
Check out these new guides for 13 popular LLM use-cases. Part of a major community effort to improve the @LangChainAI docs + add CoLabs prototyping.
1/13: Open source LLMs
How to use many open source LLMs on your device
python.langchain.com/docs/guides/lo…

1/13: Open source LLMs
How to use many open source LLMs on your device
python.langchain.com/docs/guides/lo…


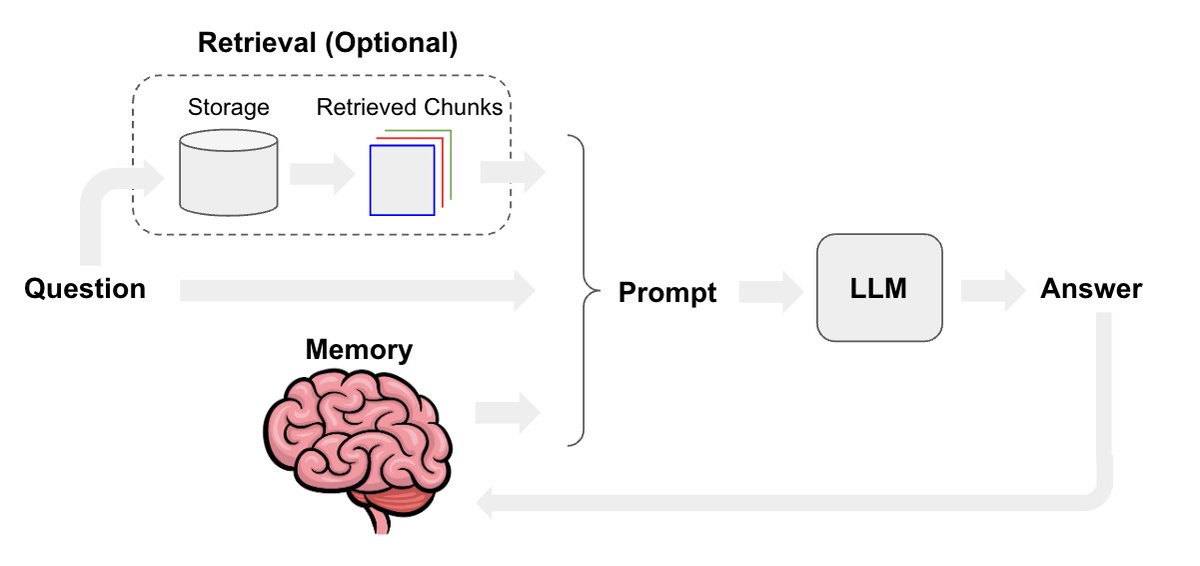
