
Everyone should learn how to fine-tune LLMs.
However, LLMs barely fit in GPU memory❗️
This is where fine-tuning & more importantly parameter efficient fine-tuning (PEFT) become essential.
Let's understand them today:
However, LLMs barely fit in GPU memory❗️
This is where fine-tuning & more importantly parameter efficient fine-tuning (PEFT) become essential.
Let's understand them today:

GPT-4 is not a silver bullet solution.
We often need to teach an LLM or fine-tune it to perform specific tasks based on our custom knowledge base.
Read more:
Here's an illustration of different fine-tuning strategies! 👇 lightning.ai/pages/communit…
We often need to teach an LLM or fine-tune it to perform specific tasks based on our custom knowledge base.
Read more:
Here's an illustration of different fine-tuning strategies! 👇 lightning.ai/pages/communit…

We know LLMs today barely fit in GPU memory!
And say we want to update all the layers (Fine tuining II) as it gives best performance.
This is were we need to think of some Parameter efficient technique!
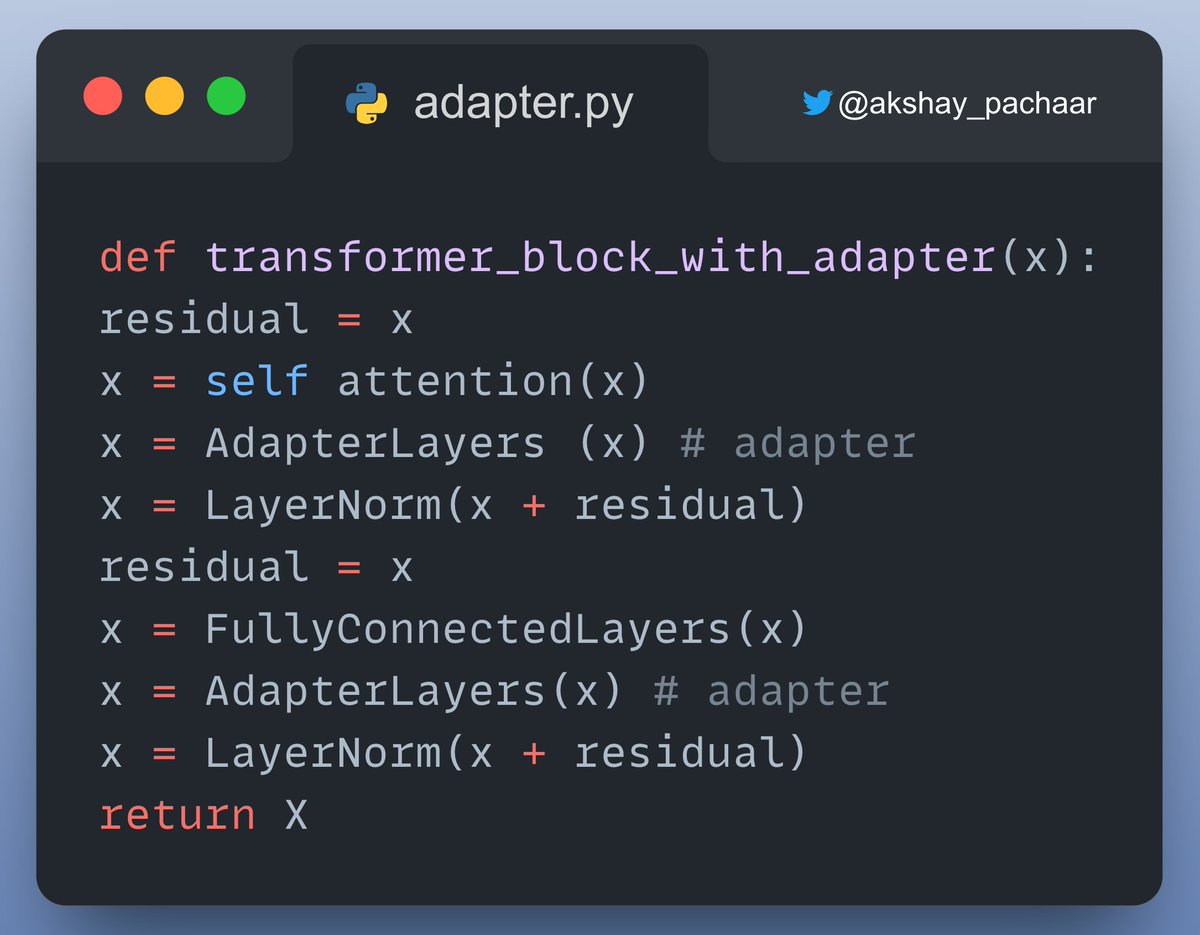
One such way is to use Transformer block with adapters!
Check this out👇
And say we want to update all the layers (Fine tuining II) as it gives best performance.
This is were we need to think of some Parameter efficient technique!
One such way is to use Transformer block with adapters!
Check this out👇

