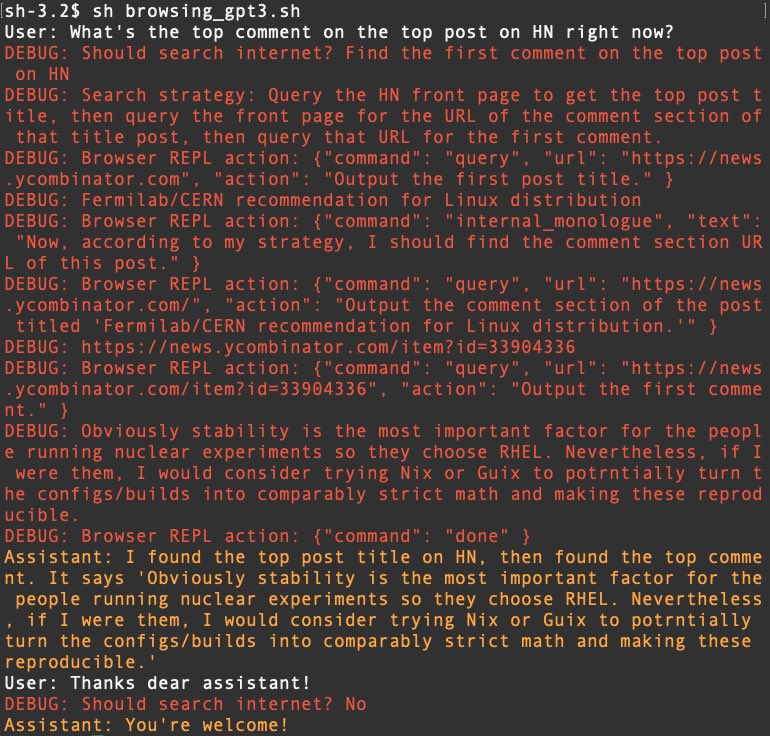
The new GPT model, gpt-3.5-turbo-instruct, can play chess around 1800 Elo.
I had previously reported that GPT cannot play chess, but it appears this was just the RLHF'd chat models. The pure completion model succeeds.
See game & thoughts below:

