
Excited to share our work on SeamlessM4T. An all-in-one, Massively Multilingual and Multimodal Machine Translation model.
This 🧵 discusses some of the contributions of SeamlessM4T
This 🧵 discusses some of the contributions of SeamlessM4T

SeamlessM4T introduces multitask UnitY model, capable of translating text/speech input into text/speech output. It enables:
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- ASR
- Speech-to-speech translation (S2ST)
- Speech-to-text translation (S2TT)
- Text-to-speech translation (T2ST)
- Text-to-text translation (T2TT)
- ASR
We’re releasing two models, SeamlessM4T-Large (2,3B) and SeamlessM4T-medium (1.2B), both covering:
📥 101 languages for speech input
⌨️ 96 Languages for text input/output
🗣️ 35 languages for speech output.
📥 101 languages for speech input
⌨️ 96 Languages for text input/output
🗣️ 35 languages for speech output.
Let’s start with some results comparing SeamlessM4T to strong cascaded models for S2TT, pairing Whisper for ASR with NLLB for T2TT.
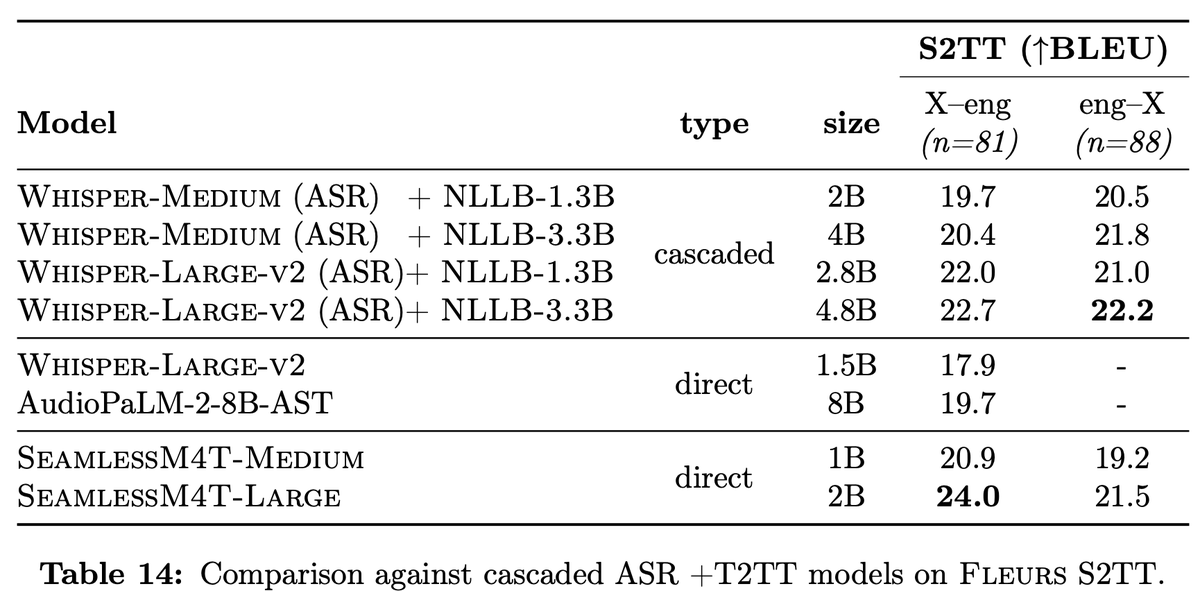
SeamlessM4T-Large outperfroms much larger models on Fleurs X-eng with +1.3 BLEU points and is on par with these models on eng-X. SeamlessM4T is actually the first direct model to support such a large number of eng-X directions
