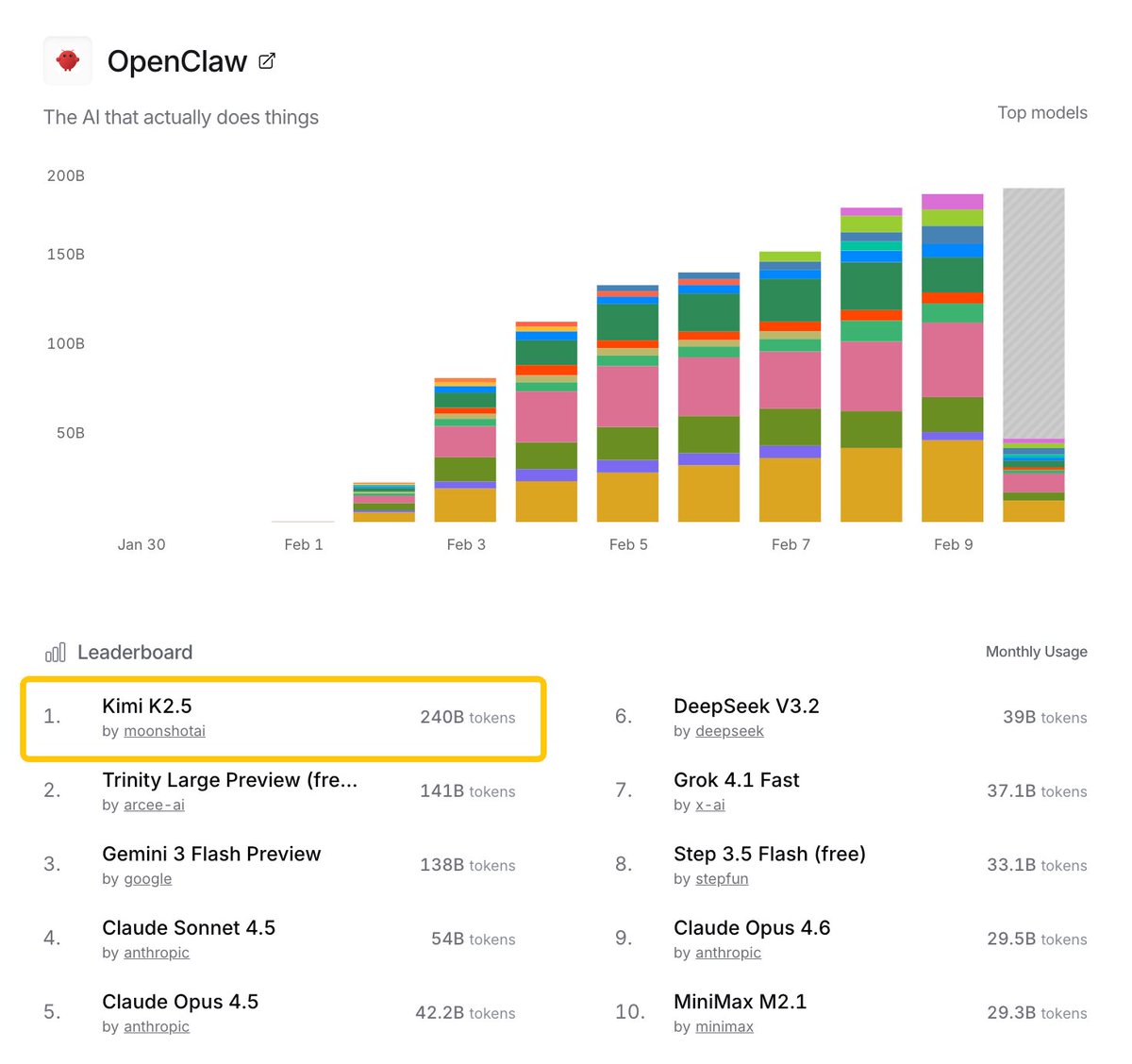
Remote work is the future.
Struggling to find remote jobs online?