I had previously reported that GPT cannot play chess, but it appears this was just the RLHF'd chat models. The pure completion model succeeds.
See game & thoughts below:
https://twitter.com/GrantSlatton/status/1699441158450270472
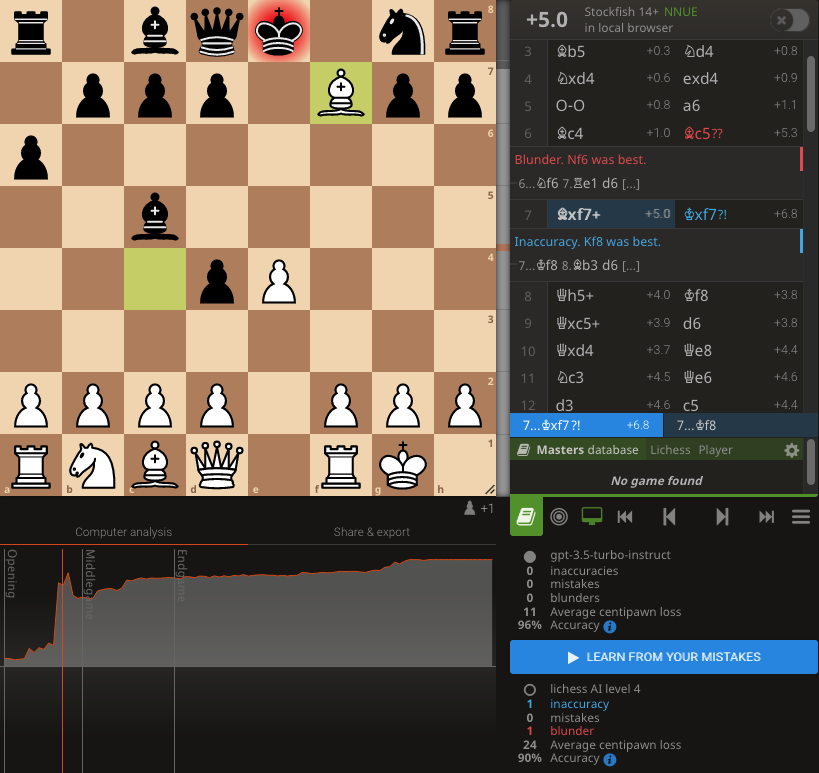
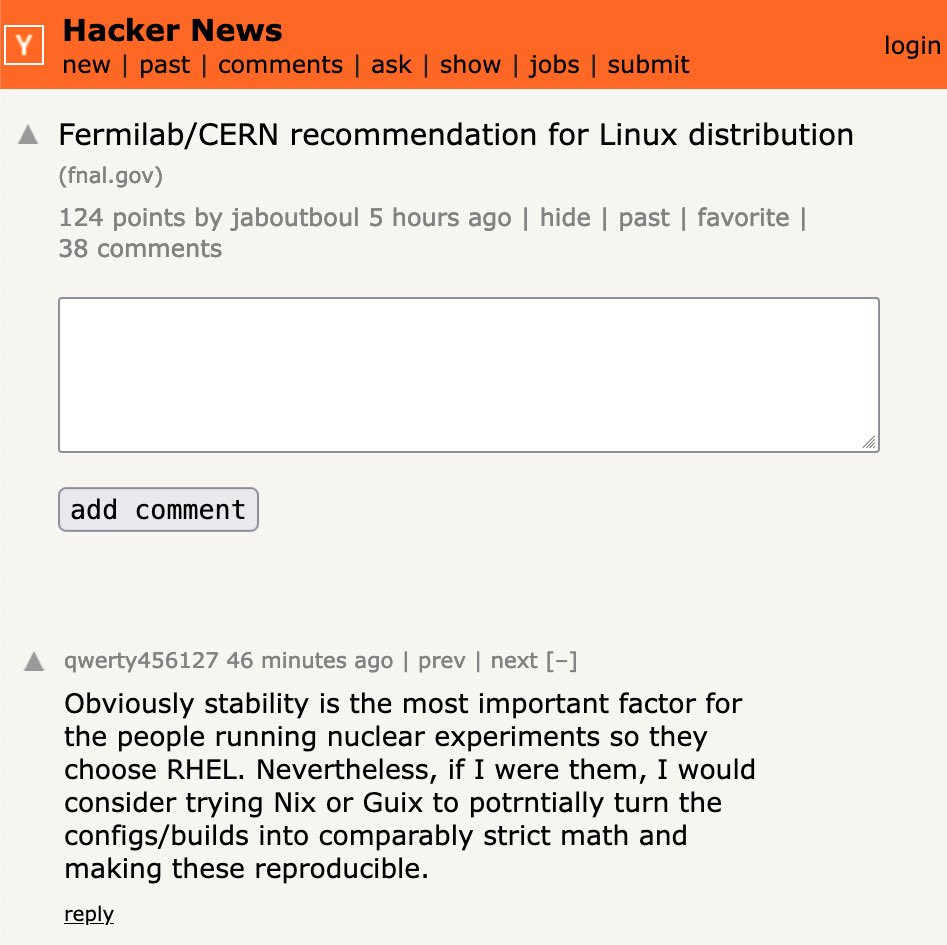
The new model readily beats Stockfish Level 4 (1700) and still loses respectably to Level 5 (2000). Never attempted illegal moves. Used clever opening sacrifice, and incredibly cheeky pawn & king checkmate, allowing the opponent to uselessly promote.
lichess.org/K6Q0Lqda
lichess.org/K6Q0Lqda


I used this PGN style prompt to mimic a grandmaster game.
The highlighting is a bit wrong. GPT made all its own moves, I input Stockfish moves manually.
h/t to @zswitten for this prompt style
The highlighting is a bit wrong. GPT made all its own moves, I input Stockfish moves manually.
h/t to @zswitten for this prompt style
https://twitter.com/zswitten/status/1699447461448933563

In conclusion, I now totally believe @BorisMPower's claim about 1800 Elo for GPT4.
I think the RLHF'd chat models do not do this well, but the base/instruct models seem to do much better.
I think the RLHF'd chat models do not do this well, but the base/instruct models seem to do much better.
https://twitter.com/BorisMPower/status/1690050553525792768
@BorisMPower Interestingly, in the games it lost again higher rated Stockfish bots, even after GPT made a bad move, it was still able to *predict* Stockfish's move that takes advantage of GPT's blunder. So you could probably get a >2000 Elo GPT by strapping on a tiny bit of search.
@wowAwesomeness @gigafestyu I’m sure the training data contains millions of games in this format, but never this exact game (it diverges from all known games at move 6). So this shows that GPT has learned how to play chess decently purely from reading millions of example games.
@BorisMPower Fast reproduction:
https://twitter.com/jordancurve/status/1703944421094674638
• • •
Missing some Tweet in this thread? You can try to
force a refresh