
The fact that most individual neurons are uninterpretable presents a serious roadblock to a mechanistic understanding of language models. We demonstrate a method for decomposing groups of neurons into interpretable features with the potential to move past that roadblock.
We hope this will eventually enable us to diagnose failure modes, design fixes, and certify that models are safe for adoption by enterprises and society. It's much easier to tell if something is safe if you can understand how it works!
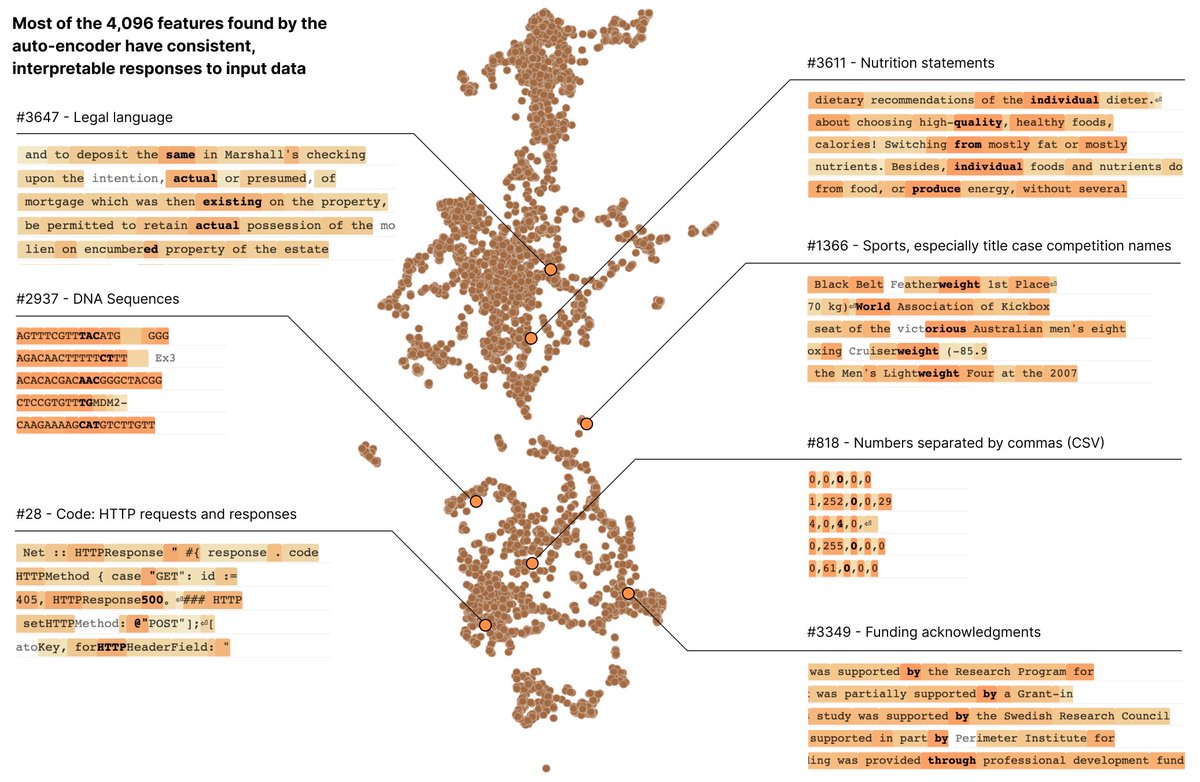
Most neurons in language models are "polysemantic" – they respond to multiple unrelated things. For example, one neuron in a small language model activates strongly on academic citations, English dialogue, HTTP requests, Korean text, and others. 

Last year, we conjectured that polysemanticity is caused by "superposition" – models compressing many rare concepts into a small number of neurons. We also conjectured that "dictionary learning" might be able to undo superposition.
x.com/AnthropicAI/st…
x.com/AnthropicAI/st…
Dictionary learning works! Using a "sparse autoencoder", we can extract features that represent purer concepts than neurons do. For example, turning ~500 neurons into ~4000 features uncovers things like DNA sequences, HTTP requests, and legal text.
📄 transformer-circuits.pub/2023/monoseman…
📄 transformer-circuits.pub/2023/monoseman…
Artificially stimulating a feature steers the model's outputs in the expected way; turning on the DNA feature makes the model output DNA, turning on the Arabic script feature makes the model output Arabic script, etc.
📄 transformer-circuits.pub/2023/monoseman…
📄 transformer-circuits.pub/2023/monoseman…

Features connect in "finite-state automata"-like systems that implement complex behaviors. For example, we find features that work together to generate valid HTML.
📄 transformer-circuits.pub/2023/monoseman…
📄 transformer-circuits.pub/2023/monoseman…