Here are 20 sites to get a remote/freelance job that pays in USD:
Struggling to find remote jobs online?
Here are 20 sites to get a remote/freelance job that pays in USD:
1. Remotely / @try_remotely
Reach thousands of remote jobs on the fastest-growing remote job board.
Discover fully and partially remote jobs from the greatest remote working companies.
tryremotely.com
Reach thousands of remote jobs on the fastest-growing remote job board.
Discover fully and partially remote jobs from the greatest remote working companies.
tryremotely.com
2. JustRemote
On this site you can find a remote job that fits you.
Discover fully and partially remote jobs from the greatest remote working companies.
Check out 👇
justremote.co
On this site you can find a remote job that fits you.
Discover fully and partially remote jobs from the greatest remote working companies.
Check out 👇
justremote.co
3. Wellfound by Anglelist
On Wellfound , you can find unique jobs at startups and tech companies you can't find anywhere else.
Say goodbye to cover letters - your profile is all you need.
One click to apply and you're done.
Check out 👇
angel.co
On Wellfound , you can find unique jobs at startups and tech companies you can't find anywhere else.
Say goodbye to cover letters - your profile is all you need.
One click to apply and you're done.
Check out 👇
angel.co
4. Working Nomads
Remote jobs platform specially for Digital Nomads.
Work remotely from any places around the world.
Check out 👇
workingnomads.com/jobs
Remote jobs platform specially for Digital Nomads.
Work remotely from any places around the world.
Check out 👇
workingnomads.com/jobs
5. oDesk work
Use oDesk work to find any remote work with ease.
Find perfect freelancing/remote projects related to your expertise.
Check out 👇
odeskwork.com
Use oDesk work to find any remote work with ease.
Find perfect freelancing/remote projects related to your expertise.
Check out 👇
odeskwork.com
6. Job Board Search
On this platform you will find hand curated list of best remote job related to 200+ different categories.
Sign up and get hired.
Check out 👇
jobboardsearch.com
On this platform you will find hand curated list of best remote job related to 200+ different categories.