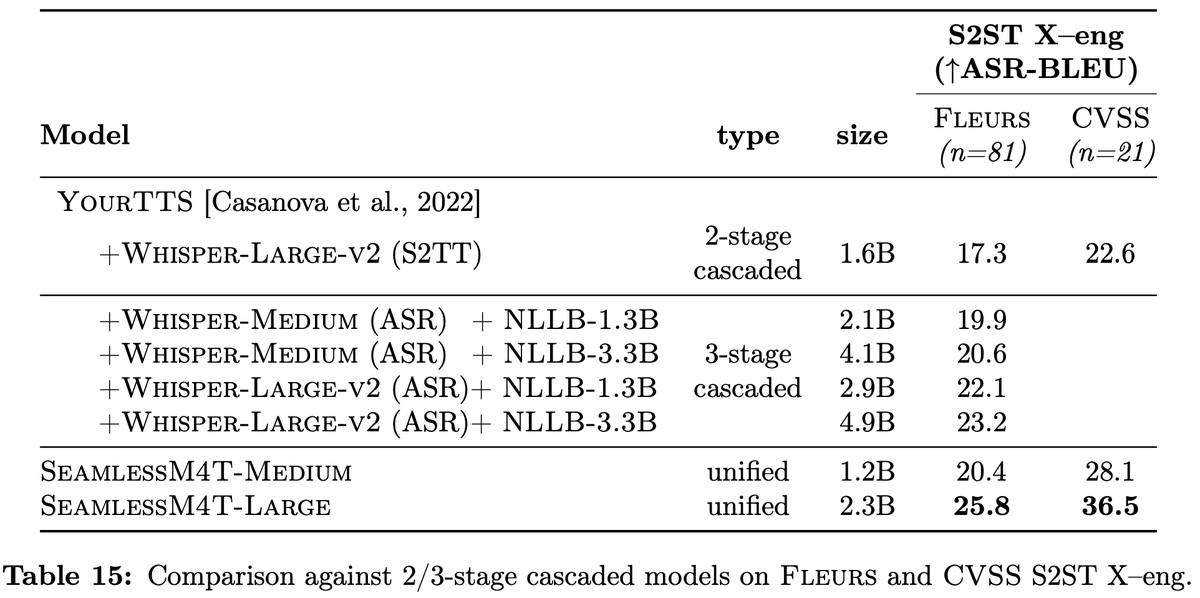
In the more challenging task of S2ST, SeamlessM4T beats cascaded baselines using yourTTS by a large margin, in both X-eng and eng-X directions from Fleurs. This is an improvement of 48% over 2-stage cascaded models in X-eng!
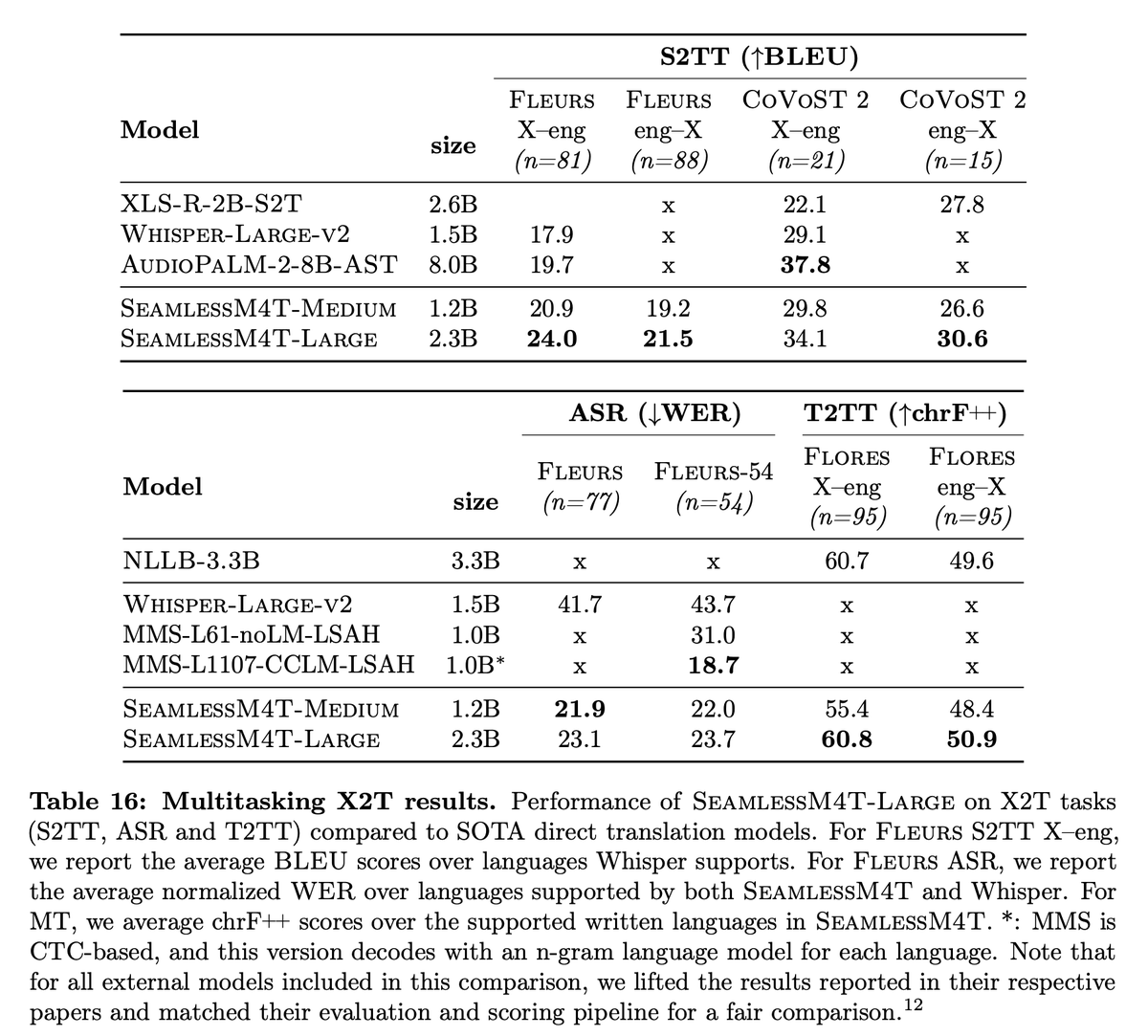
We evaluate SeamlessM4T models on S2T, S2ST, T2TT and ASR, and achieve state-of-the-art results in all of them with a single model!
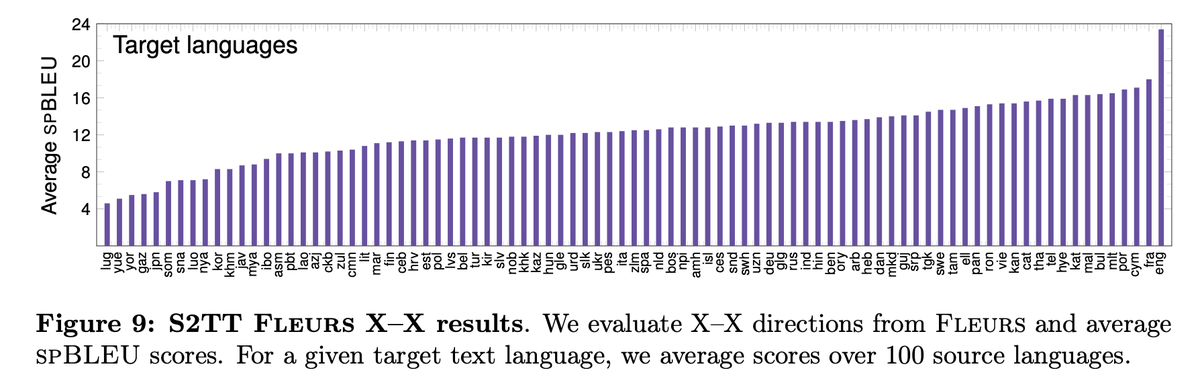
We also evaluate in zero-shot fashion, the task of text-to-speech translation (T2ST), as well as non-English centric S2T on Fleurs (more than 8000 directions).
