
Releasing LLongMA-2 13b, a Llama-2 model, trained at 8k context length using linear positional interpolation scaling. The model was trained in collaboration with @theemozilla of @NousResearch and @kaiokendev1. 

The model can be found on @huggingface here: huggingface.co/conceptofmind/…
We worked directly with @kaiokendev1, to extend the context length of the Llama-2 13b model through fine-tuning. The model passes all our evaluations and maintains the same perplexity at 8k extrapolation surpassing the performance of other recent methodologies.
A Llama-2 7b model trained at 16k context length will release soon on @huggingface here: huggingface.co/conceptofmind/…
The model has identical performance to LLaMA 2 under 4k context length, performance scales directly to 8k, and works out-of-the-box with the new version of transformers (4.31) or with `trust_remote_code` for <= 4.30.
Applying the method to the rotary position embedding requires only slight changes to the model's code by dividing the positional index, t, by a scaling factor.
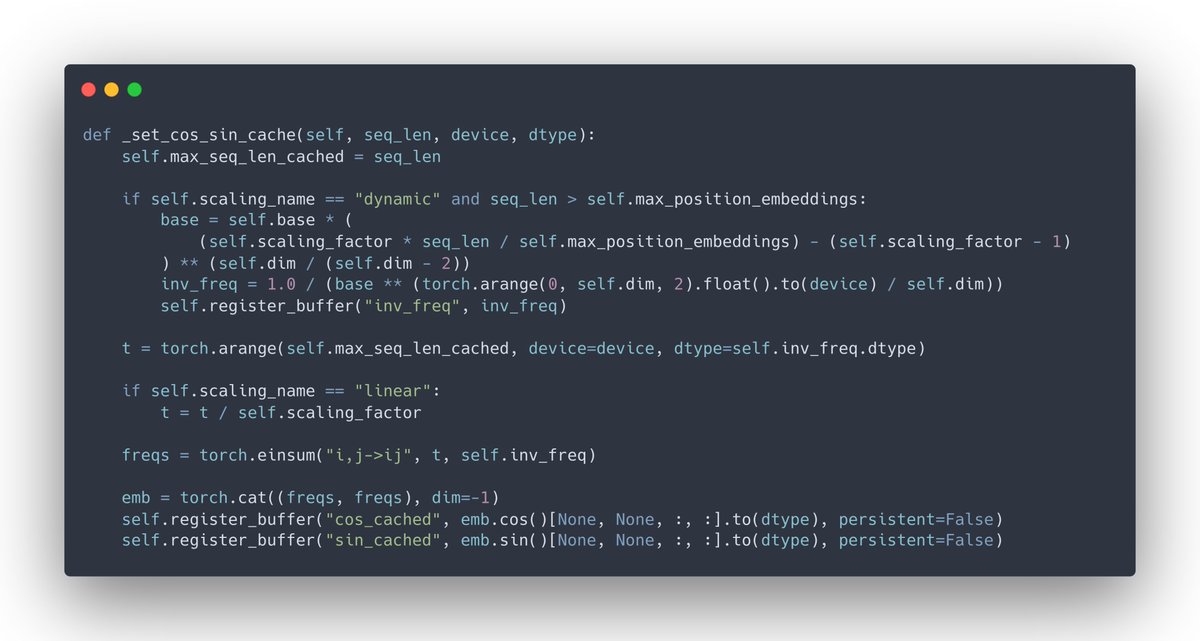
The repository containing @theemozilla’s implementation of scaled rotary embeddings can be found here: github.com/jquesnelle/sca…
If you would like to learn more about scaling rotary embeddings, I would strongly recommend reading @kaiokendev1's blog posts on his findings: kaiokendev.github.io
A PR to add scaled rotary embeddings to @huggingface transformers has been added by @joao_gante and merged: github.com/huggingface/tr…
The model was further trained for ~1 billion tokens on @togethercompute's Red Pajama dataset. The context length of the examples varies: huggingface.co/datasets/toget…
The pre-tokenized dataset will be available here for you to use soon: huggingface.co/datasets/conce…
I would also recommend checking out the phenomenal research by @OfirPress on ALiBi which laid the foundation for many of these scaling techniques: arxiv.org/abs/2108.12409
It is also worth reviewing the paper, A Length-Extrapolatable Transformer, and xPos technique which also applies scaling to rotary embeddings: arxiv.org/pdf/2212.10554…
We previously trained the first publicly available model with rotary embedding scaling here:
https://twitter.com/EnricoShippole/status/1655599301454594049?s=20
You can find out more about the @NousResearch organization here: huggingface.co/NousResearch
The compute for this model release is all thanks to the generous sponsorship by @carperai, @EMostaque, and @StabilityAI. This is not an official @StabilityAI product.
A big thank you to @AiEleuther for facilitating the discussions about context-length extrapolation as well. Truly an awesome open-source team and community.
If you have any questions about the data or model be sure to reach out and ask! I will try to respond promptly.
The previous suite of LLongMA model releases can be found here:
https://twitter.com/EnricoShippole/status/1677346578720256000?s=20
All of the models can be found on Huggingface: huggingface.co/conceptofmind
The previous LLongMA-2 7b model can be found here:
https://twitter.com/EnricoShippole/status/1682054848584228866?s=20
Testimonials about LLongMA-2 7b can be seen on @huggingface here: huggingface.co/conceptofmind/…
• • •
Missing some Tweet in this thread? You can try to
force a refresh




