Medicine is inherently multimodal.
Thrilled to share Med-PaLM M, the first demonstration of a generalist multimodal biomedical AI system with a stellar team @GoogleAI @GoogleDeepMind @GoogleHealth
Paper: https://t.co/ZgEtG0gXEsarxiv.org/pdf/2307.14334…
Thrilled to share Med-PaLM M, the first demonstration of a generalist multimodal biomedical AI system with a stellar team @GoogleAI @GoogleDeepMind @GoogleHealth
Paper: https://t.co/ZgEtG0gXEsarxiv.org/pdf/2307.14334…
Med-PaLM M is a large multimodal generative model that flexibly encodes and interprets biomedical data spanning clinical language, medical imaging, genomics and more performing competently on a diverse array of tasks - all with the same set of model weights. 
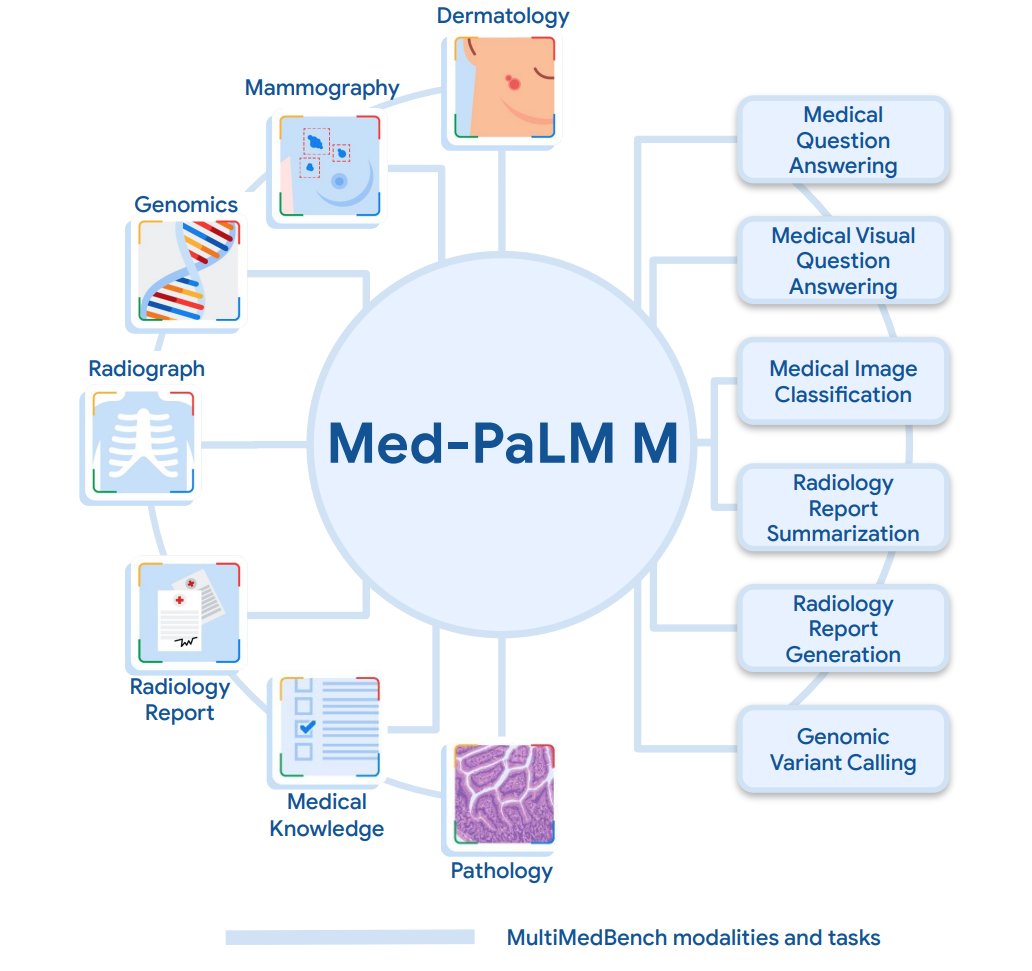
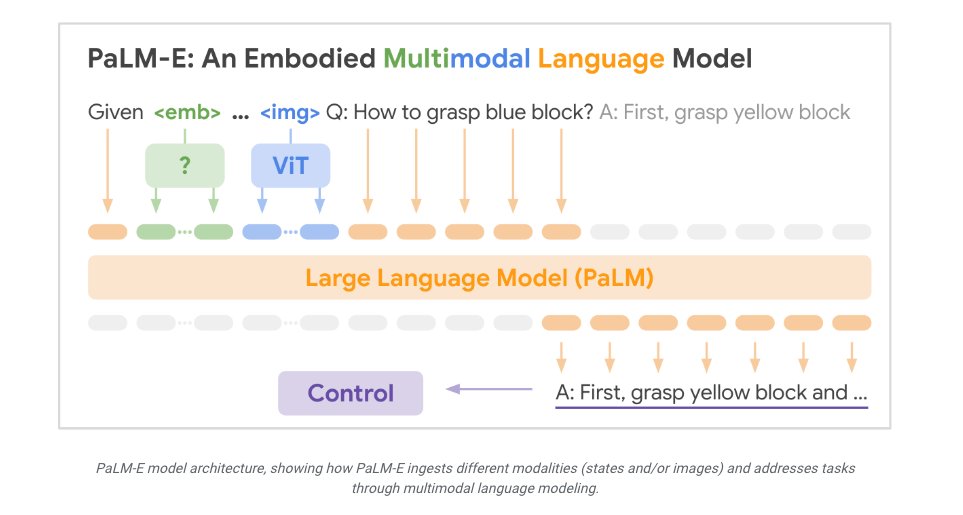
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi Med-PaLM M is built by fine tuning and aligning PaLM-E - an embodied multimodal language model from @GoogleAI - to the biomedical domain using MultiMedBench, a newly curated open source biomedical benchmark.
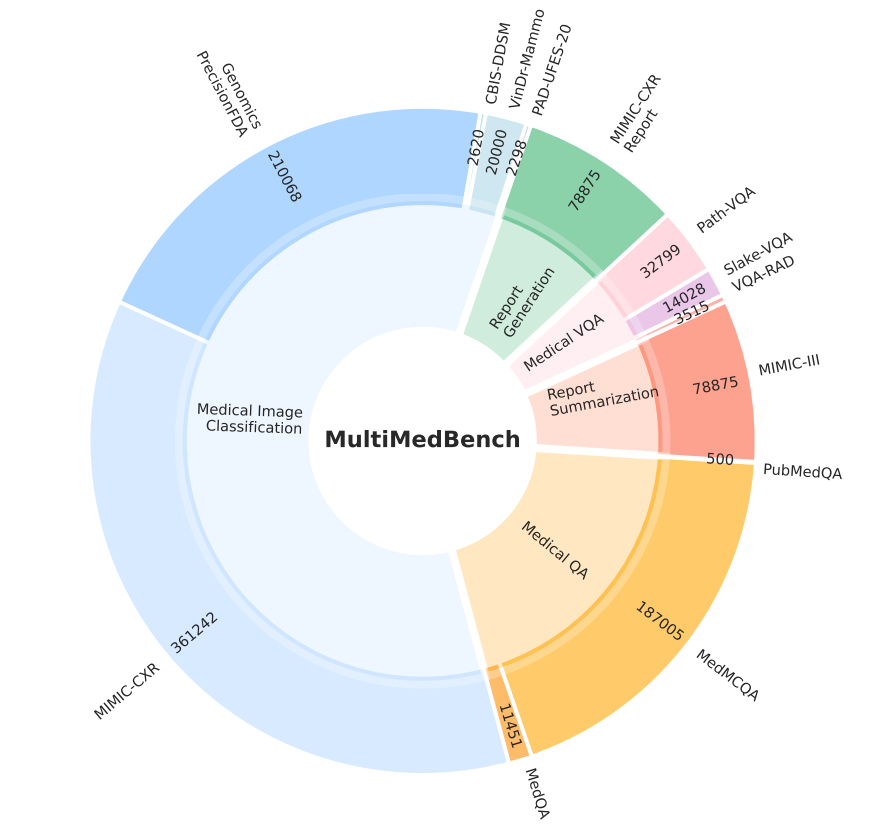
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI MutliMedBench spans 7 biomedical modalities and 14 diverse tasks such as medical QA, radiology report generation, genomic variant calling and more with over 1 milliion samples.