Sign up and get hired.
Check out 👇
jobboardsearch.com
7. JS Remotely
Best website to find Remote JavaScript Jobs.
More than 200+ new jobs daily on this platform related to JavaScript.
Check out 👇
jsremotely.com
Best website to find Remote JavaScript Jobs.
More than 200+ new jobs daily on this platform related to JavaScript.
Check out 👇
jsremotely.com
8. Remote .co
A super easy search for job seekers to find jobs.
Find jobs specific to your country area with ease.
Check out 👇
remote.co
A super easy search for job seekers to find jobs.
Find jobs specific to your country area with ease.
Check out 👇
remote.co
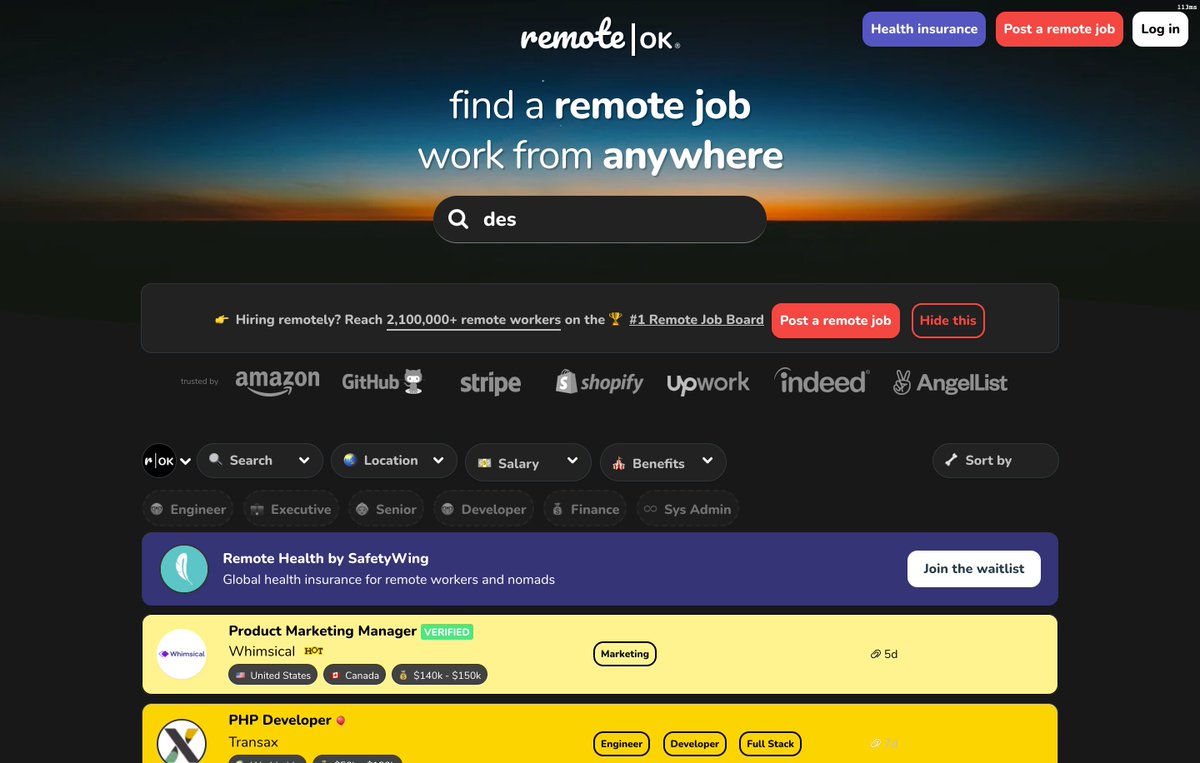
9. Remote OK
Find remote jobs with ease.
Remote OK has a system that makes finding jobs or job opportunities super easy.
Check out 👇
remoteok.com

Find remote jobs with ease.
Remote OK has a system that makes finding jobs or job opportunities super easy.
Check out 👇
remoteok.com
10. Himalayas
The remote job board you'll actually enjoy even while surfing.
You can find a remote job you love from 100+ categories and get hire.
Check out 👇
himalayas.app
The remote job board you'll actually enjoy even while surfing.
You can find a remote job you love from 100+ categories and get hire.
Check out 👇
himalayas.app
11. We Work Remotely
We Work Remotely is the largest remote work community in the world.
This is the number one destination to find and list incredible remote jobs.
Check out 👇
weworkremotely.com
We Work Remotely is the largest remote work community in the world.
This is the number one destination to find and list incredible remote jobs.
Check out 👇
weworkremotely.com
12. Flex Jobs
The #1 job site to find top notch remote work and flexible job opportunities from world wide.
Sign up and find a job.
Check out 👇
flexjobs.com
The #1 job site to find top notch remote work and flexible job opportunities from world wide.
Sign up and find a job.
Check out 👇
flexjobs.com

13. Fiverr
Fiverr is the free platform for all.
Start earning from your first day by signing up and creating your gig.
Best for freelancers.
Check out 👇
fiverr.com
Fiverr is the free platform for all.
Start earning from your first day by signing up and creating your gig.
Best for freelancers.
