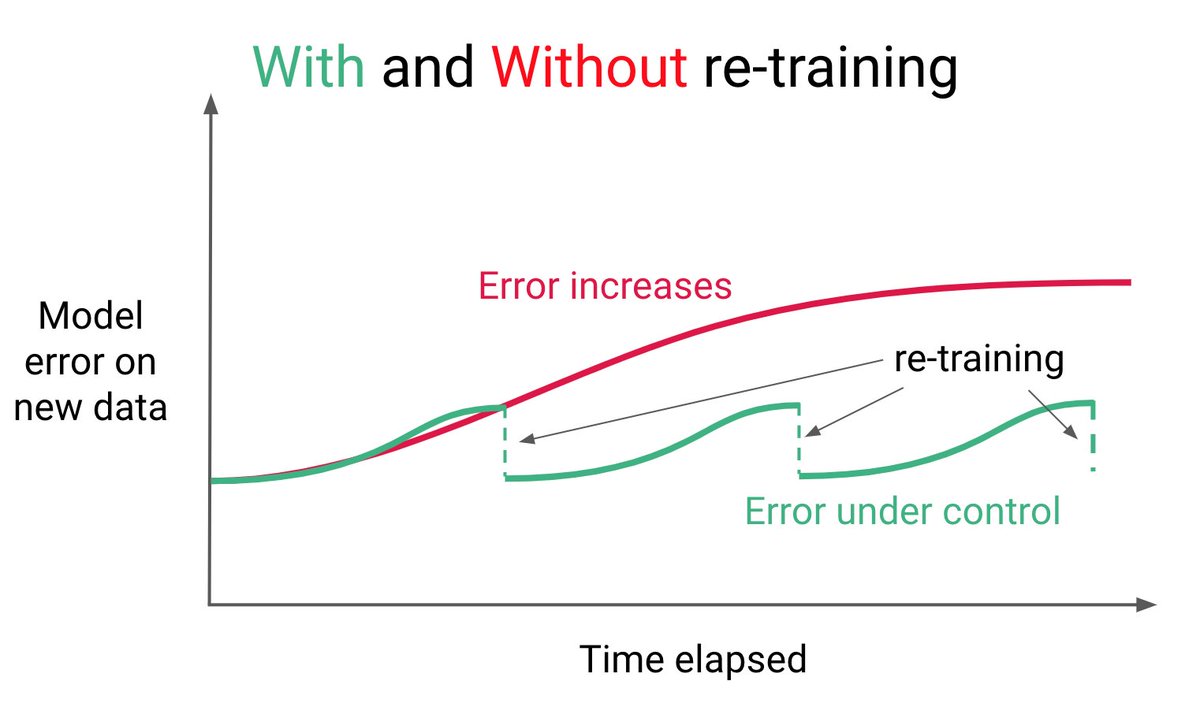
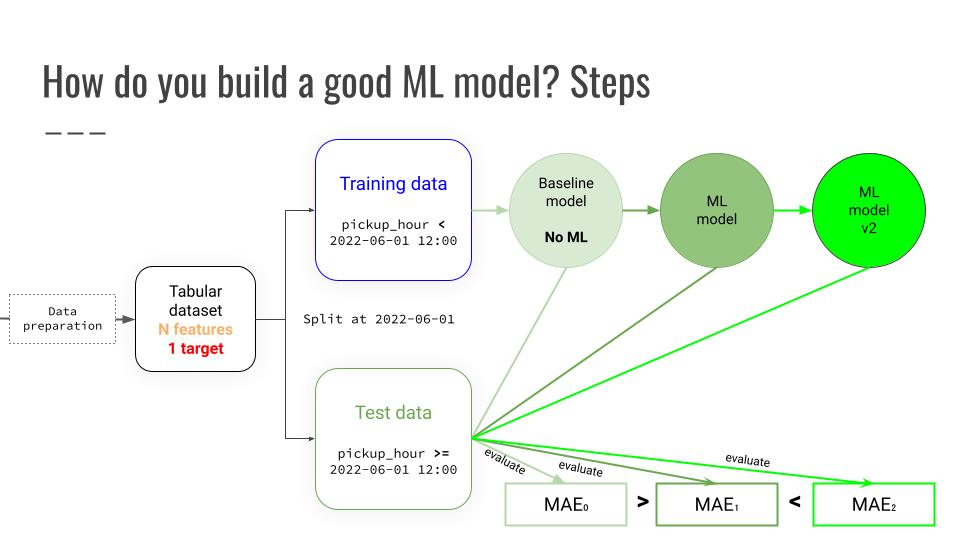
3 years ago I struggled to land my first freelance ML engineering contract.