We hope the curation of MultiMedBench will further spur the development of generalist biomedical AI.
We hope the curation of MultiMedBench will further spur the development of generalist biomedical AI.
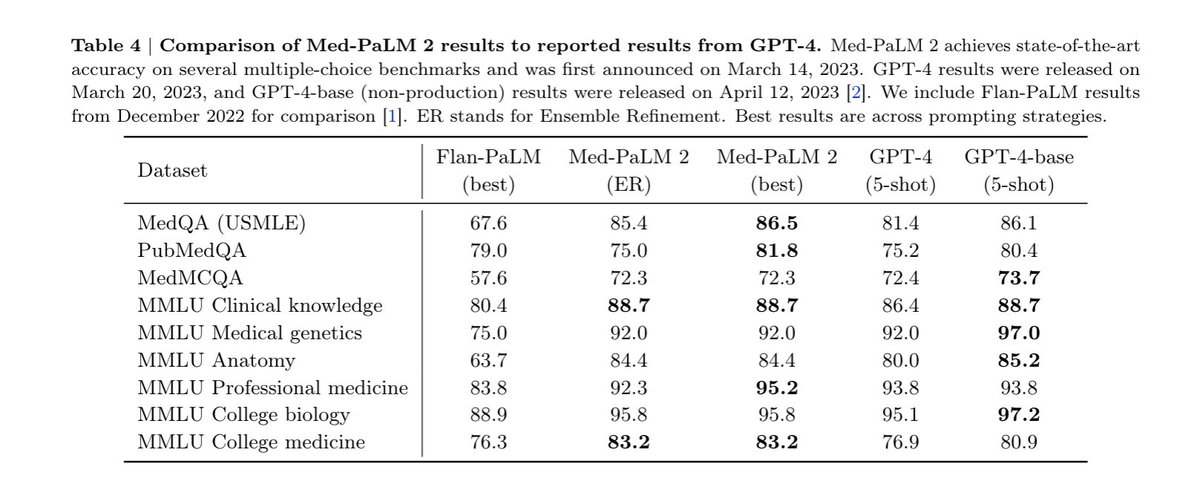
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI Across all tasks in MultiMedBench, Med-PaLM M reaches performance competitive or exceeding SOTA, often exceeding specialist models by a wide margin.
Further, Med-PaLM M also significantly outperforms PaLM-E demonstrating the importance of biomedical fine tuning and alignment.
Further, Med-PaLM M also significantly outperforms PaLM-E demonstrating the importance of biomedical fine tuning and alignment.
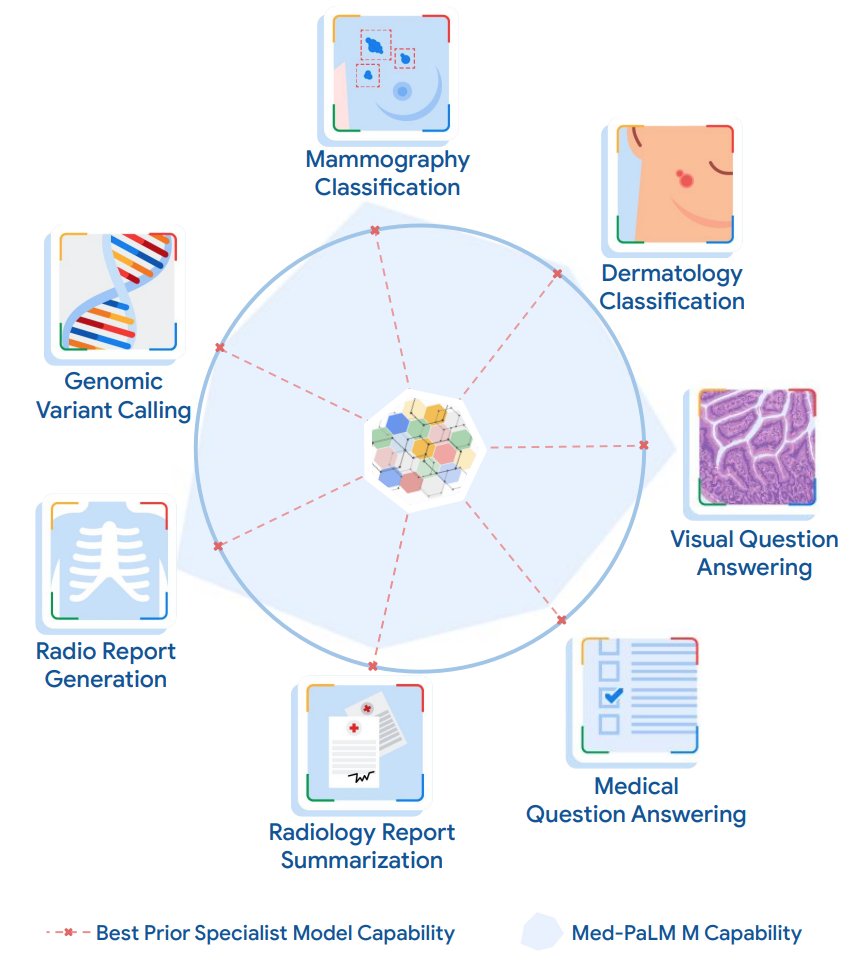
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI A key intuition for building large scale generalist biomedical AI with language as a common grounding across tasks is the possibility of combinatorial generalization and positive task transfer.