Check out 👇
fiverr.com

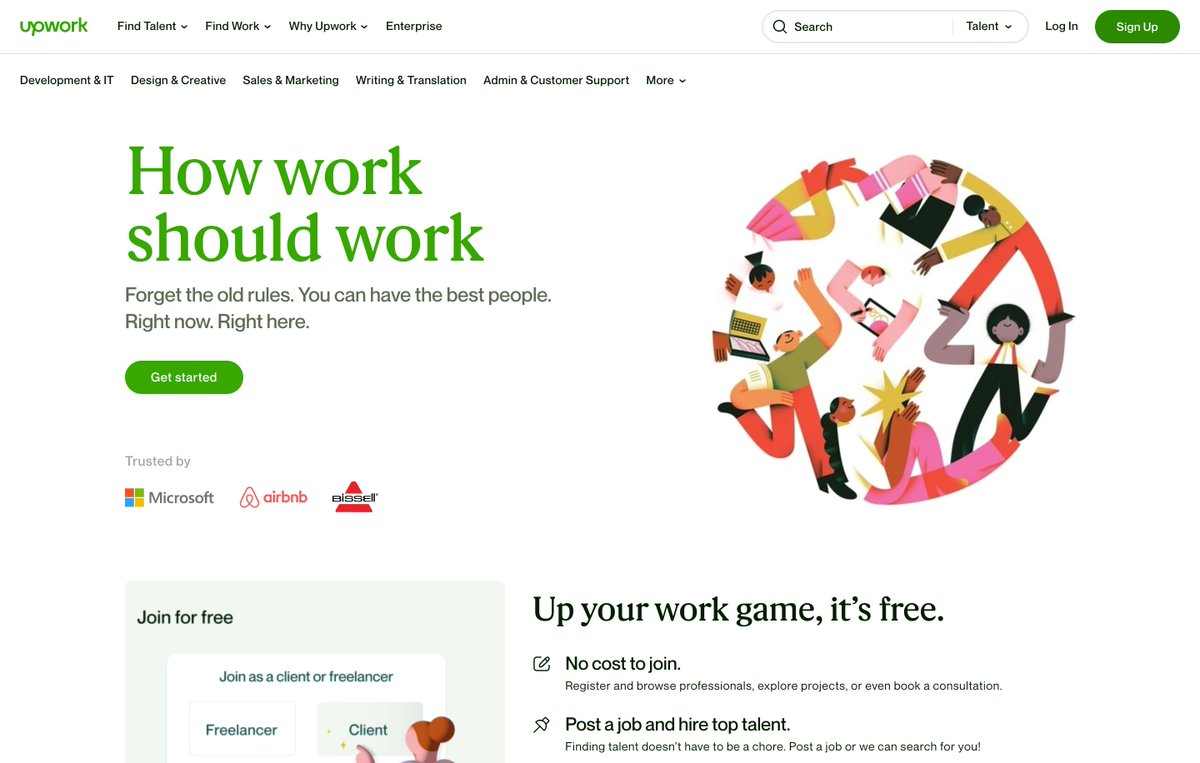
14. Upwork
Upwork has a more diverse category of talents, projects, and free membership.
Trusted by 100+ companies around the world.
Check out 👇
upwork.com
Upwork has a more diverse category of talents, projects, and free membership.
Trusted by 100+ companies around the world.
Check out 👇
upwork.com
16. Freelancer
Freelancer is for beginners to get work.
Web Design, graphic design, and other fields like writing jobs are available on this platform.
Sign up and get started.
Check out 👇
freelancer.in
Freelancer is for beginners to get work.
Web Design, graphic design, and other fields like writing jobs are available on this platform.
Sign up and get started.
Check out 👇
freelancer.in

17. Indeed
Indeed is the best platform to find remote jobs in my opinion.
You can find work and apply with the indeed best functional system of auto apply.
Check out 👇
in.indeed.com
Indeed is the best platform to find remote jobs in my opinion.
You can find work and apply with the indeed best functional system of auto apply.