3/13: RAG (retrieval augmented generation)
How to do RAG at multiple levels of abstraction
python.langchain.com/docs/use_cases…
How to do RAG at multiple levels of abstraction
python.langchain.com/docs/use_cases…

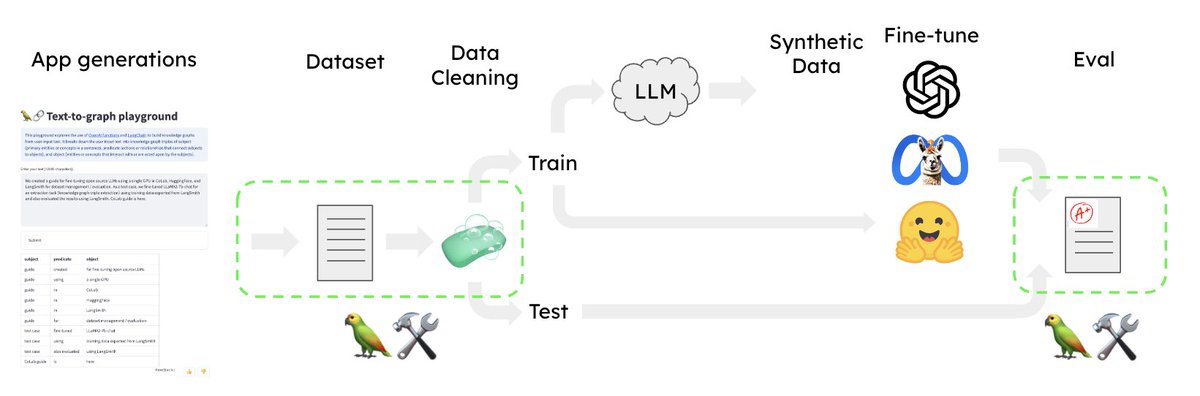
5/13: Private RAG
How to do RAG w/ local LLM/embeddings/vectorstore
python.langchain.com/docs/use_cases…
How to do RAG w/ local LLM/embeddings/vectorstore
python.langchain.com/docs/use_cases…