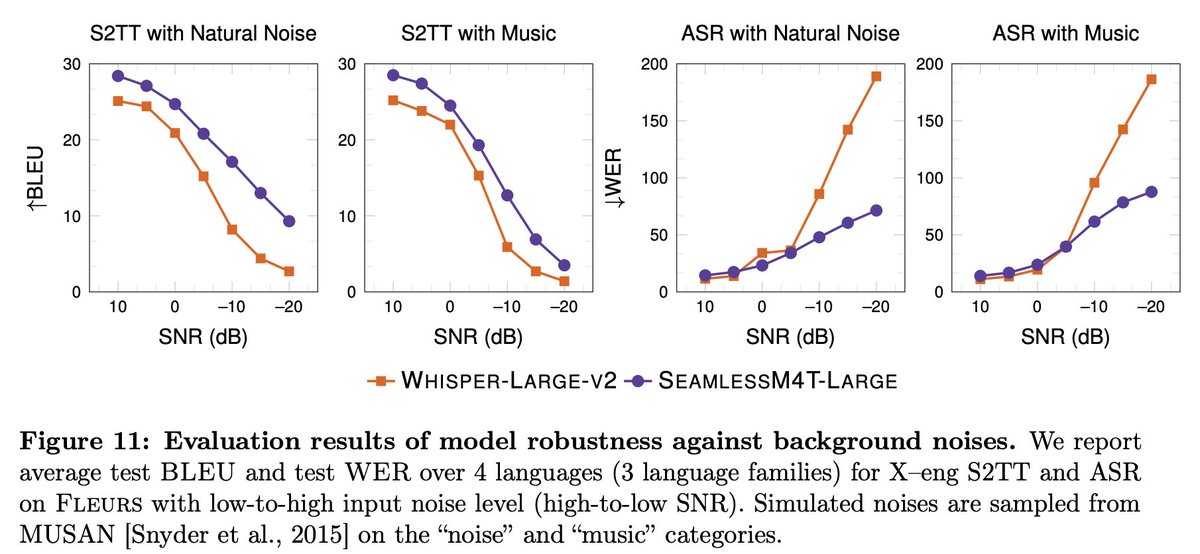
Evaluated for robustness, SeamlessM4T-Large is more robust than Whisper-Large-v2 against background noises and speaker variations with an average improvement of 38% and 49%, respectively.
Now, how does it work?
Multitask UnitY leverages pre-trained components to enable multiple input modalities, boost the translation quality and improve training stability.
These include:
(1) An NLLB model for text translation.
Multitask UnitY leverages pre-trained components to enable multiple input modalities, boost the translation quality and improve training stability.
These include:
(1) An NLLB model for text translation.