Then I discovered this ↓
Then I discovered this ↓
Building one professional real-world ML project is the best way to stand out from the crowd, and land an ML job.
Here is what I did, 𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽 👩💻👨🏽💻↓
Here is what I did, 𝘀𝘁𝗲𝗽-𝗯𝘆-𝘀𝘁𝗲𝗽 👩💻👨🏽💻↓
Step 1. Find a real-world problem you are interested in
Working on projects is harder than completing online courses.
But hey, no pain no gain.
It is VERY important you work on a problem you are interested in.
Otherwise, you will quit.
Working on projects is harder than completing online courses.
But hey, no pain no gain.
It is VERY important you work on a problem you are interested in.
Otherwise, you will quit.
Step 2. Find a data source
Preferably a live API. If not possible, pick a static dataset from Kaggle.
Here is a superb repo with a list of public APIs you can use
github.com/public-apis/pu…
Preferably a live API. If not possible, pick a static dataset from Kaggle.
Here is a superb repo with a list of public APIs you can use
github.com/public-apis/pu…
Step 3. Build a simple ML model
Do not try to build THE PERFECT model, and only then move to the next phase.
Because this leads you to a never-ending Jupyter-notebook-development-cycle, and you get lost.
Start with basic features and a basic model.
And move to the next step.
Do not try to build THE PERFECT model, and only then move to the next phase.
Because this leads you to a never-ending Jupyter-notebook-development-cycle, and you get lost.
Start with basic features and a basic model.
And move to the next step.
Step 4. Build a Minimum Viable Product
A Jupyter notebook is not enough to prove your solution might work.
You need to go one step further and build a minimal working system.
I recommend you follow the 3-pipeline design ↓
datamachines.xyz/2023/03/27/rea…
A Jupyter notebook is not enough to prove your solution might work.
You need to go one step further and build a minimal working system.
I recommend you follow the 3-pipeline design ↓
datamachines.xyz/2023/03/27/rea…
Step 5. Start iterating on the model
Once the system works, start improving it by
- increasing training data size
- increasing the number of features
- trying a more complex ML model
- optimizing model hyper-parameters
Once the system works, start improving it by
- increasing training data size
- increasing the number of features
- trying a more complex ML model
- optimizing model hyper-parameters
Step 6. Push your code to a public GitHub repo and write a beautiful README
The README file is the first thing your future employer will se.
Explain the problem you wanted to solve, and the solution you built.
Here is an example
github.com/Paulescu/bytew…
The README file is the first thing your future employer will se.
Explain the problem you wanted to solve, and the solution you built.
Here is an example
github.com/Paulescu/bytew…
Ready to take your ML career to the next level?
Join the Real-World ML Tutorial + Community and build a complete ML app, from A to Z.
Because THIS IS what companies look for.
Use the discount code "NINJA" to get a 20% discount and LIFETIME access
realworldmachinelearning.carrd.co
Join the Real-World ML Tutorial + Community and build a complete ML app, from A to Z.
Because THIS IS what companies look for.
Use the discount code "NINJA" to get a 20% discount and LIFETIME access
realworldmachinelearning.carrd.co
Do you like tweets like this?
→ Follow me @paulabartabajo_ so you do not miss what's coming next.
Wanna help?
→ Like/Retweet the first tweet below to spread the wisdom ↓↓↓
→ Follow me @paulabartabajo_ so you do not miss what's coming next.
Wanna help?
→ Like/Retweet the first tweet below to spread the wisdom ↓↓↓
https://twitter.com/1408789941040058369/status/1686649366793109504
Wanna level up in ML/MLOps?
Join my e-mail list and get one article 𝗘𝘃𝗲𝗿𝘆 𝗦𝗮𝘁𝘂𝗿𝗱𝗮𝘆 𝗺𝗼𝗿𝗻𝗶𝗻𝗴 ↓
datamachines.xyz/subscribe/
Join my e-mail list and get one article 𝗘𝘃𝗲𝗿𝘆 𝗦𝗮𝘁𝘂𝗿𝗱𝗮𝘆 𝗺𝗼𝗿𝗻𝗶𝗻𝗴 ↓
datamachines.xyz/subscribe/
• • •
Missing some Tweet in this thread? You can try to
force a refresh