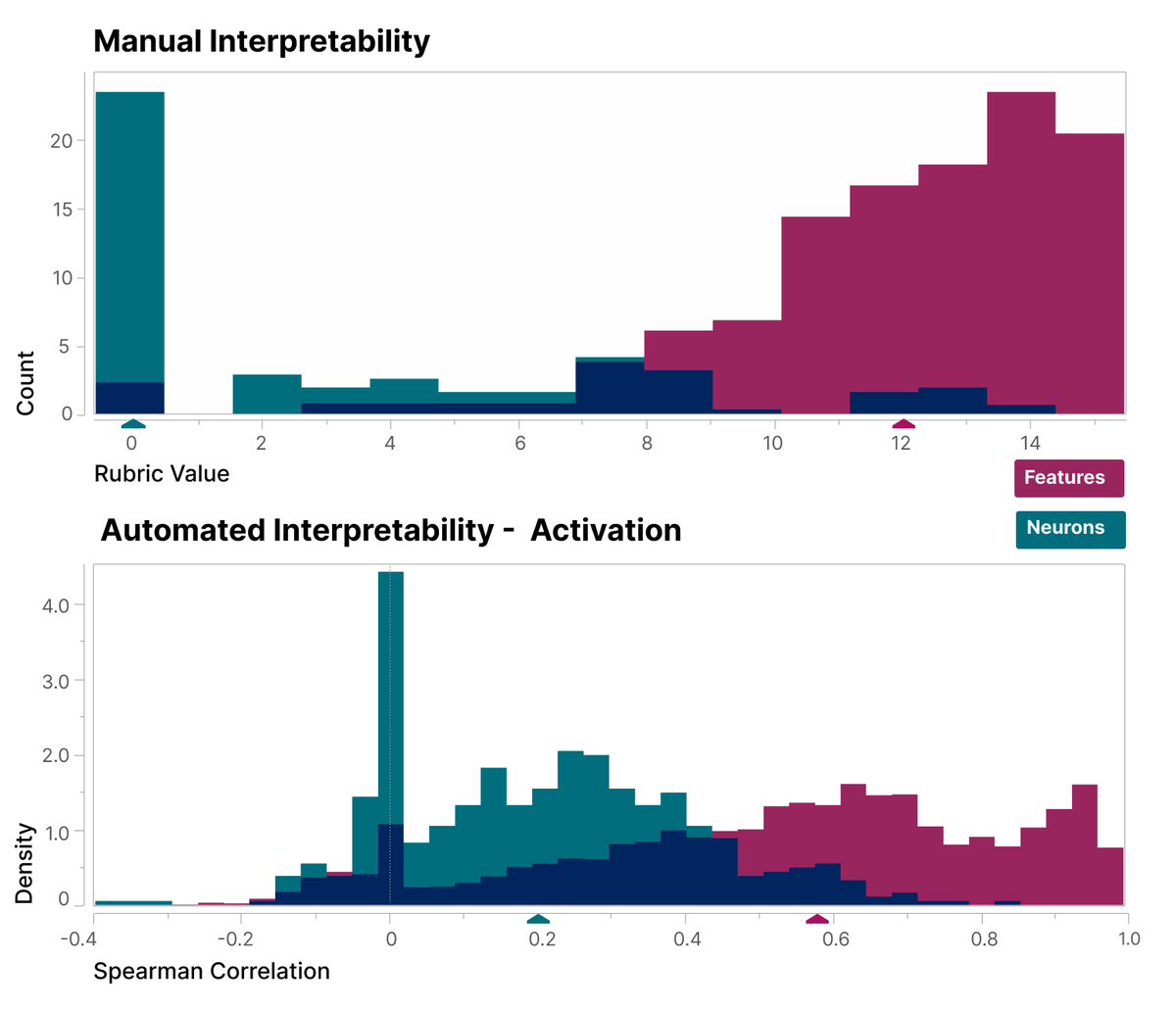
We also systematically show that the features we find are more interpretable than the neurons, using both a blinded human evaluator and a large language model (autointerpretability).
📄 transformer-circuits.pub/2023/monoseman…
📄 transformer-circuits.pub/2023/monoseman…
Our research builds on work on sparse coding and distributed representations in neuroscience, disentanglement and dictionary learning in machine learning, and compressed sensing in mathematics.
There's a lot more in the paper if you're interested, including universality, "feature splitting", more evidence for the superposition hypothesis, and tips for training a sparse autoencoder to better understand your own network!
📄transformer-circuits.pub/2023/monoseman…
📄transformer-circuits.pub/2023/monoseman…
If this work excites you, our interpretability team is hiring! See our job descriptions below.
Research Scientist, Interpretability:
Research Engineer, Interpretability: jobs.lever.co/Anthropic/33dc…
jobs.lever.co/Anthropic/3dbd…
Research Scientist, Interpretability:
Research Engineer, Interpretability: jobs.lever.co/Anthropic/33dc…
jobs.lever.co/Anthropic/3dbd…
• • •
Missing some Tweet in this thread? You can try to
force a refresh









