • •
Missing some Tweet in this thread? You can try to
force a refresh