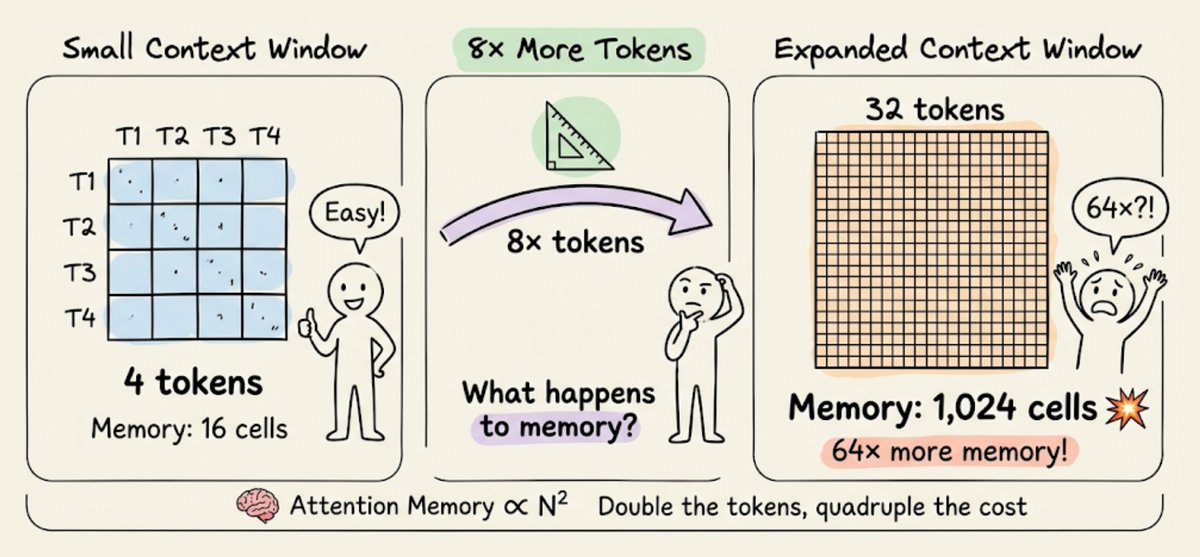
Microsoft is offering FREE courses in following areas:
- AI
- IOT
- Data Science
- Machine Learning
A project-based pedagogy that allows you to learn while building! 🚀
Read More ...👇
- AI
- IOT
- Data Science
- Machine Learning
A project-based pedagogy that allows you to learn while building! 🚀
Read More ...👇

1️⃣ AI for beginners
A 12-week, 24-lesson curriculum all about Artificial Intelligence.
You'll learn about:
- Neural Nets
- Deep Learning
- Knowledge representation
- Genetic Algorithms & multi-agent systems
Check this out 👇
https://t.co/rZ3Jdw2Le8microsoft.github.io/AI-For-Beginne…
A 12-week, 24-lesson curriculum all about Artificial Intelligence.
You'll learn about:
- Neural Nets
- Deep Learning
- Knowledge representation
- Genetic Algorithms & multi-agent systems
Check this out 👇
https://t.co/rZ3Jdw2Le8microsoft.github.io/AI-For-Beginne…

2️⃣ IOT
Learn about IOT by doing project that cover the journey of food from farm to table.
This includes farming, logistics, manufacturing, retail and consumer - all popular industry areas for IoT devices.
Check this out 👇
https://t.co/o4GJM8gHzmmicrosoft.github.io/IoT-For-Beginn…
Learn about IOT by doing project that cover the journey of food from farm to table.
This includes farming, logistics, manufacturing, retail and consumer - all popular industry areas for IoT devices.
Check this out 👇
https://t.co/o4GJM8gHzmmicrosoft.github.io/IoT-For-Beginn…

3️⃣ Machine Learning
A great course on classical machine learning, using Scikit-learn!
Check this out👇 https://t.co/vpUIczCZ5Tmicrosoft.github.io/ML-For-Beginne…
A great course on classical machine learning, using Scikit-learn!
Check this out👇 https://t.co/vpUIczCZ5Tmicrosoft.github.io/ML-For-Beginne…
4️⃣ Data Science
This course covers Deep Learning & Data Science in more details!
Each lesson includes:
- hands-on assignments
- pre & post-lesson quizzes
- instructions to complete the lesson & solutions
Check this out👇
https://t.co/YmOsSEWr7Cmicrosoft.github.io/Data-Science-F…
This course covers Deep Learning & Data Science in more details!
Each lesson includes:
- hands-on assignments
- pre & post-lesson quizzes
- instructions to complete the lesson & solutions
Check this out👇
https://t.co/YmOsSEWr7Cmicrosoft.github.io/Data-Science-F…

That's a wrap!
If you interested in:
- Python 🐍
- Machine Learning 🤖
- Maths for ML 🧮
- MLOps 🛠
- CV/NLP 🗣
- LLMs 🧠
Find me → @akshay_pachaar ✔️
Subscribe to my Newsletter→
Everyday, I share tutorials on above topics!
Cheers!mlspring.beehiiv.com/subscribe
If you interested in:
- Python 🐍
- Machine Learning 🤖
- Maths for ML 🧮
- MLOps 🛠
- CV/NLP 🗣
- LLMs 🧠
Find me → @akshay_pachaar ✔️
Subscribe to my Newsletter→
Everyday, I share tutorials on above topics!
Cheers!mlspring.beehiiv.com/subscribe
• • •
Missing some Tweet in this thread? You can try to
force a refresh