
Code understanding 🖥️🧠
LLMs excel at code analysis / completion (e.g., Co-Pilot, Code Interpreter, etc). Part 6 of our initiative to improve @LangChainAI docs covers code analysis, building on contributions of @cristobal_dev + others:
https://t.co/2DsxdjbYeypython.langchain.com/docs/use_cases…

LLMs excel at code analysis / completion (e.g., Co-Pilot, Code Interpreter, etc). Part 6 of our initiative to improve @LangChainAI docs covers code analysis, building on contributions of @cristobal_dev + others:
https://t.co/2DsxdjbYeypython.langchain.com/docs/use_cases…

1/ Copilot and related tools (e.g., @codeiumdev) have dramatically accelerated dev productivity and shown that LLMs excel at code understanding / completion
https://twitter.com/karpathy/status/1608895189078380544?s=20
2/ But, RAG for QA/chat on codebases is challenging b/c text splitters may break up elements (e.g., fxns, classes) and fail to preserve context about which element each code chunk comes from.
https://twitter.com/cristobal_dev/status/1675745319659659270?s=20
3/ @cristobal_dev added context-aware code splitters to @LangChainAI, which preserve code structure (classes, fxns are loaded into docs) to support RAG for QA / chat: https://t.co/2AjOrjMrIu
https://twitter.com/RLanceMartin/status/1674817117475188737?s=20
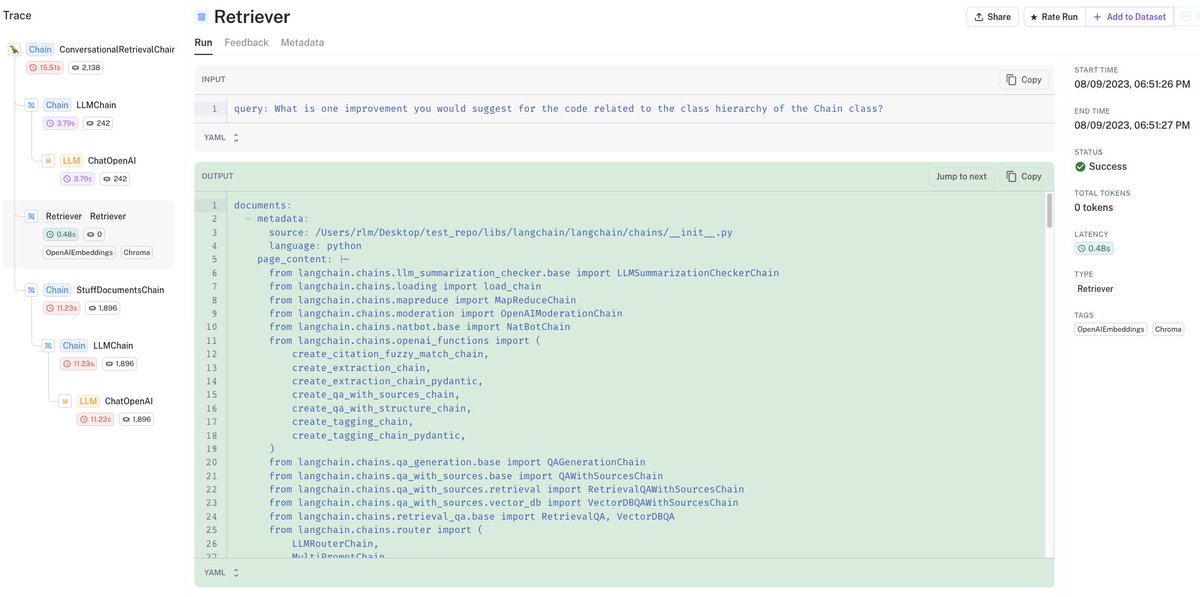
4/ Looking at LangSmith traces, we can see retrieved code from vectorDB related to the question retains fxn, cls structure and metadata (source file, etc):
https://t.co/KHszLjX05Jsmith.langchain.com/public/2b23045…
https://t.co/KHszLjX05Jsmith.langchain.com/public/2b23045…
5/ For more on the community initiative to improve the docs, see Part 5 on tool use:
https://twitter.com/RLanceMartin/status/1689675201984831491?s=20
• • •
Missing some Tweet in this thread? You can try to
force a refresh