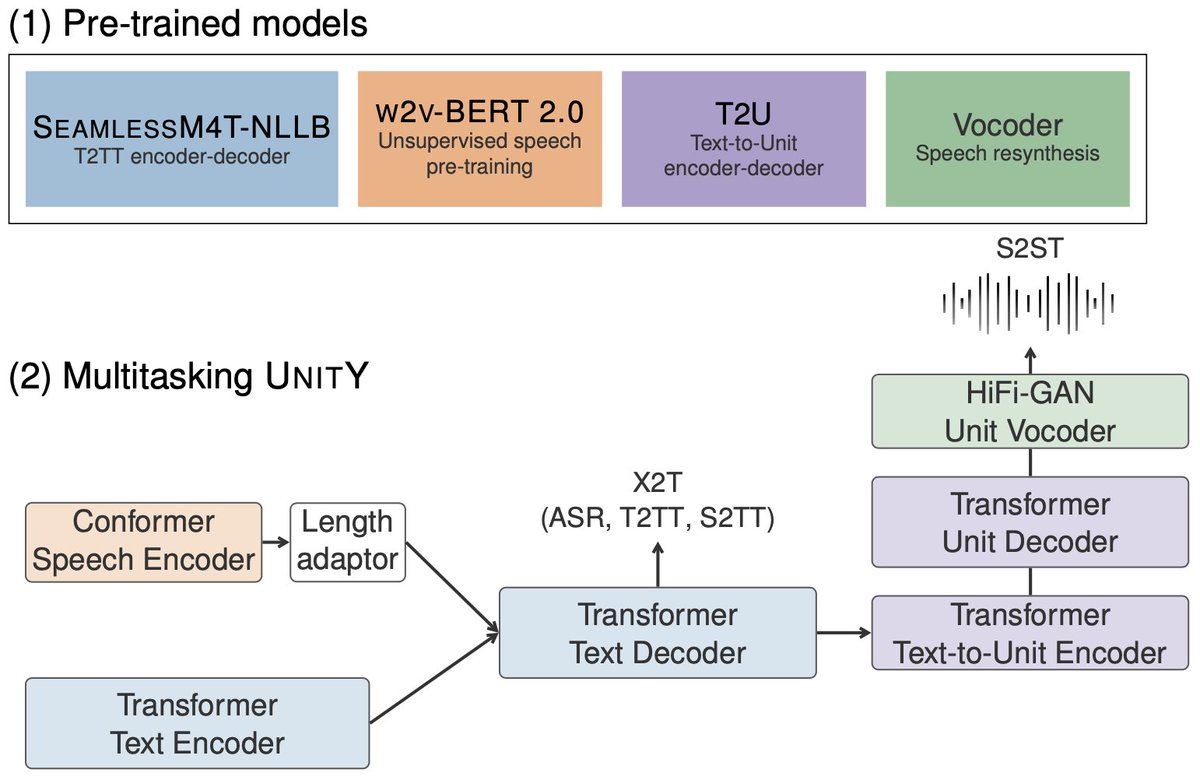
(2) An updated w2v-BERT 2.0 speech encoder trained on 1M hours of speech and covering over 143 languages.
(3) A T2U sequence-to-sequence model for converting text to units.
(4) A multilingual vocoder (HiFI-GAN) to synthesise these units.
(3) A T2U sequence-to-sequence model for converting text to units.
(4) A multilingual vocoder (HiFI-GAN) to synthesise these units.
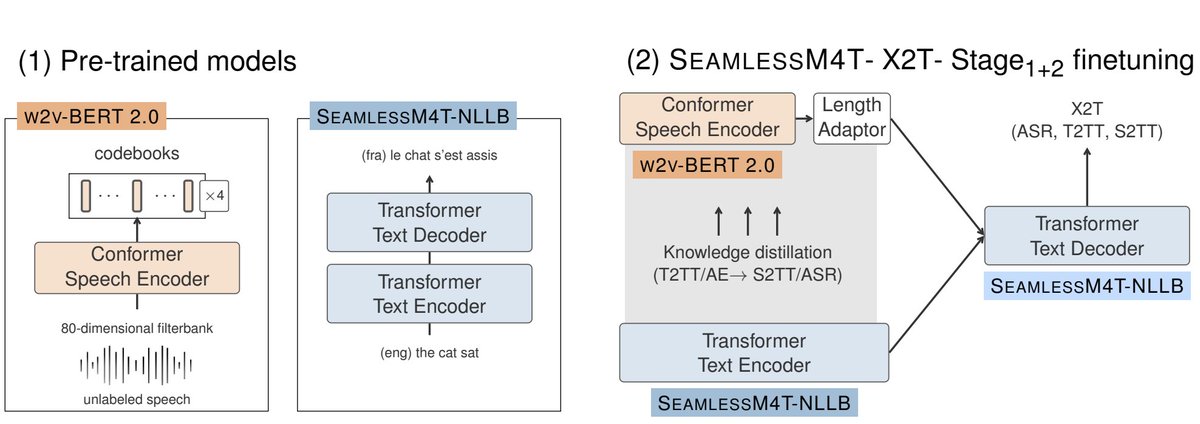
The first stage of training SeamlessM4T models start with finetuning on X2T tasks (speech-to-text and text-to-text) with token-level Knowledge distillation from the T2TT teacher model to the S2T student model.
