
LLMs and Their Human-like Reasoning Capabilities - Fact or Fiction?
Research into enabling Large Language Models (LLMs) to display human-like reasoning has been a hot topic. However, some others have argued that LLMs aren't capable of reasoning given that are glorified next-word predictors.
Here is where we are today -
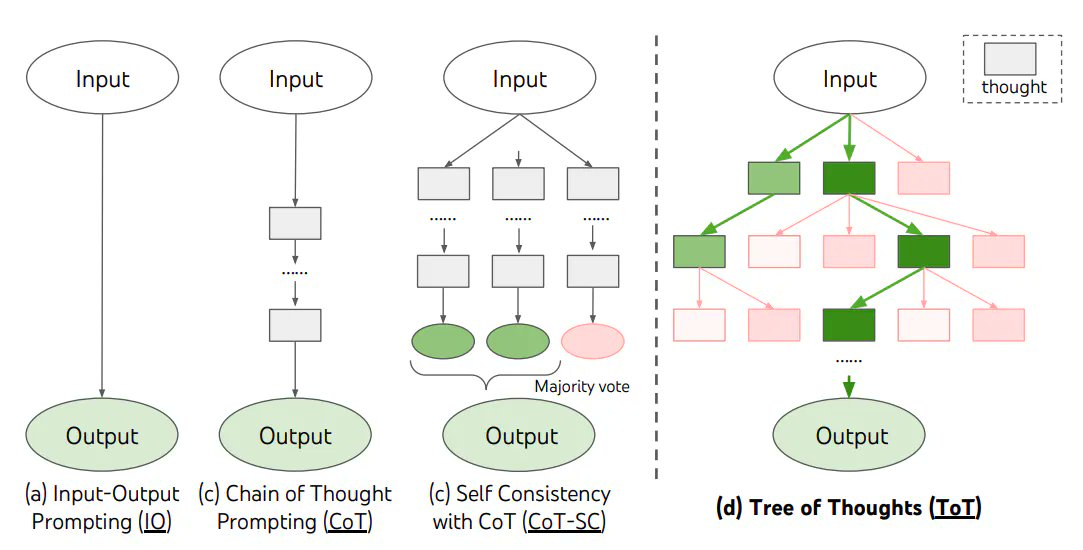
Chain of thought (CoT) reasoning - Prompting a "chain of thought"—a series of intermediate reasoning steps—can significantly improve the performance of LLMs in complex reasoning tasks.
The human brain typically decomposes a math problem into intermediate steps and solves each step before giving the final answer: “After Jane gives 2 flowers to her mom she has 10 . . . then after she gives 3 to her dad she will have 7 . . . so the answer is 7.”
The basic idea behind CoT is to prompt the model with some examples of these types of problems and the step-by-step reasoning involved in solving them. By prompting in this way, the model can decompose the problem similar to the human brain and solve for it.
LLMs when prompted with just eight chain-of-thought examples, achieved state-of-the-art accuracy surpassing even fine-tuned versions of GPT-3
CoT prompting helps in improving airthmetic, commonsense, symbolic and multi-step reasoning capabilities of the LLM
That said, the CoT prompting is fairly limited. It depends a lot on the quality of the prompt and the model doesn't have memory and the prompt size is limited by the model's context length.
Recently researchers at DeepMind released a paper that outlines the Tree of Thoughts (ToT) framework. It addresses the shortcomings of existing approaches that do not explore different continuations within a thought process or incorporate any type of planning, lookahead, or backtracking to evaluate different options.
ToT frames any problem as a search over a tree, where each node represents a partial solution with the input and the sequence of thoughts so far. It allows LMs to explore multiple reasoning paths over thoughts, each thought being a coherent language sequence that serves as an intermediate step toward problem solving.
The ToT process involves four key steps:
- Decomposing the intermediate process into thought steps.
- Generating potential thoughts from each state.
- Heuristically evaluating states.
- Deciding what search algorithm to use.
The ToT framework allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action. It also enables looking ahead or backtracking when necessary to make global choices.
The framework is versatile and can handle challenging tasks. It also improves the interpretability of model decisions and the opportunity for human alignment, as the resulting representations are readable, high-level language reasoning instead of implicit, low-level token values.