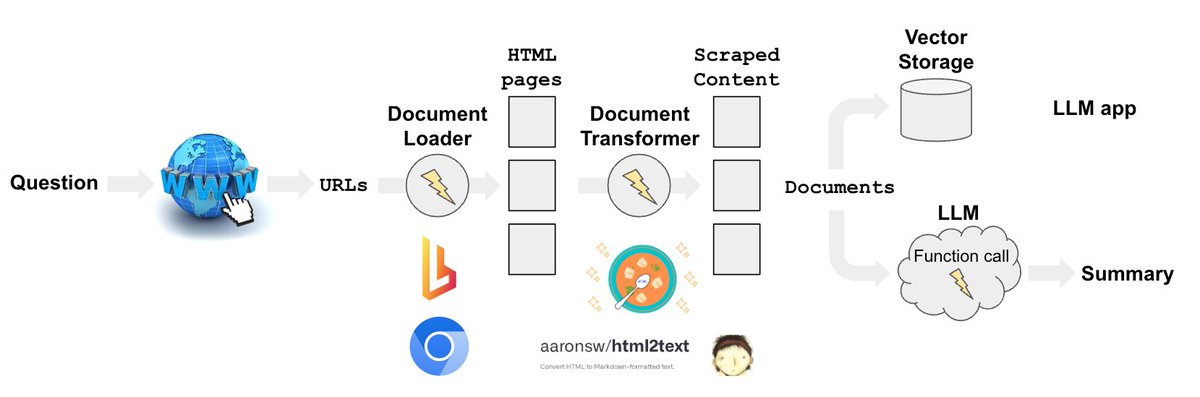
7/13: Summarization
How to summarize small or large docs w/ LLMs
python.langchain.com/docs/use_cases…
How to summarize small or large docs w/ LLMs
python.langchain.com/docs/use_cases…
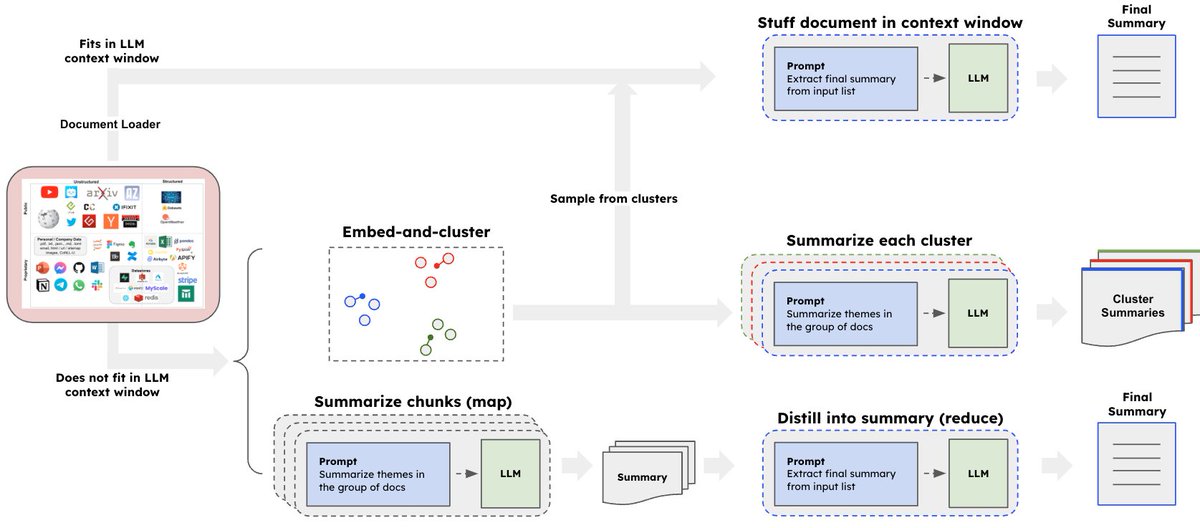
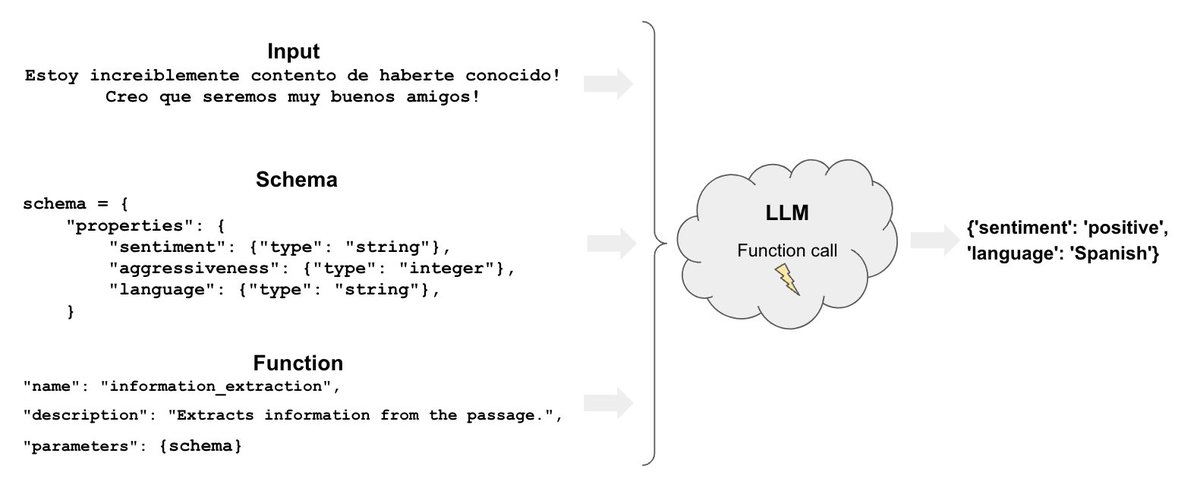
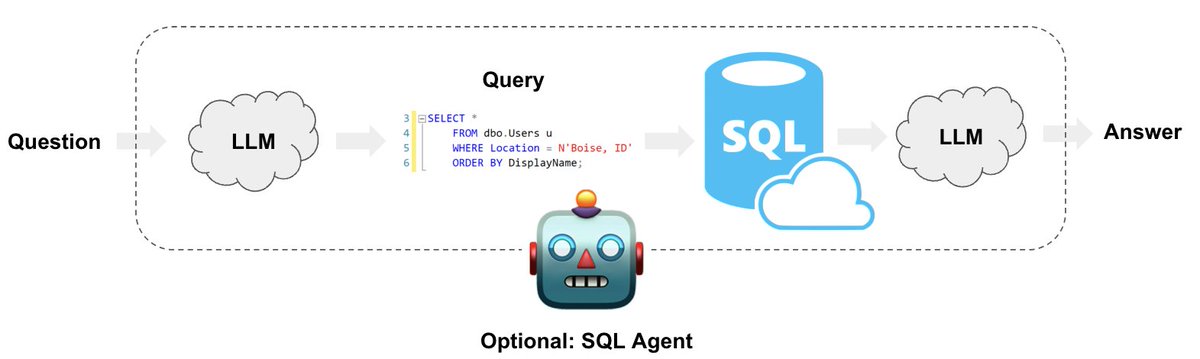
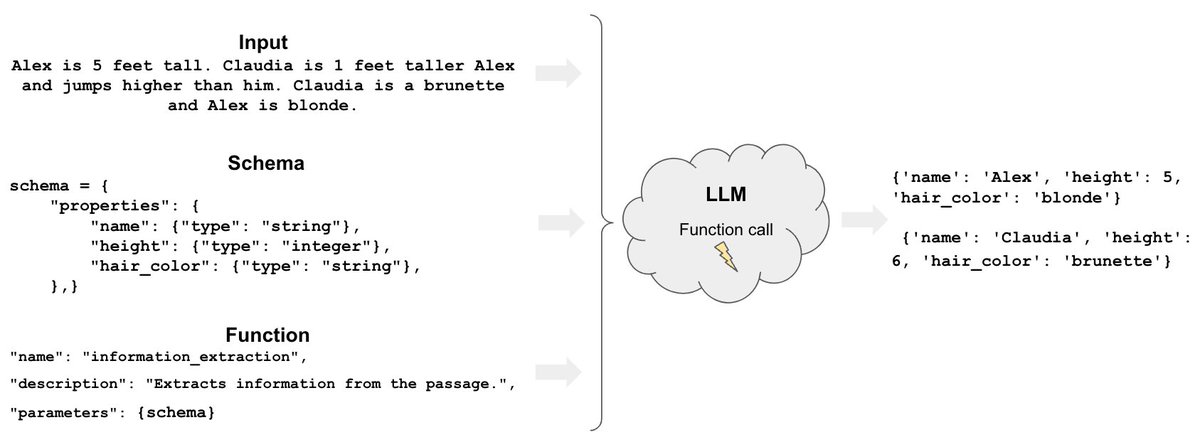
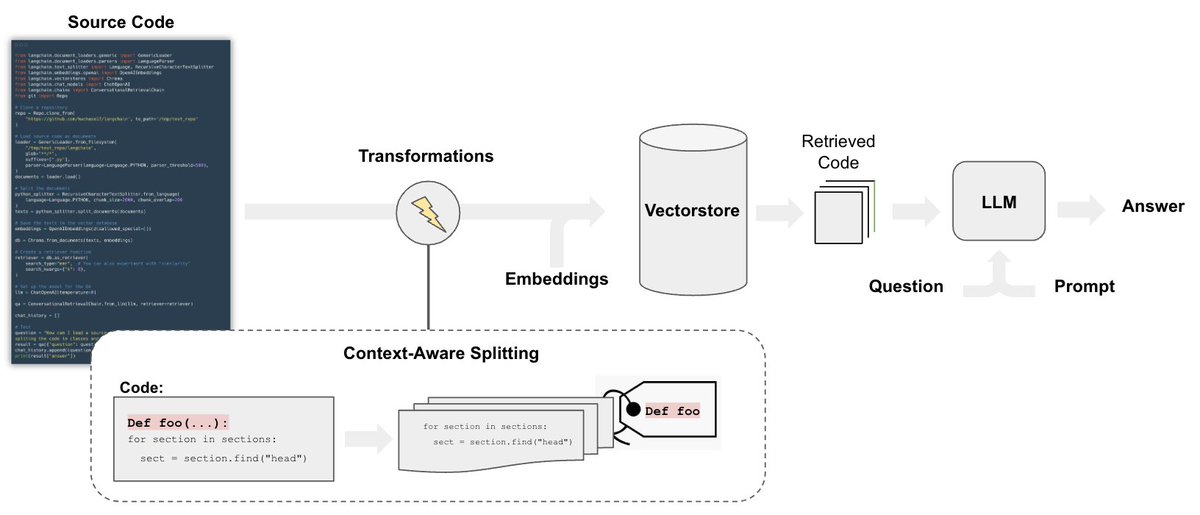
11/13: Code understanding
How to perform QA on code bases w/ LLMs
python.langchain.com/docs/use_cases…
How to perform QA on code bases w/ LLMs
python.langchain.com/docs/use_cases…

All include LangSmith traces to visualize what is going on under the hood (chain information flow + prompts) + most include CoLab notebooks for prototyping.
• • •
Missing some Tweet in this thread? You can try to
force a refresh