The last stage of finetuning completes the multitask UnitY model with T2U encoder-decoder, and finetunes on paired speech input with translated units output.
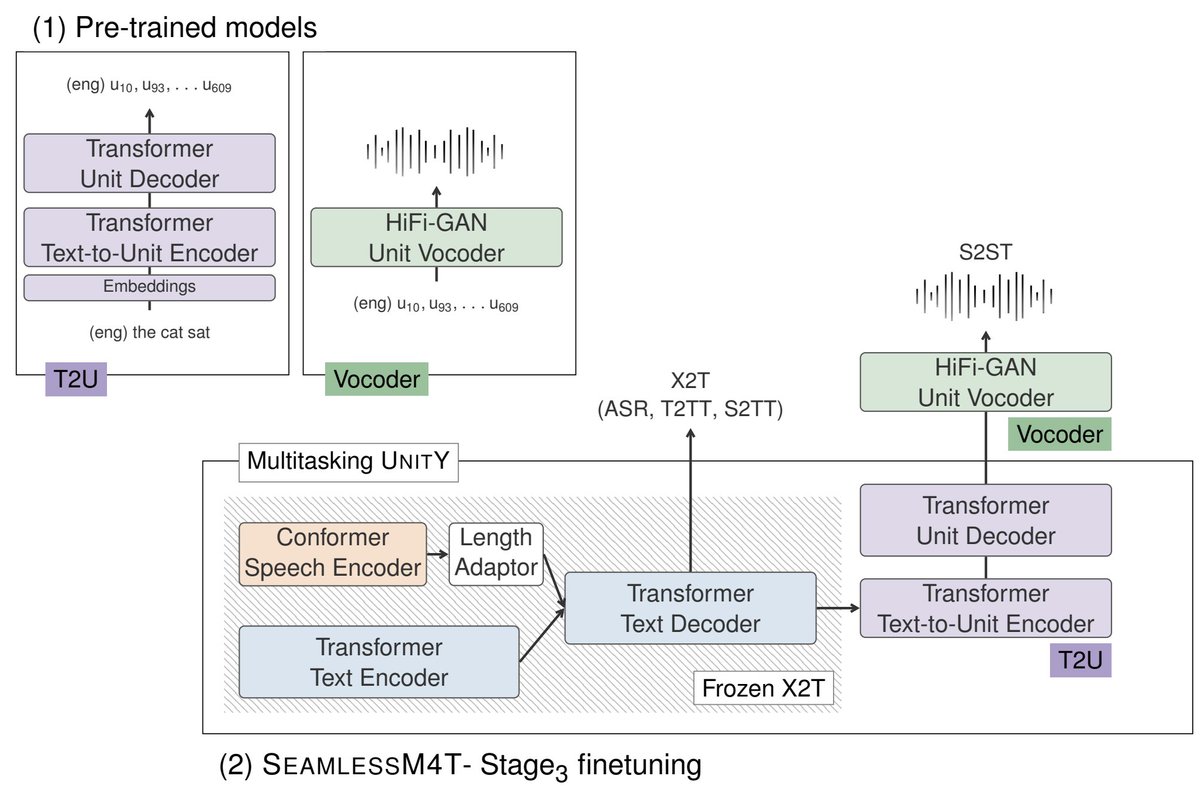
Both finetuning stages leverage portions of mined S2T and S2ST data from SeamlessAlign - our new multimodal corpus of automatically aligned speech translations of more than 470K hours. SeamlessAlign is mined with SONAR - a new multilingual and multimodal embedding space -
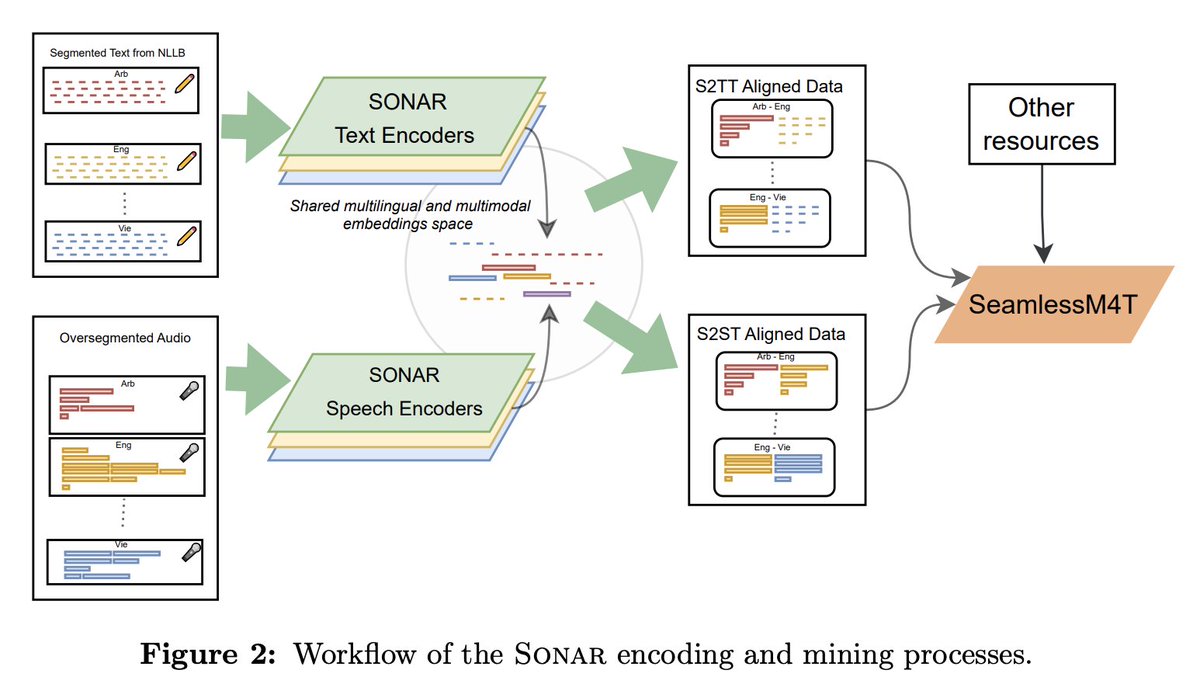
We’re open-sourcing seamlessM4T models (large and medium) and the metadata for SeamlessAlign under CC-BY-NC 4.0. We’re also releasing smaller on-device models for faster inference.
github.com/facebookresear…
github.com/facebookresear…
I’m also excited about the release of Fairseq2, our revamped sequence modeling toolkit
Among other things, It features sota implementation of Transformer modules and a scalable data pipeline API for speech and text.
github.com/facebookresear…
Among other things, It features sota implementation of Transformer modules and a scalable data pipeline API for speech and text.
github.com/facebookresear…
We extended stopes, our data preparation library to support mining speech with SONAR github.com/facebookresear…
github.com/facebookresear…
github.com/facebookresear…
We’re also releasing BLASER 2.0, our latest modality-agnostic evaluation metric for multimodal translation. It is based on SONAR and supports 83 languages. Similar to BLASER, it’s text-free when evaluating speech outputs (e.g. S2ST).