Here's how you can implement a transformer block with trainable Adapters!
Check this out👇
Check this out👇
LLaMA-Adapter: Prefix tuning + Adapter
This is another effective & popular PEFT technique!
LLaMA-Adapter method prepends tuneable prompt tensors to the embedded inputs.
Read more:
lightning.ai/pages/communit…
This is another effective & popular PEFT technique!
LLaMA-Adapter method prepends tuneable prompt tensors to the embedded inputs.
Read more:
lightning.ai/pages/communit…
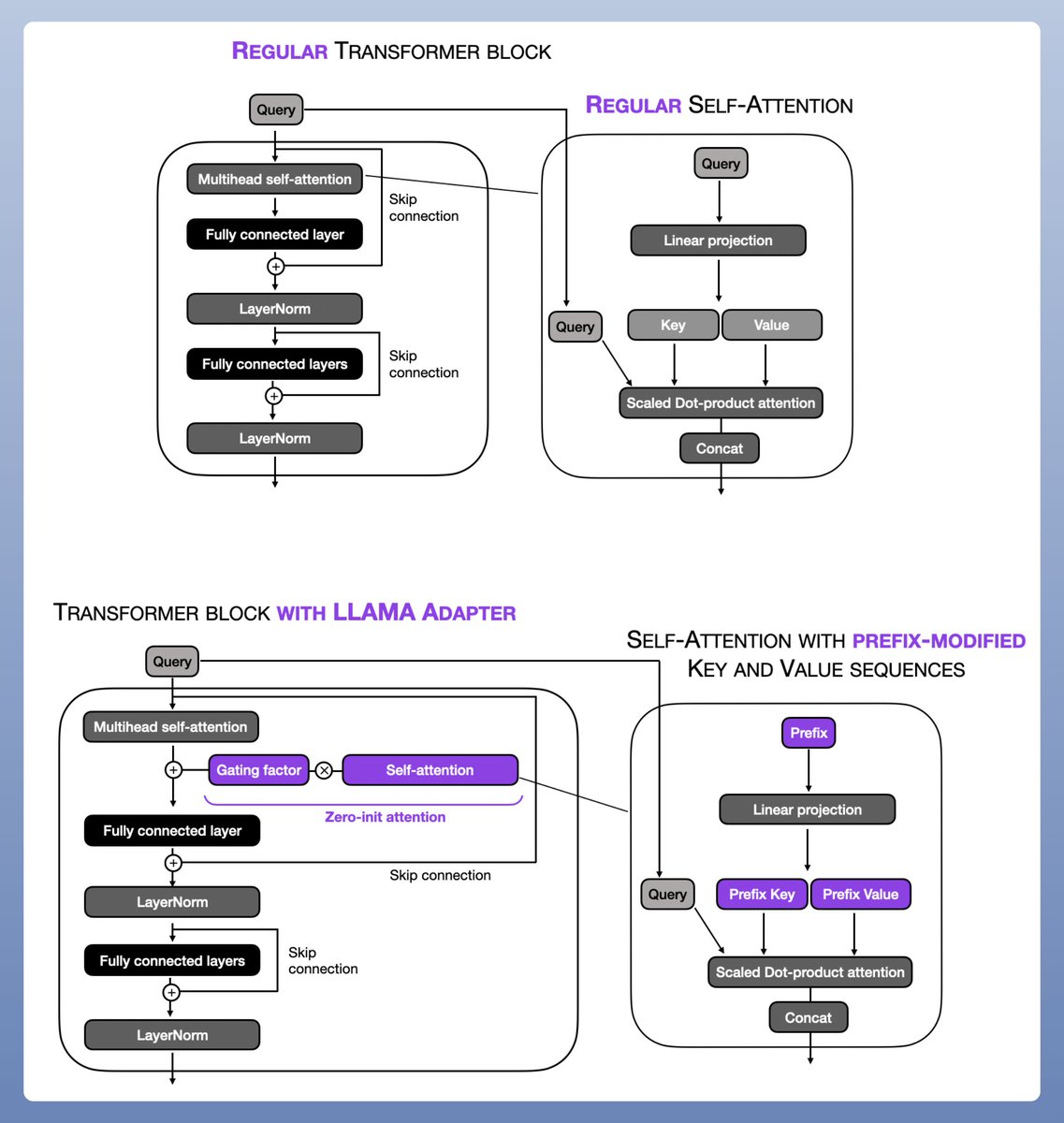
Here's how you can implement a LLaMa Adapter in code!
Check this out👇
Check this out👇

In short, PEFT enable you to get performance comparable to full fine-tuning while only having a small number of trainable parameters.
@LightningAI has some of the best resources on Fine-tuining LLMs and more!
You can read it all for FREE here👇
lightning.ai/pages/communit…
@LightningAI has some of the best resources on Fine-tuining LLMs and more!
You can read it all for FREE here👇
lightning.ai/pages/communit…
That's a wrap!
If you interested in:
- Python 🐍
- ML/MLOps 🛠
- CV/NLP 🗣
- LLMs 🧠
- AI Engineering ⚙️
Find me → @akshay_pachaar ✔️
Everyday, I share tutorials on the above topics!
Cheers!! 🙂
If you interested in:
- Python 🐍
- ML/MLOps 🛠
- CV/NLP 🗣
- LLMs 🧠
- AI Engineering ⚙️
Find me → @akshay_pachaar ✔️
Everyday, I share tutorials on the above topics!
Cheers!! 🙂
• • •
Missing some Tweet in this thread? You can try to
force a refresh





