
The wait is over! With 60M+ minutes transcribed, our next-gen speech-to-text model Nova-2 is now available.
What's new?
✅ Expanded languages: Spanish, Hindi, German, French, Portuguese
✅ Custom model training
✅ On-prem deployment
Let's dive in...🧵 dpgr.am/9f52615
What's new?
✅ Expanded languages: Spanish, Hindi, German, French, Portuguese
✅ Custom model training
✅ On-prem deployment
Let's dive in...🧵 dpgr.am/9f52615
In our early access release, Nova-2 impressed developers with its unmatched performance and value compared to competitors.
✅ An average 30% reduction in word error rate (WER)
✅ 5-40x faster speed
✅ 3-5x lower costs
✅ Full feature set: diarization, smart formatting, and more
✅ An average 30% reduction in word error rate (WER)
✅ 5-40x faster speed
✅ 3-5x lower costs
✅ Full feature set: diarization, smart formatting, and more
Since then, thousands of projects have been developed across diverse use cases from autonomous AI agents and coaching bots to call center analytics and conversational AI platforms, transcribing more than 60 million audio minutes in a little more than a month.
Regarding benchmarking, the results center on industry-standard accuracy metrics for #STT like word error rate (WER) and word recognition rate (WRR).
But many research topics in #NLP require evaluation that goes beyond standard metrics, towards a more human-centered approach.
But many research topics in #NLP require evaluation that goes beyond standard metrics, towards a more human-centered approach.
For evaluating #LLM-powered speech generation systems, human preference scoring is often considered one of the most reliable approaches in spite of its high costs compared to automated evaluation methods.
To this end, we conducted human preference testing using outside professional annotators who examined a set of 50 unique transcripts produced by Nova-2 and 3 other providers, evaluated in randomized head-to-head comparisons (totaling 300 unique transcription preference matchups).
They were then asked to listen to the audio and give their preference of formatted transcripts based on an open-ended criterion. 
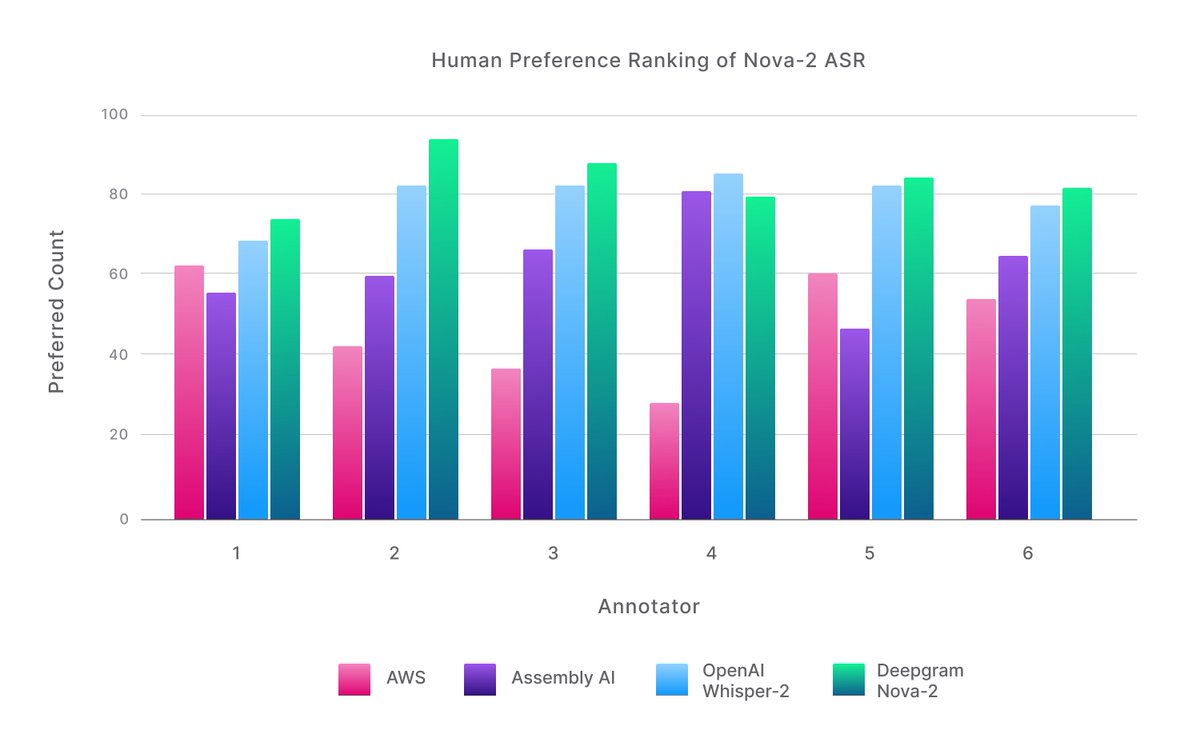
In head-to-head comparisons, Nova-2 transcripts were preferred ~60% of the time, and 5/6 annotators preferred formatted Nova-2 results more than any other vendor. Nova-2 had the highest overall win rate at 42%, which is a 34% higher win rate than the next-best OpenAI Whisper[2].