This is only a portion of SeamlessM4T; a huge effort went into evaluating our models, and this table from the paper summarizes all aspects of human and automatic evaluation
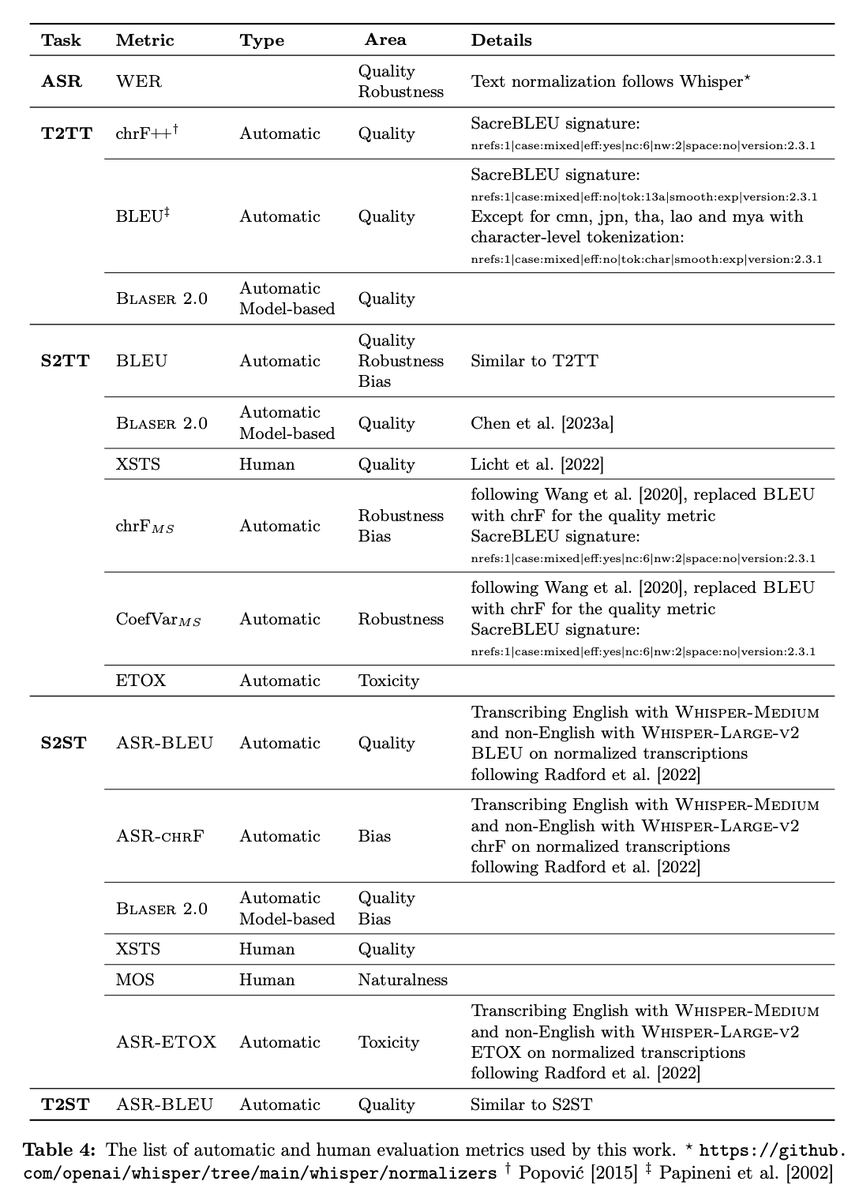
Check out the paper for more technical details
And check the blog post to try our demo
ai.meta.com/research/publi…
ai.meta.com/resources/mode…
And check the blog post to try our demo
ai.meta.com/research/publi…
ai.meta.com/resources/mode…
We also have a 🤗Hugging Face space at huggingface.co/spaces/faceboo…
This is a massive team effort @MetaAI. Thanks to my awesome collaborators @skylrwang, @costajussamarta, @SchwenkHolger, @sravyapopuri388, @ChanghanWang, @guzmanhe, @juanmiguelpino, @jffwn, and many others.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