Check out 👇
in.indeed.com

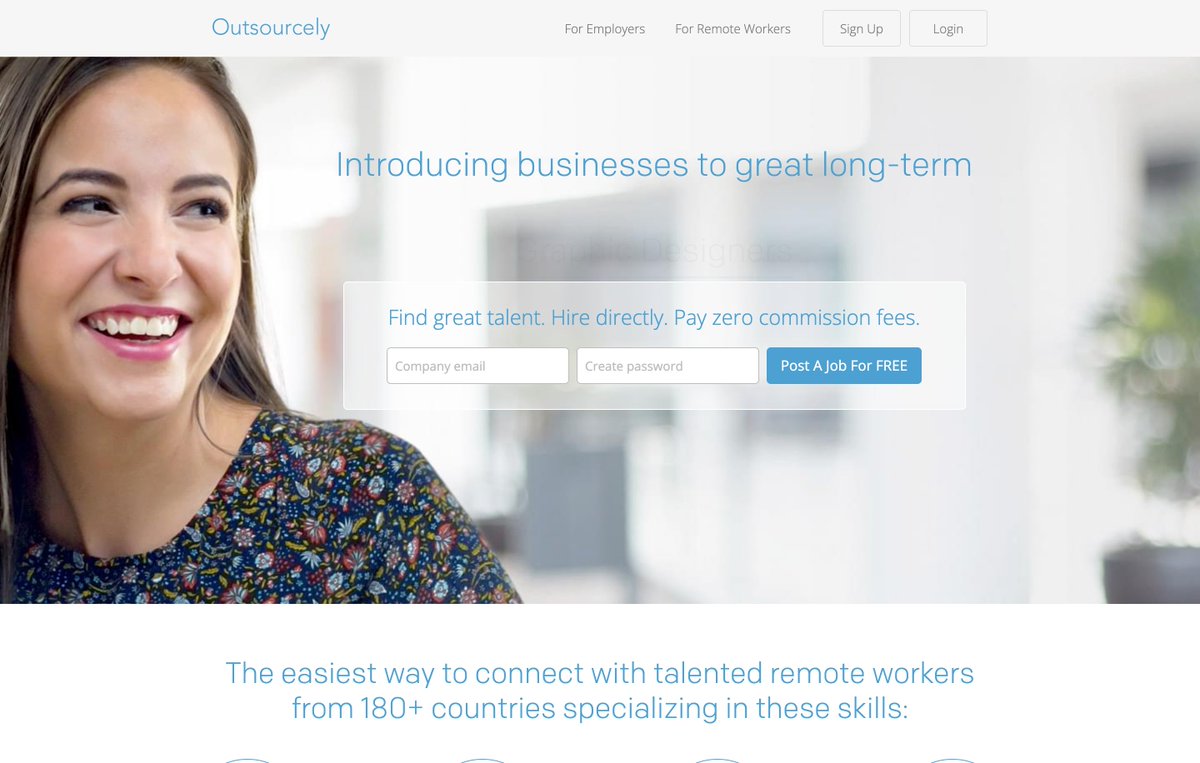
18. Outsourcely
On Outsourcely, you can find part-time and full-time jobs.
Find jobs for web development, designing, and more Content writing easily.
Check out 👇
outsourcely.com
On Outsourcely, you can find part-time and full-time jobs.
Find jobs for web development, designing, and more Content writing easily.
Check out 👇
outsourcely.com
19. Problogger
This website is for ghostwriters, bloggers and content writers.
Get remote work by sign up and apply with your portfolio.
Check out 👇
problogger.com
This website is for ghostwriters, bloggers and content writers.
Get remote work by sign up and apply with your portfolio.
Check out 👇
problogger.com

20. LinkedIn
Yes, you can also find remote jobs on LinkedIn.
The LinkedIn job section is so amazing.
You can find jobs related to your current skill in top tier companies.
Check out 👇
linkedin.com
Yes, you can also find remote jobs on LinkedIn.
The LinkedIn job section is so amazing.
You can find jobs related to your current skill in top tier companies.
Check out 👇
linkedin.com

Bonus:
Susbscribe to my Weekly Newsletter.
Join us for insights on Tech, AI, No Code, and Side Hustles.
theprohuman.ai/subscribe
Susbscribe to my Weekly Newsletter.
Join us for insights on Tech, AI, No Code, and Side Hustles.
theprohuman.ai/subscribe
That's a wrap!
If you enjoyed this thread:
1. Follow me @hasantoxr for more of these
2. Like and RT the tweet below to share this thread with your audience.
If you enjoyed this thread:
1. Follow me @hasantoxr for more of these
2. Like and RT the tweet below to share this thread with your audience.
https://twitter.com/hasantoxr/status/1702926705139331236
• • •
Missing some Tweet in this thread? You can try to
force a refresh