We conducted benchmarks against OpenAI’s recently released #WhisperV3, but were a bit perplexed by the results as we frequently encountered significant repetitive hallucinations in a sizable portion of our test files.
The result was a much higher WER and wider variance for OpenAI’s latest model than expected.
We are actively investigating how to better tune Whisper-v3 in order to conduct a fair and comprehensive comparison with Nova-2.
(Stay tuned, and we will share the results soon).
We are actively investigating how to better tune Whisper-v3 in order to conduct a fair and comprehensive comparison with Nova-2.
(Stay tuned, and we will share the results soon).
Our benchmarking methodology for non-English languages with Nova-2 utilized 50+ hours of high quality, human-annotated audio, encompassing a wide range of audio lengths, varying environments, diverse accents, and subjects across many domains.
We transcribed these data sets with Nova-2 and some of the most prominent STT models in the market for leading non-English languages.
Nova-2 outperforms all tested competitors by an average of 30.3%.
Significant performance:
➡️ Hindi (41% relative WER improvement)
➡️ Spanish (15% relative WER improvement)
➡️ German (27% relative WER improvement)
➡️ 34% relative WER improvement vs. Whisper large-V2.
Significant performance:
➡️ Hindi (41% relative WER improvement)
➡️ Spanish (15% relative WER improvement)
➡️ German (27% relative WER improvement)
➡️ 34% relative WER improvement vs. Whisper large-V2.

Nova-2 not only outperforms rivals in accuracy but also shows less variation in results, leading to more reliable transcripts across diverse languages in practical applications.

Nova-2 beats the competition for non-English streaming by more than 2% in absolute WER over all languages combined with a 23% relative WER improvement on average (and 11% relative WER improvement over the next best alternative, Azure), as shown below.

Nova-2 stands out for its speed and accuracy, but also continues the legacy of its predecessor by being the most cost-effective speech-to-text model on the market.
Priced competitively at just $0.0043 per minute for pre-recorded audio, Nova-2 is 3-5x more affordable.
Priced competitively at just $0.0043 per minute for pre-recorded audio, Nova-2 is 3-5x more affordable.

As the #AI market has come to recognize, customization can be vital for making AI models work for your use case. Deepgram customers can now have a custom-trained model created for them using the best foundation available–Nova-2.
Deepgram can also provide data labeling services, and even create audio to train on to ensure your custom models produce the best results possible, giving you a boost in performance atop Nova-2’s already impressive, out-of-the-box capabilities.
Dive into the details of this latest release, our approach to benchmarking, and more in the full announcement.
We can't wait to see what you build with Nova-2! Be sure to share your projects with us by mentioning us here.
Happy building!
We can't wait to see what you build with Nova-2! Be sure to share your projects with us by mentioning us here.
Happy building!
• • •
Missing some Tweet in this thread? You can try to
force a refresh



