Advice for ML beginners💡
GitHub actions are *free* computing that makes your life easier.
Here are 3 use cases for ML projects ↓
GitHub actions are *free* computing that makes your life easier.
Here are 3 use cases for ML projects ↓
➡️ Continuous Integration and Deployment (CI/CD)
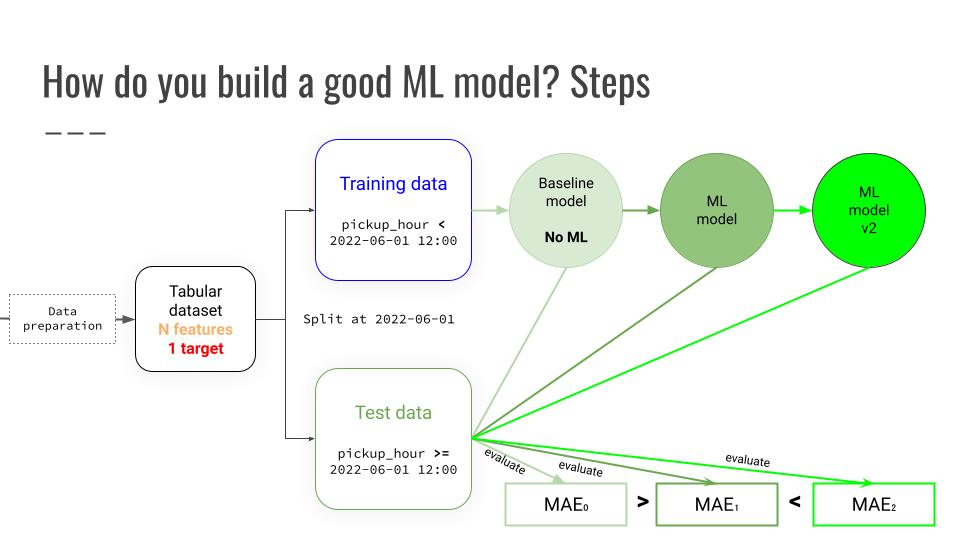
Machine Learning is software engineering. As such, it is crucial you automate:
→ code updates (aka integration), and
→ code releases to your production environment (aka deployment)
Machine Learning is software engineering. As such, it is crucial you automate:
→ code updates (aka integration), and
→ code releases to your production environment (aka deployment)
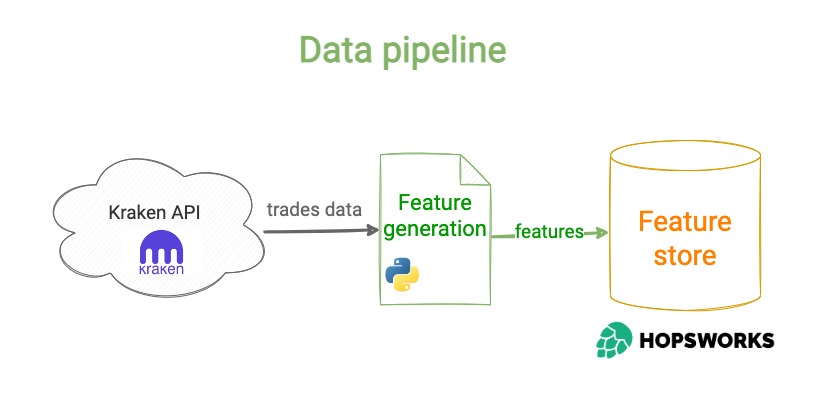
➡️ Batch feature pipelines
This is a program that runs on a chron-like schedule, that fetches raw data from a data source (e.g. a data warehouse), computes ML features, and saves them to a storage service (e.g. a feature store).
Feature pipelines are present in every ML system.
This is a program that runs on a chron-like schedule, that fetches raw data from a data source (e.g. a data warehouse), computes ML features, and saves them to a storage service (e.g. a feature store).
Feature pipelines are present in every ML system.
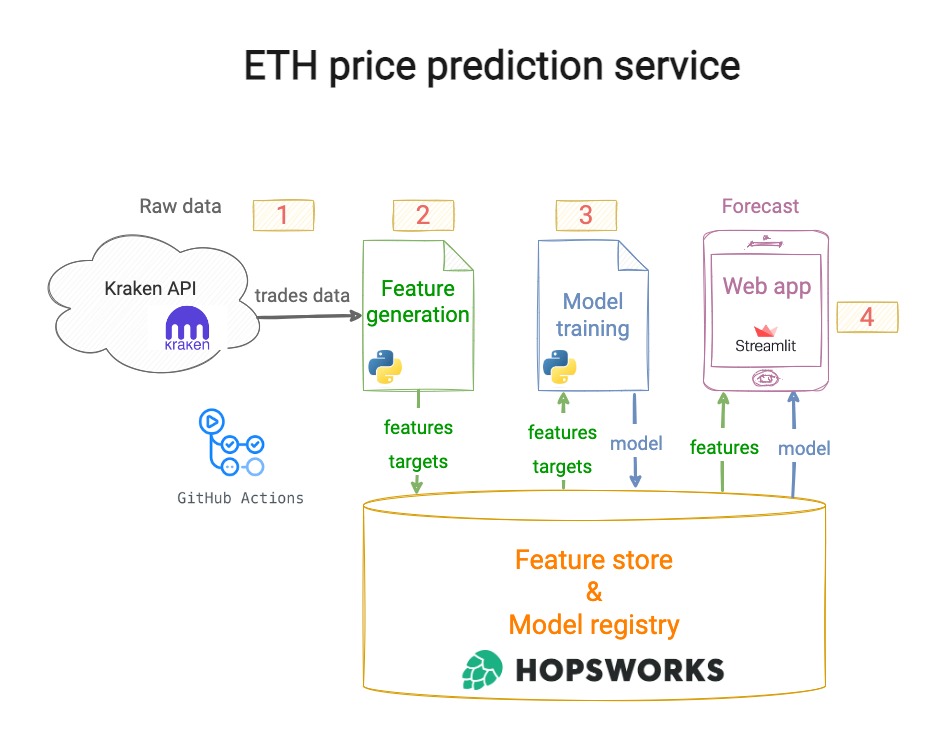
➡️ Inference pipelines
Batch scoring is one of the most popular ways to generate fresh predictions from an ML model.
They fetch recent features, and a model artifact, generate predictions, and save them in a storage layer.
Batch scoring is one of the most popular ways to generate fresh predictions from an ML model.
They fetch recent features, and a model artifact, generate predictions, and save them in a storage layer.
Wanna get more tweets like this?
→ Follow me @paulabartabajo_
Wanna help me spread the word?
→ Like/Retweet the first tweet below ↓↓↓
→ Follow me @paulabartabajo_
Wanna help me spread the word?
→ Like/Retweet the first tweet below ↓↓↓
https://twitter.com/1408789941040058369/status/1683824501954338816
• • •
Missing some Tweet in this thread? You can try to
force a refresh