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI Towards that, we find preliminary but exciting evidence that Med-PaLM M can generalize to novel medical tasks and concepts and perform zero-shot multimodal reasoning - all in a zero-shot fashion only through language based instructions and prompts.
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI For eg, we find that Med-PaLM M can accurately identify and describe TB in chest x-rays despite having never encountered presentations of the disease before in images - only through language based instructions and prompts.
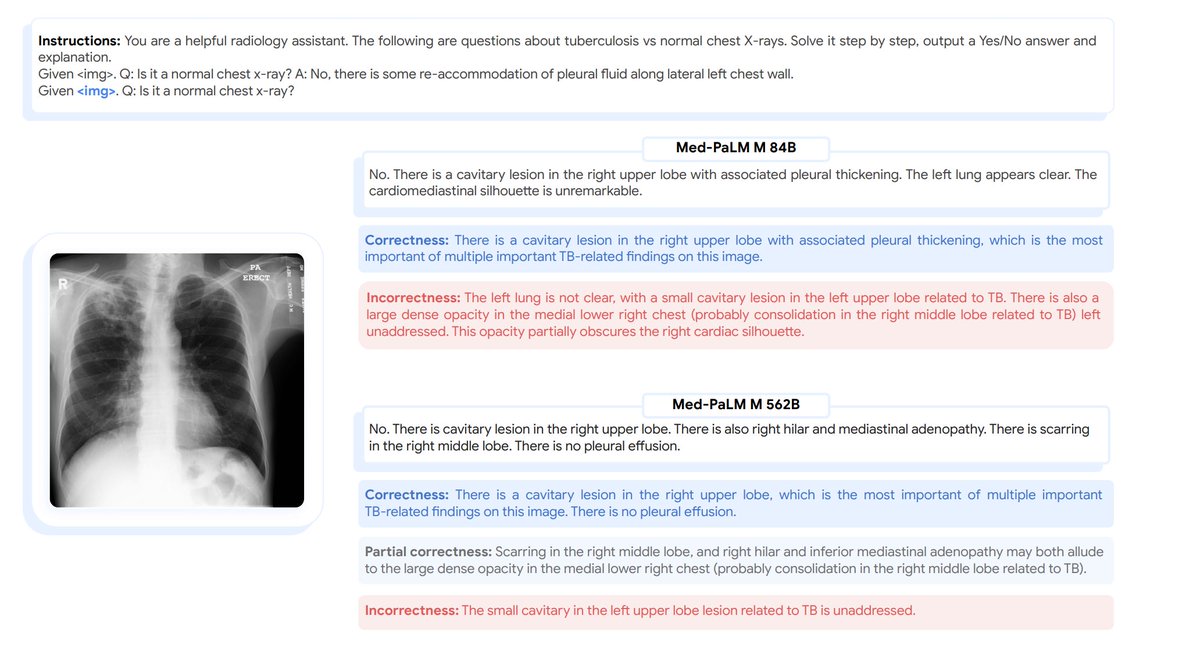
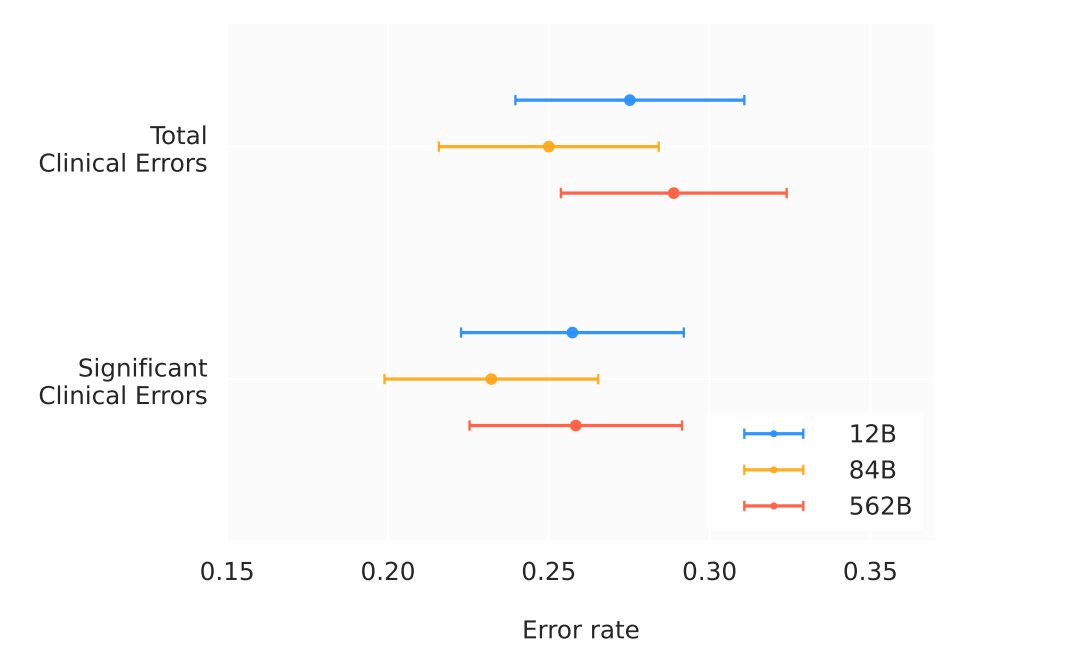
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI Finally, to understand the clinical applicability of Med-PaLM M, we conducted a radiologist evaluation of AI generated reports across model scales.
Clinically significant error rate for Med-PaLM M on par with radiologists from prior studies suggesting potential clinical utility.
Clinically significant error rate for Med-PaLM M on par with radiologists from prior studies suggesting potential clinical utility.
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI Our paper has more experiments, details and insights.
Would love your feedback -
Zooming out, generalist biomedical AI is a dream many of us at @GoogleAI @GoogleHealth @GoogleDeepMind have been building towards for years.arxiv.org/pdf/2307.14334…