In practice, the ToT framework has significantly enhanced language models' problem-solving abilities on tasks requiring non-trivial planning or search.
In the Game of 24, while a model with chain-of-thought prompting only solved 4% of tasks, the ToT method achieved a success rate of 74%.
ToT is a prompting framework has well and has the same fundamental limitations as the CoT framework. ToT needs careful thought decomposition and generation, and relies on heuristics for evaluating states and deciding on the search algorithm.
However it's important to remember that while LLMs can mimic certain types of reasoning to a certain extent, but it's not the same as human reasoning.
They don't have the ability to understand, self-correct, or make judgments based on a deep understanding of the world. They're more like really good actors who can deliver their lines convincingly but don't actually understand the plot of the play.
In summary, AI is still extremely early when it comes to reasoning and we may need a another significant breakthrough before LLMs can really measure up to humans.

Research into enabling Large Language Models (LLMs) to display human-like reasoning has been a hot topic. However, some others have argued that LLMs aren't capable of reasoning given that are glorified next-word predictors.
Here is where we are today -
Chain of thought (CoT) reasoning - Prompting a "chain of thought"—a series of intermediate reasoning steps—can significantly improve the performance of LLMs in complex reasoning tasks.
The human brain typically decomposes a math problem into intermediate steps and solves each step before giving the final answer: “After Jane gives 2 flowers to her mom she has 10 . . . then after she gives 3 to her dad she will have 7 . . . so the answer is 7.”
The basic idea behind CoT is to prompt the model with some examples of these types of problems and the step-by-step reasoning involved in solving them. By prompting in this way, the model can decompose the problem similar to the human brain and solve for it.
LLMs when prompted with just eight chain-of-thought examples, achieved state-of-the-art accuracy surpassing even fine-tuned versions of GPT-3
CoT prompting helps in improving airthmetic, commonsense, symbolic and multi-step reasoning capabilities of the LLM
That said, the CoT prompting is fairly limited. It depends a lot on the quality of the prompt and the model doesn't have memory and the prompt size is limited by the model's context length.
Recently researchers at DeepMind released a paper that outlines the Tree of Thoughts (ToT) framework. It addresses the shortcomings of existing approaches that do not explore different continuations within a thought process or incorporate any type of planning, lookahead, or backtracking to evaluate different options.
ToT frames any problem as a search over a tree, where each node represents a partial solution with the input and the sequence of thoughts so far. It allows LMs to explore multiple reasoning paths over thoughts, each thought being a coherent language sequence that serves as an intermediate step toward problem solving.
The ToT process involves four key steps:
- Decomposing the intermediate process into thought steps.
- Generating potential thoughts from each state.
- Heuristically evaluating states.
- Deciding what search algorithm to use.
The ToT framework allows LMs to perform deliberate decision making by considering multiple different reasoning paths and self-evaluating choices to decide the next course of action. It also enables looking ahead or backtracking when necessary to make global choices.
The framework is versatile and can handle challenging tasks. It also improves the interpretability of model decisions and the opportunity for human alignment, as the resulting representations are readable, high-level language reasoning instead of implicit, low-level token values.
In practice, the ToT framework has significantly enhanced language models' problem-solving abilities on tasks requiring non-trivial planning or search.
In the Game of 24, while a model with chain-of-thought prompting only solved 4% of tasks, the ToT method achieved a success rate of 74%.
ToT is a prompting framework has well and has the same fundamental limitations as the CoT framework. ToT needs careful thought decomposition and generation, and relies on heuristics for evaluating states and deciding on the search algorithm.
However it's important to remember that while LLMs can mimic certain types of reasoning to a certain extent, but it's not the same as human reasoning.
They don't have the ability to understand, self-correct, or make judgments based on a deep understanding of the world. They're more like really good actors who can deliver their lines convincingly but don't actually understand the plot of the play.
In summary, AI is still extremely early when it comes to reasoning and we may need a another significant breakthrough before LLMs can really measure up to humans.
• • •
Missing some Tweet in this thread? You can try to
force a refresh