Would love your feedback -
Zooming out, generalist biomedical AI is a dream many of us at @GoogleAI @GoogleHealth @GoogleDeepMind have been building towards for years.arxiv.org/pdf/2307.14334…
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI @GoogleHealth @GoogleDeepMind The possibilities with such generalist biomedical AI that can encode the biomedical universe is limitless with applications spanning the continuum of scientific biomedical discovery to care delivery.
The future of AI in medicine and bio is incredibly exciting!
The future of AI in medicine and bio is incredibly exciting!
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI @GoogleHealth @GoogleDeepMind Huge props to @taotu831 for driving this work with relentless energy and optimism together with stellar teammates @AziziShekoofeh @DannyDriess @HardyShakerman @peteflorence @thekaransinghal @alan_karthi @pichuan across @GoogleAI @GoogleDeepMind @GoogleHealth (1/2)
@taotu831 @AziziShekoofeh @HardyShakerman @peteflorence @DannyDriess @thekaransinghal @alan_karthi @GoogleAI @GoogleHealth @GoogleDeepMind @pichuan Mohamed Amin, Sara Mahdavi, Chris Semturs, Joelle Barral, @skornblith @acarroll_ATG @_basilM @RyutaroTanno @achowdhery @greg_corrado @ymatias and many more we have the privilege of working with (2/2)
• • •
Missing some Tweet in this thread? You can try to
force a refresh